一、主从复制
1.1 主从复制的架构及作用
主从复制的基本架构如下图:
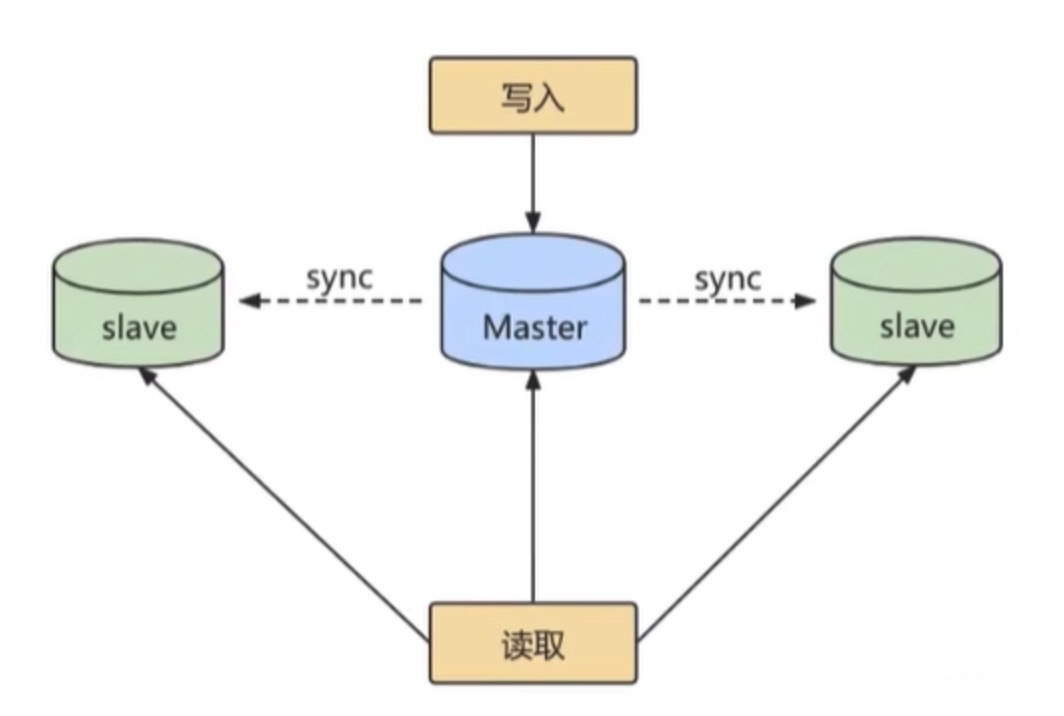
主从复制的作用:
1.2 主从复制的原理
MySQL主从同步的原理是基于 binlog 进行数据同步的。在主从复制过程中,会基于 3 个线程 来操作,一个主库线程,两个从库线程。
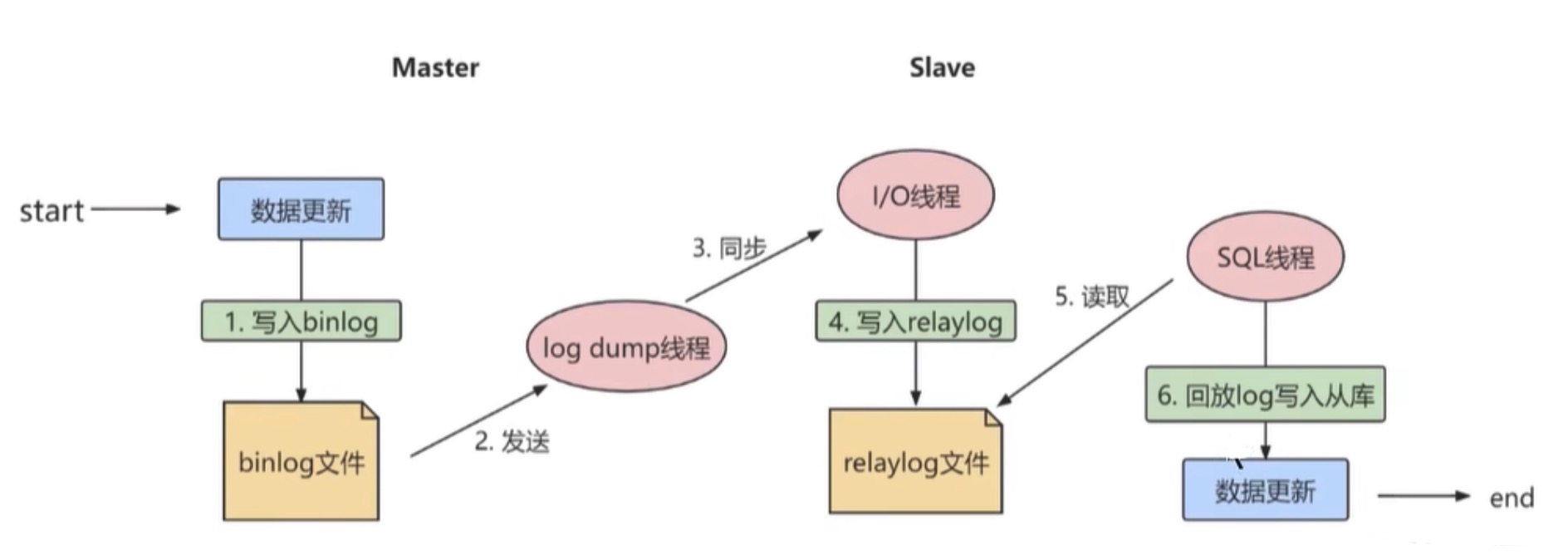
二进制日志转储线程(Binlog dump thread) 是一个主库线程。当从库线程连接master的时候,主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上加锁,读取完成之后,再将锁释放掉。
从库 I/O 线程 会连接到主库,向主库发送请求同步更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程 会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
注意:
- 不是所有版本的MySQL都默认开启服务器的二进制日志。在进行主从同步的时候,需要先检查服务器是否已经开启了耳机二进制文件。
- 除非特殊指定,默认情况下从服务器会执行所有主服务器中保存的事件。也可以通过配置,使从服务器执行特定的事件。
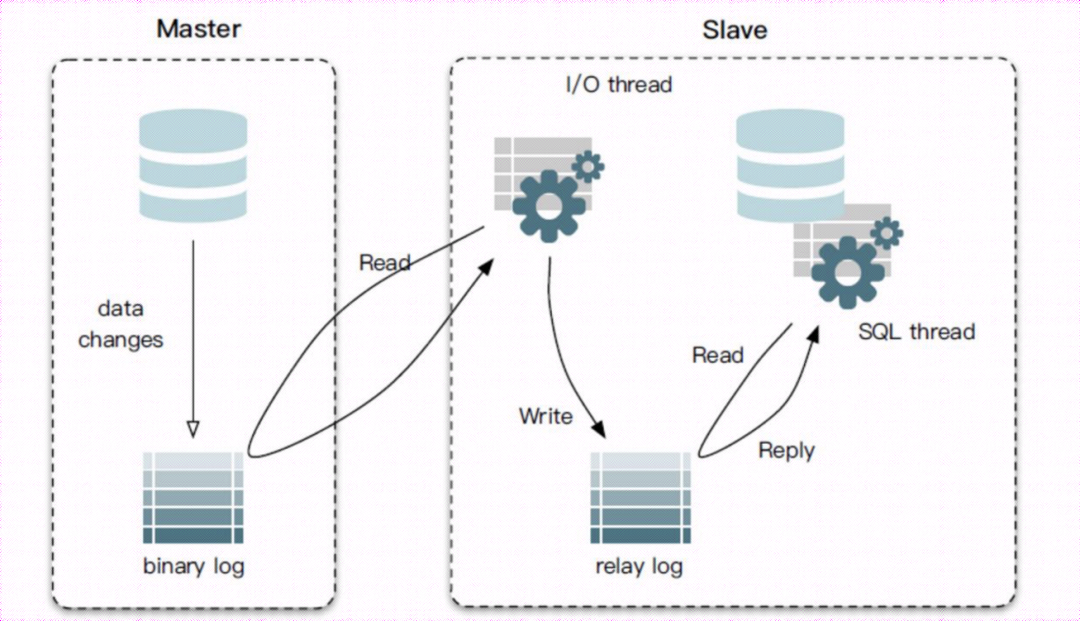
主从复制三步骤:
步骤1:Master将写(增、删、改等DML操作 及 DDL操作)操作记录到二进制日志(binlog);
步骤2:Slave将Master的binary log events拷贝到它的中继日志(relay log);
步骤3:Slave重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的,而且重启后从接入点开始复制。
主从复制的基本原则:
- 每个Slave只有一个Master;
- 每个Slave只能有一个唯一的服务器ID;
- 每个Master可以有多个Slave;
1.3 主从复制同步数据一致性问题
主从同步的要求:
- Slave库和Master库的数据一致(最终一致);
- 写数据必须写到Master库;
- 读数据可以一般到Slave库,也可以到Master库;
主从同步延迟问题:
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。
在网络正常的时候,日志从主库传给从库所需的时间是很短的。即,网络正常情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢,造成原因:
- 从库的机器性能比主库要差
- 从库的压力大
- 大事务的执行
若想要减少主从延迟的时间,可以采取下面的办法:
- 降低多线程大事务并发的概率,优化业务逻辑;
- 优化SQL,避免慢SQL,减少批量操作,建议写脚本以
update-sleep 这样的形式完成;
提高从库机器的配置,减少主库写binlog和从库读binlog的效率差;- 尽量采用
短的链路,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时;
- 实时性要求的业务读强制走主库,从库只做灾备,备份;
解决主从同步一致性问题:
读写分离情况下,解决主从同步中数据不一致的问题,就是解决主从之间 数据复制方式 的问题,如果按照数据一致性 从弱到强 来进行划分,有以下 3 种复制方式:
