一、MATLAB Mat文件概述
1.1 Mat 文件简介
Mat 文件格式 是 MATLAB 中用于数据存储的标准文件格式,是标准的二进制文件。它是一种灵活且高效的方式,可用于存储各种数据类型,包括标量、数组、结构体和对象等。MAT文件 在MATLAB中广泛使用,用于数据存储、共享和协作。
MAT文件 具有分层结构,包括一个头文件和一个数据文件:
- 头文件包含有关文件格式、版本和数据类型的元数据;
- 数据文件包含实际的数据;
这种分层结构允许快速访问数据,同时保持文件大小相对较小。
在Matlab中主要使用load()函数导入一个Mat文件,使用save()函数保存一个mat文件。 Mat 格式文件在Matlab中打开显示类似于单行EXCEL表格。
二、MAT文件结构的理论基础
2.1 MAT文件格式和版本
MAT文件 采用二进制格式存储数据,其结构由MATLAB版本决定。
目前,MATLAB支持以下MAT文件版本:
| 版本 | 描述 |
|---|---|
| v4 | MATLAB 4.0 及更早版本 |
| v5 | MATLAB 5.0 至 7.0 版本 |
| v7 | MATLAB 7.1 及 更高版本 |
每个MAT文件都包含一个文件头,其中存储了文件版本、数据类型和编码方案等信息。文件头的大小为128字节,其结构如下:
|
|
- version: 文件版本,占4字节。
- endianIndicator: 字节序指示符,占4字节。值为0 - 表示小端序; 值为1 - 表示大端序。
- numFields: 文件中的变量数量,占4字节。
- reserved: 保留字段,占4字节。
2.2 数据类型和编码方案
MAT文件 支持多种数据类型,包括:
| 数据类型 | 描述 |
|---|---|
| double | 双精度浮点数 |
| single | 单精度浮点数 |
| int8 | 8位有符号整数 |
| uint8 | 8位无符号整数 |
| int16 | 16位有符号整数 |
| uint16 | 16位无符号整数 |
| int32 | 32位有符号整数 |
| uint32 | 32位无符号整数 |
| int64 | 64位有符号整数 |
| uint64 | 64位无符号整数 |
| char | 字符 |
| cell | 单元格数组 |
| struct | 结构体 |
MAT文件还支持以下编码方案:
| 编码方案 | 描述 |
|---|---|
| ASCII | 文本编码,用于存储字符数据 |
| IEEE 754 | 浮点数编码,用于存储浮点数据 |
| MATLAB | MATLAB内部编码,用于存储其它数据类型 |
当MATLAB写入MAT文件时,它会根据数据类型和编码方案选择适当的存储格式。例如,双精度浮点数将以IEEE 754格式存储,而字符将以ASCII格式存储。
三、 MAT文件操作
3.1 MAT文件读写操作
- 读取MAT文件 MATLAB提供了load函数来读取MAT文件。该函数接受一个文件名或文件路径作为参数,并返回一个包含MAT文件数据的结构体变量。
|
|
- 写入MAT文件 MATLAB提供了save函数来写入MAT文件。该函数接受一个文件名或文件路径、一个结构体变量和一个可选的选项参数作为参数。
|
|
save函数的选项参数允许用户指定附加设置,例如:
-v7.3: 指定MAT文件格式版本为7.3。-append: 将数据追加到现有MAT文件中。-mat: 仅保存数据变量,不保存结构体。
3.2 MAT文件数据提取和转换
- 提取数据 从MAT文件结构体中提取数据可以使用点运算符(.)。例如,要提取名为x的变量,可以使用以下代码:
|
|
- 转换数据 MATLAB提供了各种函数来转换MAT文件中的数据,例如:
- double(): 将数据转换为双精度浮点数。
- int32(): 将数据转换为32位整数。
- char(): 将数据转换为字符数组。
|
|
3.3 MAT文件优化和压缩
MATLAB提供了whos函数来查看MAT文件中的变量大小和类型。这有助于识别可以优化的大型或不必要的变量。
|
|
MATLAB提供了saveobj和loadobj函数来实现MAT文件压缩。这些函数允许用户定义自定义压缩方法。
|
|
四、MAT文件在MATLAB中的应用
4.1 数据存储和管理
MATLAB MAT文件作为一种高效的数据存储格式,在MATLAB中广泛用于数据存储和管理。通过MAT文件,用户可以将MATLAB变量、数据结构和对象持久化存储在磁盘上,以便在需要时快速加载和使用。
- 数据存储
MAT文件存储数据时,会将MATLAB变量和数据结构转换为一种二进制格式。这种格式经过优化,可以高效地存储各种数据类型,包括数值、字符串、结构体、单元格数组和自定义对象。
|
|
- 数据加载
存储在MAT文件中的数据可以通过load函数加载到MATLAB工作空间中。
|
|
4.2 数据共享
MAT文件是MATLAB用户之间共享和协作数据的一种便捷方式。通过将数据存储在MAT文件中,用户可以轻松地将数据发送给其它用户,以便它们使用、分析或修改数据。
- 数据共享
