一、Go语言内存管理
1.1 Go语言内存分配
在Go语言中,内存分配有两种方式:栈分配和堆分配。栈分配是在函数调用时为局部变量分配内存,当函数返回时,这些内存会自动释放。而堆分配则是通过 new 或者 make 函数动态分配内存,需要手动进行释放。
Go在程序启动的时候,会先向操作系统申请一块内存(只是一段虚拟的地址空间,并不会真正地分配内存),分割成小块后自己进行管理。Go申请到的内存块被分配了三个区域:
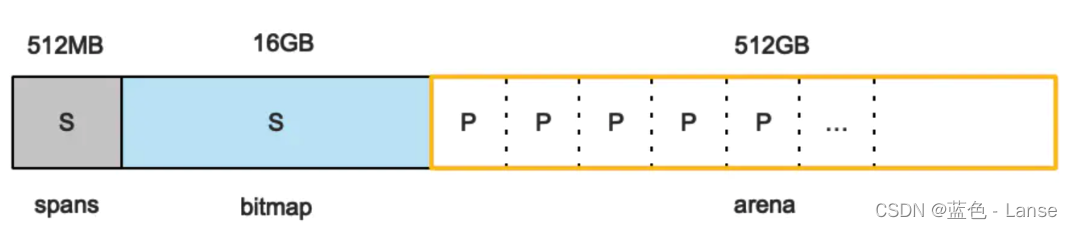 spans: spans区域存放 mspan(是一些arena分割的页组合起来的内存管理基本单元)的指针;
bitmap:bitmap区域标识arena区域哪些地址保存了对象;
arena: arena区域就是所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成 8KB大小的页,这些页组合起来称为mspan;
spans: spans区域存放 mspan(是一些arena分割的页组合起来的内存管理基本单元)的指针;
bitmap:bitmap区域标识arena区域哪些地址保存了对象;
arena: arena区域就是所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成 8KB大小的页,这些页组合起来称为mspan;
Go内存分配规则管理:
- 小于等于16B内存分配:是在每个M的mcache上的微型分配器进行分配。
- 小于等于32K大于16B内存分配:GPM调度模型中,每个M绑定一个P,每个P绑定一个mcache,当该P管理的本地队列中的某个G想要申请内存时候,会从mcache中申请mspan。如果没有空闲的mspan或者没有特定大小的mspan了,则mcache就会向mcentral中获取。mcentral被所有线程共享。当 mcentral 没有空闲的 mspan 时,会向 mheap 申请。而 mheap 没有资源时,会向操作系统申请新内存。
- 大于32kb内存分配:对于那些超过32KB的内存申请,会直接从堆上(mheap)上分配对应的数量的内存页(每页大小是8KB)。
- 内存对齐:Go 语言的内存分配器会将分配的内存按照一定的规则进行对齐。
- 内存复用:Go 语言的垃圾回收器会尽可能地复用已经分配的内存,以减少内存分配和回收的开销。当某个 mspan 中的对象被回收后,该 mspan 中的空闲对象数量会增加,当空闲对象数量达到一定阈值时,该 mspan 就会被移出空闲列表,以便下次分配内存时可以重复利用。
在 Golang 中,基本类型的变量(如 int、float、bool 等)和小的结构体变量通常会被分配在栈上。引用类型的变量(如:slice、map、chan,interface 等)通常会被分配在堆上。
1.2 Golang的内存逃逸
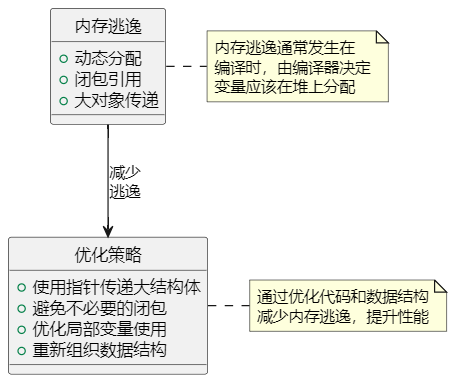
在Go语言程序的编译过程中,编译器会决定程序变量的存储位置 —— 栈 或 堆。当编译器认为某个变量的生命周期无法在函数执行期间确定时,它就会将这个变量分配到堆上,这个现象被称为 “内存逃逸”。虽然这种机制可以帮助我们避免复杂的内存管理问题,但过度的 内存逃逸 会增加垃圾回收器(GC)的工作负担,进而影响程序的性能。
堆内存(Heap):一般来讲是人为手动进行管理,手动申请、分配、释放。在函数运行结束后仍然可以使用,如果要回收掉,需要进行GC,会带来额外的性能开销。适合不可预知大小的内存分配,分配速度较慢,而且会形成内存碎片。
栈内存(Stack):是一种拥有特殊规则的线性表数据结构。由编译器进行管理(由系统进行申请和释放),自动申请、分配、释放。eg.函数的入参、局部变量、返回值等,每个函数都会分配一个栈帧,在函数运行结束后进行销毁
Golang的内存逃逸 是指原本应该在栈上分配的内存被分配到了堆上。这意味着即使函数返回后,这部分内存也不会被自动释放,需要等待垃圾回收器来回收。
Golang中对象是在堆上分配、还是在栈上分配,这取决于编译器和逃逸分析的结果。
- 一般来说,函数的局部变量会被分配在栈上(静态内存分配),而动态分配的对象(如使用 new 或 make 函数创建的对象)会被分配在堆上(动态内存分配)。
- 但是,如果编译器可以确定一个局部变量在函数返回后被引用,那么编译器会将该变量分配在堆上,而不是栈上。
为什么会发生内存逃逸
- 动态内存分配:Go语言使用垃圾回收机制(GC)来自动清理不再使用的内存,这意味着需要动态分配内存。当变量的生命周期不确定时,为了安全起见,编译器会将其分配到堆上。
- 闭包变量使用:如果一个变量被闭包引用,它可能在函数返回后仍然被需要,因此这种变量通常会逃逸到堆上。