方式1:异步复制
异步模式 就是客户端提交commit之后,Master库不需要再等从库返回任何结果,而是直接将结果返回给客户端,这样做的好处是不会影响主库写的效率,但可能会存在主库宕机,而Binlog还没有同步到从库的情况,也就是此时的主库和从库数据不一致。
这时候从从库中选择一个作为新主,那么新主则可能缺少原来主服务器中已提交的事务。所以,异步复制这种复制模式下的数据一致性是最弱的。
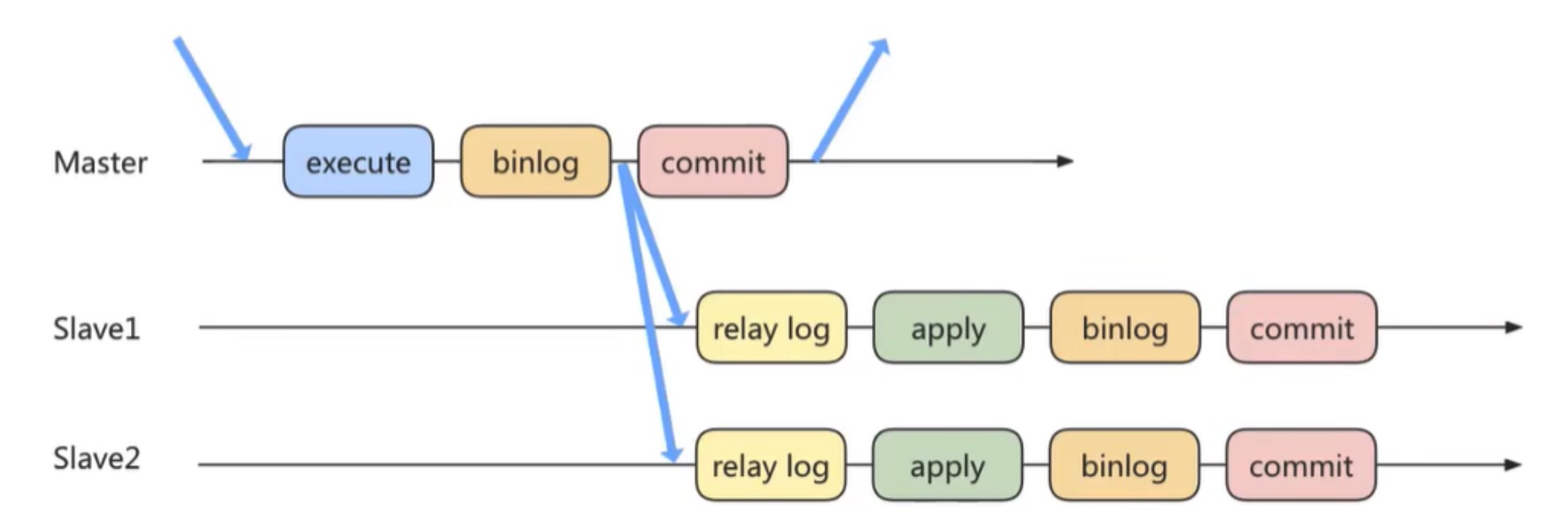
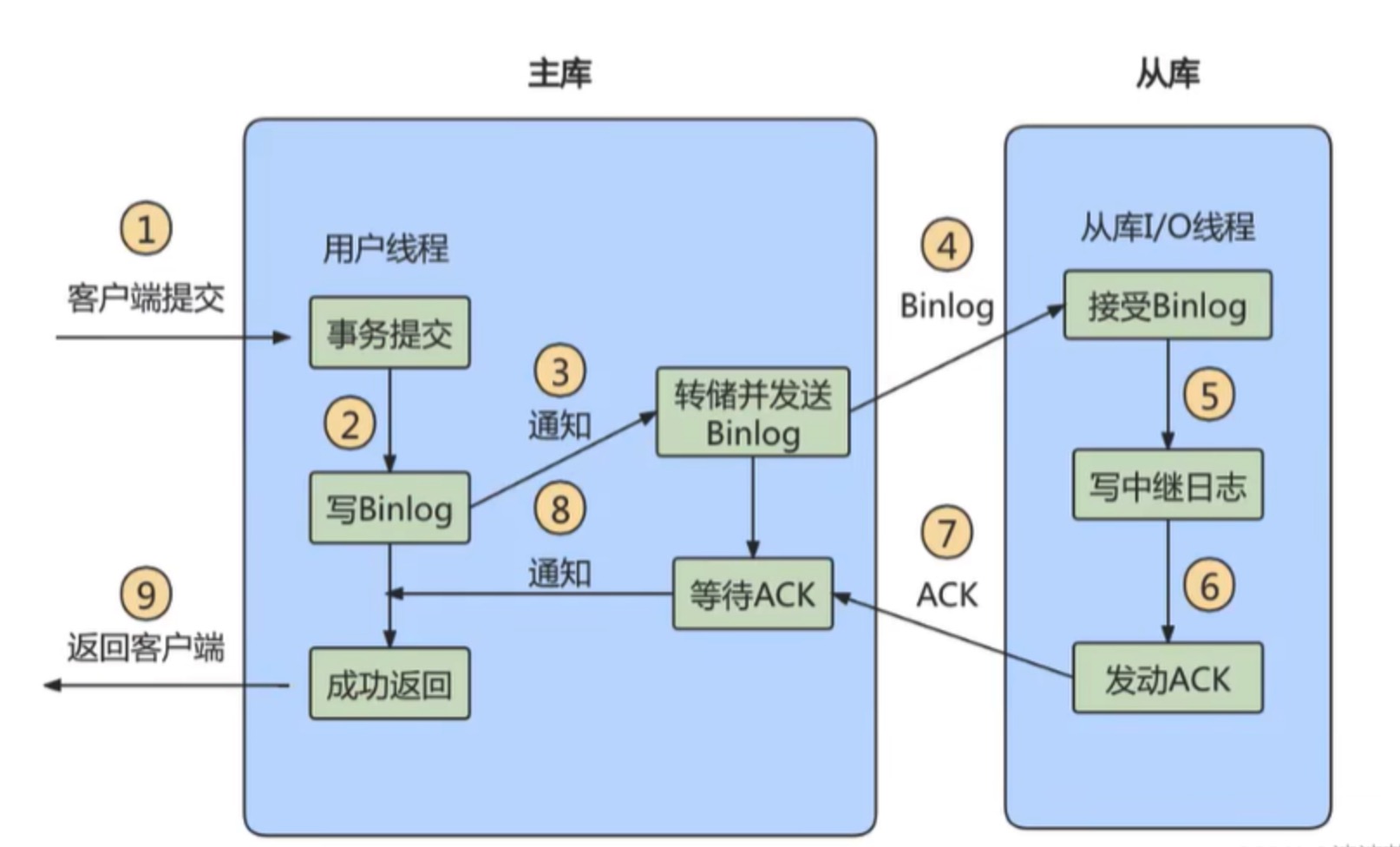
方式2:半同步复制
MySQL5.5版本之后开始支持半同步复制的方式。半同步复制的原理是在客户端提交COMMIT之后,Master不直接将结果返回给客户端,而是等待至少有一个从库接收到了Binlog,并且写入到中继日志中,再返回给客户端。
这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
在MySQL5.7版本中还增加了一个 rpl_semi_sync_master_wait.for_slave.count 参数,可以对应答的从库数量进行设置,默认为1,也就是说只要有1个从库进行了响应,就可以返回给客户端。如果将这个参数调大,可以提升数据一致性的强度,但也会增加主库等待从库响应的时间。
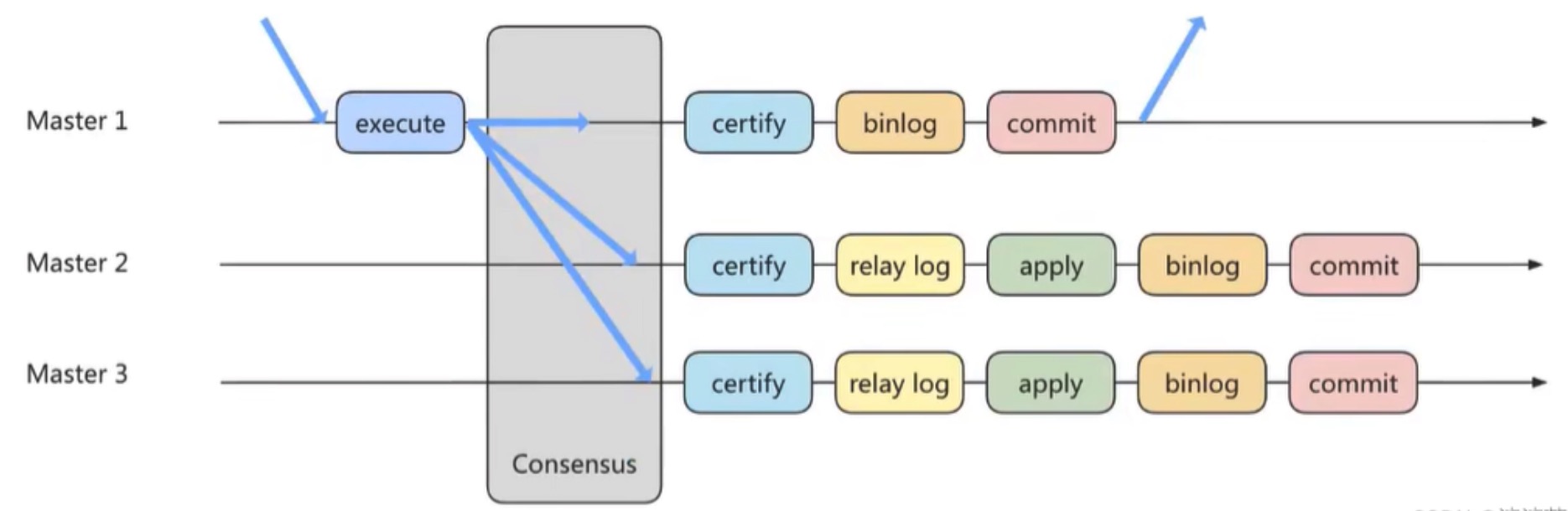
方式3:组复制
首先将多个节点共同组成一个复制组,在执行读写(RW)事务的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于(N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对只读(RO)事务则不需要经过组内同意,直接 COMMIT 即可。
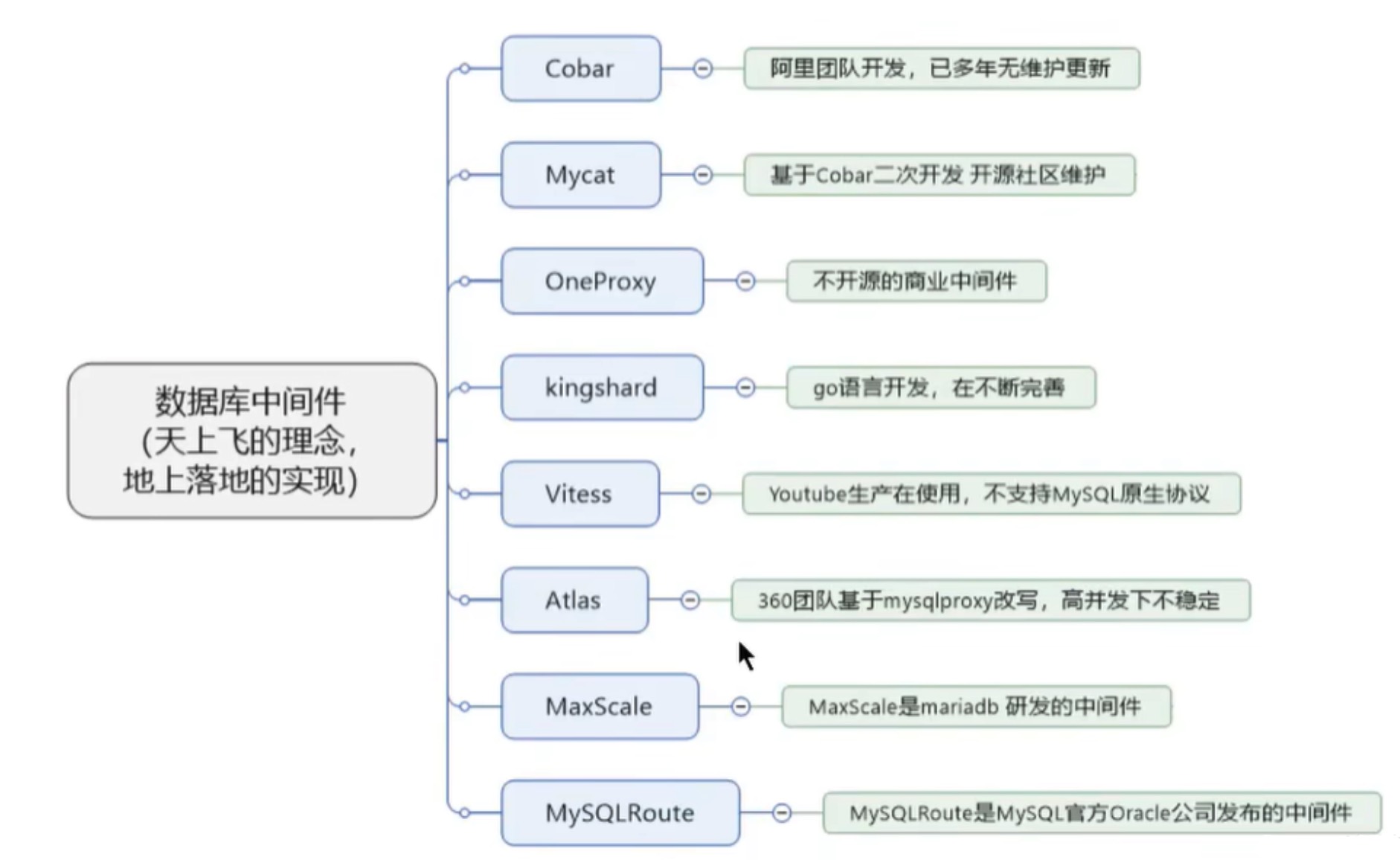
在主从架构的配置中,如果想要采取读写分离的策略,可以自己编写程序,也可以通过第三方的中间件来实现:
1.4 使用 docker compose 搭建 MySQL8.0 主从服务
1. 编写 master 服务 docker-compose.yml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# docker-compose.yml
services:
mysql:
image: mysql:8.0
network_mode: host # host 共享主机网络名称空间(等同于 docker run --net=host)
container_name: mysql
user: "1000:1000" # 根据需要修改 或 注释
environment:
MYSQL_ROOT_PASSWORD: password # 修改为自己的密码
MYSQL_REPLICATION_MODE: master # 这三个环境变量会自动配置主从同步的用户和权限
MYSQL_REPLICATION_USER: replication
MYSQL_REPLICATION_PASSWORD: password # 修改为自己的密码
command:
--server-id=100 # 根据需要修改,同一网络中唯一
--log-bin=binlog