MAT文件可以轻松地通过电子邮件、文件共享服务或版本控制系统进行共享。
|
|
4.3 数据分析和可视化
MAT文件还广泛用于MATLAB中的数据分析和可视化。通过将数据存储在MAT文件中,用户可以快速加载和处理大量数据,并使用MATLAB强大的分析和可视化工具进行探索和分析。
- 数据分析 MAT文件中的数据可以使用MATLAB内置函数和工具进行分析,包括统计分析、信号处理和机器学习算法。
|
|
- 数据可视化 MAT文件中的数据可以使用MATLAB的图形功能进行可视化,包括折线图、散点图和直方图。
|
|
五、H5文件
5.1 H5文件简介
H5文件 是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是用于存储科学数据的一种文件格式和库文件。由美国超级计算中心与应用中心研发的文件格式,用以存储和组织大规模数据。
- H5是一种开源文件格式,支持大型、复杂的异构数据。
- H5使用类似“文件目录”的结构,允许以多种不同的结构化方式组织文件中的数据,就像处理计算机上的文件一样。
- H5格式还允许嵌入元数据,使其具有自描述性。
5.2 H5文件的数据组织方式
h5格式文件 将文件结构简化成两个主要的对象类型:组(group)和 数据集(dataset)。
- dataset :类似数组组织形式的数据集合(同一类型数据的多维数组),像 numpy 数组一样工作,一个 dataset 即一个numpy.ndarray。具体的dataset可以是图像、表格,甚至是pdf文件和excel。 处理group和dataset在许多方面类似于处理 UNIX 中的目录和文件。 与 UNIX 目录和文件一样,H5 文件中的对象通常通过提供完整(或绝对)路径名来描述。
- group:是一种容器结构,可以包含数据集(dataset)和其它组(group),若一个文件中存放了不同种类的数据集,这些数据集的管理就用到了 group 。
直观的理解,H5文件就像计算机的一个文件系统(目录和文件),不同的文件存放在不同的目录下:
- 目录就是hdf5文件中的group,描述了数据集DataSet的分类信息,通过group有效的将多种dataset进行管理和划分;
- 文件就是hdf5文件中的dataset,表示具体的数据。
下图就是数据集和组的关系:
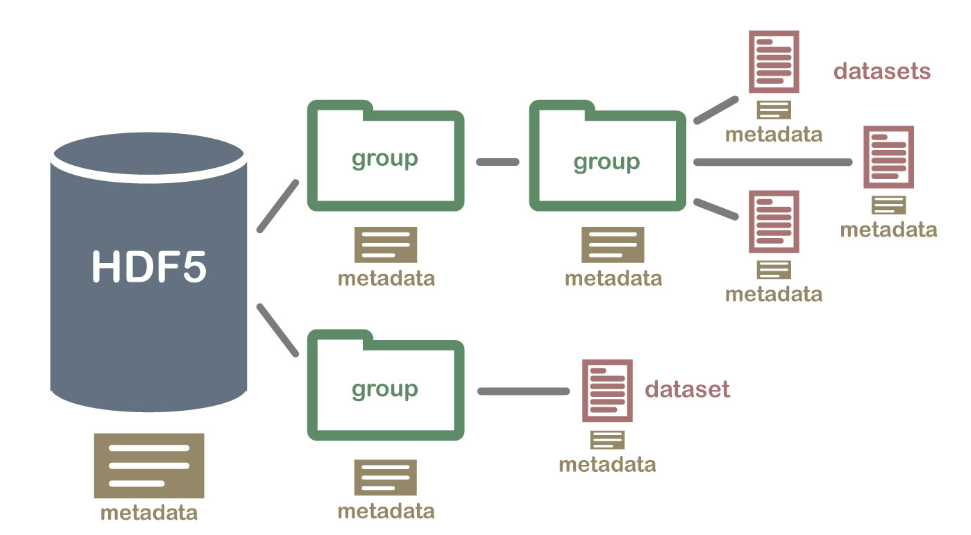
总结起来说,H5文件 是一个存放 数据集(dataset)和组(group) 这两类对象的容器。dataset 类似数组类的数据集合,和numpy的数组差不多;group 是像文件夹一样的容器。它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其它的group。‘键’就是组成员的名称,‘值’ 就是组成员对象本身(组或者数据集)。
5.3 Python h5py库创建、读取H5文件
|
|
File 用于打开或创建一个 HDF5 文件对象:
name为文件名字符串;mode为打开文件的模式;driver可以指定一种驱动方式,如需进行并行 HDF5 操作,可设置为mpio;libver可以指定使用的兼容版本,默认为earliest,也可以指定为latest;userblock_size以字节为单位指定一个在文件开头称作 user block 的数据块,一般不需要设置;
实例化 File 类的一个对象将返回所打开文件的句柄。
有效的 mode 参数有:
r只读,文件必须存在r+读写,文件必须存在w创建新文件写,已经存在的文件会被覆盖掉w- / x创建新文件写,文件如果已经存在则出错a打开已经存在的文件进行读写,如果不存在则创建一个新文件读写,此为默认的 mode
创建group组
|
|
创建一个新的 group。以类似目录路径的形式指明所创建 group 的名字 name,如果 track_order 为 True,则会跟踪在当前 group 下的 group 和 dataset 创建的先后顺序。该方法可以在打开的文件句柄(相当于 “/” group)或者一个存在的 group 对象上调用,此时 name 的相对路径就是相对于此 group 的。
Python 创建H5文件示例
|
|
创建dataset数据集
|
|
创建一个新的 dataset。以类似文件路径的形式指明所创建 dataset 的名字 name,shape 以一个 tuple 或 list 的形式指明创建 dataset 的 shape,用 “()” 指明标量数据的 shape,dtype 指明所创建 dataset 的数据类型,可以为 numpy dtype 或者一个表明数据类型的字符串,data 指明存储到所创建的 dataset 中的数据。如果 data 为 None,则会创建一个空的 dataset,此时 shape 和 dtype 必须设置;如果 data 不为 None,则 shape 和 dtype 可以不设置而使用 data 的 shape 和 dtype,但是如果设置的话,必须与 data 的 shape 和 dtype 兼容。
|
|
Python 读取H5文件示例
|
|