一、Pandas库概述
1.1 Pandas库简介
Pandas 是经过BSD许可的开源的 Python 数据分析支持库,它是Python编程语言的一个第三方库,为Python编程语言提供了高性能。Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
Pandas提供了快速、灵活和表达力强的数据结构,旨在简单、直观地处理关系型、标记型数据。并且它是基于NumPy开发,可以与其它第三方科学计算支持库完美集成。
Pandas专门设计用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
Pandas 基于 NumPy 开发,可以与其它第三方科学计算支持库完美集成。
Pandas有三种常用的数据结构: Series(一维数据)、DataFrame(二维数据)和 Panel(三维数据)
Python 原生数组、Numpy 数组对象 和 Pandas 数组对象 对比:
- Python
- list:Python自带数据类型,主要用一维,功能简单,效率低
- Dict:Python自带数据类型,多维键值对,效率低
- Numpy
- ndarray:Numpy基础数据类型,单一数据类型
- 关注数据结构/运算/维度(数据间关系)
- Pandas
- Series:1维,类似带索引的1维ndarray
- DataFrame:2维,表格型数据类型,类似带行/列索引的2维ndarray 关注数据与索引的关系(数据实际应用)
从实用性、功能强弱和和可操作性比较:list < ndarray < Series/DataFrame。
理解这些数据结构的最佳方法是高维数据结构是其低维数据结构的容器。例如,DataFrame 是 Series 的容器,Panel 是 DataFrame 的容器。
| 名称 | 维数 | 描述 |
|---|---|---|
| Series | 1维 | 带标签(索引)的一维(一般数据类型相同)数组 |
| DataFrame | 2维 | 带标签(索引)的,大小可变的,二维异构表格 |
| Panel | 3维 | 通用的3D标签,大小可变的数组 |
Pandas 数据结构就像是低维数据的容器。可以这样理解,DataFrame 是 Series 的容器,Series 则是标量的容器。因此,可以在容器中以字典的形式插入或删除对象。
建立和处理二维数组是一项繁琐的工作,在编写函数时,要由用户来考虑数据集的方向。但是使用Pandas数据结构可以减少用户的精力。
例如,对于表格数据(DataFrame),在语义上考虑索引(行)和列比在轴0和轴1上更有帮助。
1.2 Pandas能做什么
- 数据读取:从CSV、Excel、SQL等多种数据源读取数据。
- 数据清洗:处理缺失值、去除重复数据、数据类型转换等。
- 数据探索:提供描述性统计、数据过滤、分组等操作。
- 数据可视化:与Matplotlib、Seaborn等库结合,绘制各种图表。
- 时间序列分析:提供了丰富的时间序列功能,包括时间戳、频率转换、移动窗口统计等。
Pandas的部分优势 :
- 处理浮点与非浮点数据里的缺失数据,表示为 NaN;
- 大小可变:插入或删除 DataFrame 等多维对象的列;
- 自动、显式数据对齐:显式地将对象与一组标签对齐,也可以忽略标签,在 Series、DataFrame 计算时自动与数据对齐;
- 强大、灵活的分组(group by)功能:拆分-应用-组合数据集,聚合、转换数据;
- 把 Python 和 NumPy 数据结构里不规则、不同索引的数据轻松地转换为 DataFrame 对象;
- 基于智能标签,对大型数据集进行切片、花式索引、子集分解等操作;
- 直观地合并(merge)、**连接(join)**数据集;
- 灵活地重塑(reshape)、**透视(pivot)**数据集;
- 轴支持结构化标签:一个刻度支持多个标签;
- 成熟的 IO 工具:读取文本文件(CSV 等支持分隔符的文件)、Excel 文件、数据库等来源的数据,利用超快的 HDF5 格式保存 / 加载数据;
- 时间序列:支持日期范围生成、频率转换、移动窗口统计、移动窗口线性回归、日期位移等时间序列功能。
简而言之,Pandas是一个多用途的数据分析工具,它几乎可以处理任何与数据相关的任务,从数据的导入、处理到分析和可视化。
1.3 Pandas 对象的变异性
所有Pandas数据结构都是值可变的(可以更改),除了Series以外,其它大小都是可变的。系列是大小不变的。
二、Pandas库核心数据结构 之 Series
2.1 Series 数据结构概述
Series 是 Pandas 中最基本的数据结构,它是一种类似于一维数组的对象,由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成:
- values:一组同构(数据类型相同)数组(ndarray类型),数组元素类型可以是任何数据类型(整数、字符串、浮点数、Python对象等)。
- index:相关的数据索引标签。每个元素都有一个索引标签,这使得 Series 非常适合用于表示具有明确标签的数据。