--expire_logs_days=7
# ports: # 使用主机网络(host)空间 模式时,ports 配置失效,要修改 服务启动端口 可 配置 my.cnf文件
# - "3306:3306"
volumes:
- /data/mysql-master/volume:/var/lib/mysql
- /data/mysql-master/config:/etc/mysql/conf.d
restart: always
|
2. 编写 slave 服务 docker-compose.yml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
services:
mysql:
image: mysql:8.0
network_mode: host # host 共享主机网络名称空间(等同于 docker run --net=host)
container_name: mysql
user: "1000:1000"
environment:
MYSQL_ROOT_PASSWORD: password # 修改为自己的密码
MYSQL_REPLICATION_MODE: slave # 这三个环境变量会自动配置主从同步的用户和权限
MYSQL_REPLICATION_USER: replication
MYSQL_REPLICATION_PASSWORD: password # 修改为自己的密码
MYSQL_MASTER_PORT: 3306
command:
--server-id=101 # 根据需要修改,同一网络中唯一
--log-bin=binlog
--expire_logs_days=7
--read-only=1
# ports: # 使用主机网络(host)空间 模式时,ports 配置失效,要修改 服务启动端口 可 配置 my.cnf文件
# - "3306:3306"
volumes:
- /data/mysql-slave/volume:/var/lib/mysql
- /data/mysql-slave/config:/etc/mysql/conf.d
restart: always
|
3. 分别运行 docker-compose up -d 启动 master / slave 服务。
4. 使用 root 用户登录主服务器的MySQL实例,创建复制用户(如果尚未创建):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
-- 创建用户
CREATE USER 'replication'@'%' IDENTIFIED BY 'password';
ALTER USER 'replication'@'%' IDENTIFIED WITH mysql_native_password BY 'password';
-- 授权
GRANT REPLICATION SLAVE ON *.* TO 'replication'@'%';
-- 刷新权限
flush privileges;
-- 收回权限
REVOKE ALL PRIVILEGES ON *.* FROM 'replication'@'%';
-- 查看 master 节点状态
mysql> show master status\G;
*************************** 1. row ***************************
File: binlog.000260
Position: 157
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
ERROR:
No query specified
|
5. 在从服务器的MySQL实例中配置复制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
CHANGE MASTER TO
MASTER_HOST='master-host', -- 填写 master 节点 ip 或 主机名
MASTER_PORT=3306,
MASTER_USER='replication',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='binlog.000260',
MASTER_LOG_POS=157;
-- 说明:
-- MASTER_LOG_FILE 和 MASTER_LOG_POS 根据 master 节点上执行 show master status\G;的
-- 显示信息填写,详见 master 节点部署及配置
START SLAVE; -- 启动 slave 模式
STOP SLAVE; -- 停止 slave 模式
RESET SLAVE ALL; -- 清除 slave 模式配置
mysql> SHOW SLAVE STATUS \G; -- 查看 slave 状态
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.1.2
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000260
Read_Master_Log_Pos: 9779204
Relay_Log_File: prod-data2-relay-bin.000002
Relay_Log_Pos: 9779370
Relay_Master_Log_File: binlog.000260
Slave_IO_Running: Yes -- 这两项 状态为 yes 表示 slave 服务连接 master 服务同步数据成功
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 9779204
Relay_Log_Space: 9779585
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 100
Master_UUID: 82dfe18c-85e3-11ef-9910-d05099dc4fa5
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
|
替换 MASTER_LOG_FILE 和 MASTER_LOG_POS 为步骤3中得到的主服务器的二进制日志位置。
确保容器网络互通,并且相应的环境变量和命令参数已正确设置。
使用非默认端口的配置(使用于master 和 slave 节点):
由于在不通的宿主机上使用docker 容器部署 主从集群,股 容器需要共享主机网络空间(这样容器中的 slave 才能访问 master 进行同步),故 容器网络采用 network_mode: host 模式, 在该模式下, ports 端口映射配置失效,未配置下容器使用 默认端口 启动;