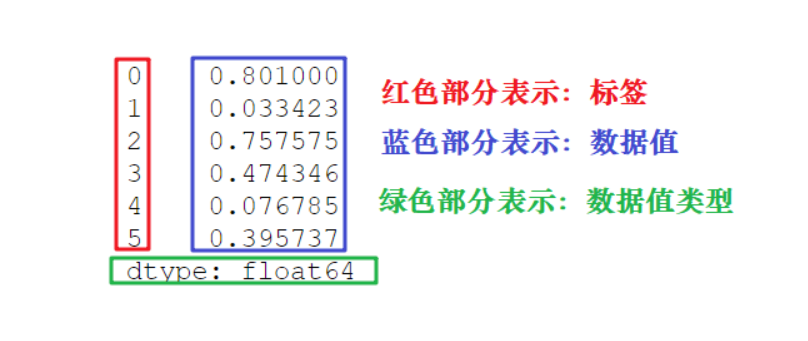
Series的特点:
- 一维数组:Series是一维的,这意味着它只有一个轴(或维度),类似于 Python 中的列表。
- 索引: 每个 Series 都有一个索引,索引可以是整数、字符串、日期等类型。如果不指定索引,Pandas 将默认创建一个从 0 开始的连续整数索引。
- 数据类型: Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。
- 大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
- 操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
- 缺失数据:Series 可以包含缺失数据,Pandas 使用 NaN(Not a Number)来表示缺失或无值。
2.2 创建 Series
使用 pd.Series() 构造函数创建一个 Series 对象,传递一个数据数组(可以是列表、NumPy 数组等)和一个可选的索引数组。
|
|
参数说明:
data:Series 的数据部分,可以是 标量值、元组、列表、数组、字典、ndarray等。如果不提供此参数,则创建一个空的 Series。index:Series 的数据索引标签。索引值必须是唯一且可哈希的,且长度与数据相同。如果不指定索引参数,创建的 Series 将自动添加默认从 0 开始的连续整数索引 —— np.arrange(n);如果指定索引参数的话,使用列表或者元组格式进行指定,其中列表或者元组的长度需要 和 data 的数据行数一致。索引列表的元素类型可以是 数值(连续整数 或 不连续整数都可以)、字符、字符串等数据类型。dtype:指定 Series 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。如果 data 中数据类型不同时 dtype 为 object 。name:Series 的名称,用于标识 Series 对象。如果提供了此参数,则创建的 Series 对象将具有指定的名称。copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。fastpath:是否启用快速路径。默认为 False。启用快速路径可能会在某些情况下提高性能。
1.创建一个空Series对象:
|
|
2.由列表创建Series, 默认索引为 0 到 N-1 的整数型索引:
|
|
3.由numpy对象创建Series, 默认索引为 0 到 N-1 的整数型索引:
|
|
4.利用 index 属性,在创建的时候指定索引:
|
|
2.3 Series的索引操作
Series 有两套索引:
- 隐式索引:为固定索引,是在创建 Series 时自动创建从 0 开始的连续递增整数索引,故称为 隐式索引,Series 使用
arr.iloc[num](如arr.iloc[0]——arr.iloc[len(arr)-1])进行隐式索引的操作; - 显示索引:为可选索引,是创建 Series 时使用 index 参数指定的索引,故称为 显示索引, index 索引参数可以是 整数、浮点数、字符、字符串、日期、等Python 值类型对象 组成的 列表、元组对象,通常索引的 数据类型全部相同,也可以不同。可以使用
arr[idx]和arr.loc[idx]对 Series 的显示索引进行索引操作,对应字符 或 字符串 类型的索引,也可以使arr.index_name方式 操作索引,如 索引为字符 ‘a’ 则 可以使用arr.a或 索引为字符串 “one” 则 可使用arr.one操作索引。
Tips: 当 显示索引也为 从 0 开始递增的整数 时, a[i] == a.loc[i] == a.iloc[i]
单索引操作:
|
|
三、Pandas库核心数据结构 之 DataFrames
3.1 DataFrames 数据结构概述
DataFrame 是具有异构数据的二维数组,即,数据以表格形式在行和列中对齐。例如,
| Name | Age | Gender | Rating |
|---|---|---|---|
| Steve | 32 | Male | 3.45 |
| Lia | 28 | Female | 4.6 |
| Vin | 45 | Male | 3.9 |
| Katie | 38 | Female | 2.78 |
上表代表组织的销售团队的数据及其总体绩效等级,数据以行和列表示,每列代表一个属性,每行代表一个人。其中,列的数据类型:
- Name: String
- Age: Integer
- Gender: String
- Rating: Float
关键点 异构数据 大小不变 数据可变
四、Pandas库核心数据结构 之 Panel
4.1 Panel 数据结构概述
Panel 是具有异构数据的三维数据结构。很难用图形表示 Panel。但是 Panel 可以说明为 DataFrame 的容器。 关键点 异构数据 大小可变 数据可变
、统计函数
|
|