要配置容器使用非默认端口(例如:3307) 启动,需要为容器添加如下 /data/mysql/config/my.cnf 配置文件:
innodb_buffer_pool_size参数是Mysql数据库最重要的参数之一,表示InnoDB类型的表和索引的最大缓存。它不仅仅缓存索引数据,还会缓存表的数据。这个值越大,查询的速度就会越快,但是这个值太大会影响操作系统的性能, 一般情况下,该参数可以设置为 1/2 * mem 大小(设置为 1G: set global innodb_buffer_pool_size = 1024 * 1024 * 1024; , 也可在 mysql 配置文件中 的 [mysqld] 配置单元下 设置 为 innodb_buffer_pool_size=1G )。
6. 常见错误处理
6.1 从 master 节点 全量 copy 数据目录 到 slave 节点,slave 节点启动主从复制 后 SHOW SLAVE STATUS\G; 报 UUIDs 与 master 冲突 错误
解决方案: https://blog.csdn.net/m0_37680131/article/details/134281862
从错误字面上意思是mysql主从服务拥有了相同的uuid导致了从库无法正常工作;
删除 copy 副本数据目录下的的 auto.cnf 文件后重启服务即可。
uuid查看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
mysql> show variables like '%server_uuid%';
+---------------+--------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------+
| server_uuid | 7d7d763c-85ed-11ef-9960-d05099dc4dfd |
+---------------+--------------------------------------+
1 row in set (0.00 sec)
mysql> SHOW SLAVE STATUS \G;
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 192.168.1.2
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000250
Read_Master_Log_Pos: 696
Relay_Log_File: prod-data2-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000250
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 696
Relay_Log_Space: 157
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 13117
Last_IO_Error: Fatal error: The replica I/O thread stops because source and replica have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 100
Master_UUID:
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 241009 02:05:34
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
|
6.2 主从数据不一致错误
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
mysql> SHOW SLAVE STATUS \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.1.2
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000256
Read_Master_Log_Pos: 2066
Relay_Log_File: prod-data2-relay-bin.000006
Relay_Log_Pos: 415143
Relay_Master_Log_File: binlog.000254
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1410
Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at source log binlog.000254, end_log_pos 417982. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
Skip_Counter: 0
Exec_Master_Log_Pos: 414933
Relay_Log_Space: 52499735
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1410
Last_SQL_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at source log binlog.000254, end_log_pos 417982. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
Replicate_Ignore_Server_Ids:
Master_Server_Id: 100
Master_UUID: 82dfe18c-85e3-11ef-9910-d05099dc4fa5
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp: 241009 02:10:07
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
-- 查看冲突数据表
mysql> select * from performance_schema.replication_applier_status_by_worker\G;
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 1
THREAD_ID: NULL
SERVICE_STATE: OFF
LAST_ERROR_NUMBER: 1410
LAST_ERROR_MESSAGE: Worker 1 failed executing transaction 'ANONYMOUS' at source log binlog.000254, end_log_pos 417982; Error 'You are not allowed to create a user with GRANT' on query. Default database: ''. Query: 'GRANT REPLICATION SLAVE ON *.* TO 'replication'@'%''
LAST_ERROR_TIMESTAMP: 2024-10-09 02:10:07.549044
LAST_APPLIED_TRANSACTION: ANONYMOUS
LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 2024-10-09 01:20:54.066185
LAST_APPLIED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 2024-10-09 01:20:54.066185
LAST_APPLIED_TRANSACTION_START_APPLY_TIMESTAMP: 2024-10-09 02:10:07.422568
LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP: 2024-10-09 02:10:07.545832
APPLYING_TRANSACTION: ANONYMOUS
APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 2024-10-09 01:30:07.576531
APPLYING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 2024-10-09 01:30:07.576531
APPLYING_TRANSACTION_START_APPLY_TIMESTAMP: 2024-10-09 02:10:07.545979
LAST_APPLIED_TRANSACTION_RETRIES_COUNT: 0
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_NUMBER: 0
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_MESSAGE:
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_TIMESTAMP: 0000-00-00 00:00:00.000000
APPLYING_TRANSACTION_RETRIES_COUNT: 0
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_NUMBER: 0
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_MESSAGE:
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_TIMESTAMP: 0000-00-00 00:00:00.000000
|
6.3 从服务同步线程启动失败报错
1
2
3
4
|
mysql> start slave;
ERROR 1872 (HY000): Replica failed to initialize applier metadata structure from the repository
mysql> start replica;
ERROR 1872 (HY000): Replica failed to initialize applier metadata structure from the repository
|
ERROR 1872 (HY000): Replica failed to initialize applier metadata structure from the repository 是MySQL数据库中的一个错误。它表示在复制过程中,从存储库初始化应用程序元数据结构时出现了问题。
这个错误通常发生在MySQL复制设置中,其中一个从服务器(replica)试图从主服务器(master)获取复制数据时遇到问题。
当出现这个错误时,可能有以下几个原因导致:
- 存储库中的元数据损坏:存储库中的元数据可能已损坏或不完整,导致无法正确初始化应用程序元数据结构。
- 复制过程中的网络问题:复制过程中可能存在网络问题,导致从主服务器获取复制数据失败。
- 主服务器配置问题:主服务器的配置可能存在问题,导致无法正确提供复制数据。
为了解决这个问题,可以尝试以下几个步骤:
- 检查存储库的完整性:可以尝试修复存储库中的元数据,或者重新创建存储库。
- 检查网络连接:确保主服务器和从服务器之间的网络连接正常,并且没有任何阻塞或延迟。
- 检查主服务器配置:确保主服务器的配置正确,并且可以正确提供复制数据。
然后运行如下命令一般可以修复slave 节点错误:
1
2
3
4
5
|
mysql> reset slave;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.01 sec)
|
6.4 mysql 启动
服务器启动完成之后MySQL程序无法启动,或者 copy mysql data目录创建新节点无法启动
在mysql的配置文件中加入以下内容:
innodb_force_recovery = 1
innodb_force_recovery 配置其中参数的含义是:
1 (SRV_FORCE_IGNORE_CORRUPT): 即使检测到损坏的页面,也允许服务器运行。尝试使 SELECT * FROM tbl_name跳过损坏的索引记录和页面,这有助于转储表。
2 (SRV_FORCE_NO_BACKGROUND): 阻止主线程和任何清除线程运行。如果在清除操作期间发生意外退出,则此恢复值会阻止它。
3 (SRV_FORCE_NO_TRX_UNDO): 崩溃恢复后不运行事务回滚.
4 (SRV_FORCE_NO_IBUF_MERGE): 阻止插入缓冲区合并操作。如果它们会导致崩溃,请不要这样做。不计算表统计信息。此值可能会永久损坏数据文件。使用此值后,请准备好删除并重新创建所有二级索引。将 InnoDB 设置为只读。
5 (SRV_FORCE_NO_UNDO_LOG_SCAN): 启动数据库时不查看撤消日志:InnoDB 甚至将未完成的事务视为已提交。此值可能会永久损坏数据文件。将 InnoDB 设置为只读。
6(SRV_FORCE_NO_LOG_REDO): 不执行与恢复相关的重做日志前滚。此值可能会永久损坏数据文件。使数据库页处于过时状态,这反过来又可能会给 B 树和其他数据库结构带来更多损坏。将 InnoDB 设置为只读。
从1开始逐步往上尝试启动
启动成功后, 注释掉该配置, 重启MySQL 服务, 否则 MySQL 只读,不能写。