- 大对象传递:如果一个大的结构体被频繁地作为参数传递,它可能也会被分配到堆上,以避免栈的过度消耗和复制成本。
如何减少内存逃逸
- 使用指针传递大结构体:通过使用指针而不是值传递大的结构体,可以减少因复制而导致的性能开销和内存逃逸风险。
- 避免不必要的闭包:仔细分析并避免不必要的闭包使用,因为闭包可能会导致外部变量逃逸,尤其是当这些闭包被传递到其它函数中去时。
- 局部变量优化:尽量使用局部变量替代全局变量,局部变量更可能在栈上分配,从而减少逃逸。
- 合理组织数据结构:使用更小的数据结构或重新组织数据字段,有时通过减少不必要的指针字段可以避免内存逃逸。
Tips: 逃逸分析 是一种静态分析技术,可以帮助编译器确定变量的作用域和生命周期,从而优化变量的分配方式。
- 通过
go build -gcflags -m命令来观察变量逃逸情况,go build -gcflags="-m -m"命令 可以显示每个变量的逃逸分析结果。- Go编译器会在编译期对考察变量的作用域,就可能会出现内存逃逸。
- 使用Go的pprof工具进行内存剖析,可以帮助开发者识别出内存使用的热点。
如果一个变量被传递给一个函数,或者被存储到一个堆数据结构中,那么它可能会被分配到堆上。这是因为编译器会进行逃逸分析,如果发现变量的生命周期超出了当前函数的作用域,那么它就会被分配到堆上,以确保它在函数返回后仍然可以被访问。
内存逃逸的主要原因是在函数返回后,局部变量仍然被外部引用。以下是一些可能导致内存逃逸的情况:
- 变量的生命周期超出了其作用域,当一个变量在函数外部被引用,比如被赋值给一个包级别的变量或者作为返回值,这个变量就会发生逃逸。
- 闭包引用,如果一个函数返回一个闭包,并且该闭包引用了函数的局部变量,那么这些变量也会逃逸到堆上。
- 大对象的分配,对于大型的数据结构,Go 有时会选择在堆上分配内存,即使它们没有在函数外部被引用。
- 接口动态分配,当一个具体类型的变量被赋值给接口类型时,由于接口的动态特性,具体的值可能会发生逃逸。
- 切片和 map 操作,如果对切片进行操作可能导致其重新分配内存,或者向 map 中插入数据,这些操作可能导致逃逸。
- 函数/方法 内返回局部变量的指针,则这些变量会逃逸到堆中
- 向 channel 发送指针数据,则这些数据会逃逸到堆中
- 在闭包中引用包外的值,则这些数据会逃逸到堆中
- slices 中存储指针或是带有指针的值,则这些数据会逃逸到堆中
- interfacec{}类型
- 栈内存溢出
内存逃逸的影响 如果频繁发生内存逃逸,会导致程序占用过多的内存资源,影响程序的性能和稳定性。主要体现在以下几个方面:
- 内存占用增加:由于堆分配的内存不会自动释放,所以会导致程序占用的内存资源不断增加,特别是在长时间运行的程序中,可能会导致系统资源耗尽。
- 性能下降:相比于栈分配,堆分配需要更多的 CPU 和内存资源,同时也容易造成内存碎片,因此会导致程序的运行速度变慢。
- 程序不稳定:如果程序中存在大量的内存逃逸,可能会导致垃圾回收器频繁工作,从而影响程序的稳定性。
避免内存逃逸可以提高程序的性能,减少垃圾回收的压力。以下是一些常见的优化策略:
- 严格限制变量的作用域。如果一个变量只在函数内部使用,就不要将其返回或赋值给外部变量。
- 使用值而不是指针,当不必要的时候,尽量使用值传递而不是指针传递。
- 池化对象,对于频繁创建和销毁的对象,考虑使用对象池技术进行复用,减少在堆上分配和回收对象的次数。
- 尽量避免在循环或频繁调用的函数中创建闭包,以减少外部变量的引用和堆分配,避免使用不必要的闭包,闭包可能会导致内存逃逸。
- 优化数据结构,使用固定大小的数据结构,避免使用动态大小的切片和 map。比如使用数组而不是切片,因为数组的大小在编译时就已确定。
- 预分配切片和 map 的容量,如果知道切片或 map 的大小,预先分配足够的容量可以避免在运行时重新分配内存。
内存逃逸是Go内存管理机制的一部分,通过合理的设计和代码优化,可以显著减少内存逃逸的发生,从而提升Go程序的性能。开发者可利用工具和编译器的提示,不断优化代码,避免不必要的内存逃逸,确保程序运行高效稳定。
二、Go语言垃圾回收(GC)机制
Go语言GC机制超详细: https://blog.csdn.net/qq_56999918/article/details/127538969 go语言GC面试: https://blog.csdn.net/zhaicheng55/article/details/128147917
2.1 GC触发机制
- 内存分配量达到阀值触发 GC 每次内存分配,都会检查当前内存分配量是否已达到阀值,如果达到则立即启动 GC: 阀值 = 上次 GC 内存分配量 * 内存增长率 内存增长率由环境变量 GOGC 控制,默认为 100,即每当内存扩大一倍时启动 GC
- 定期触发 GC 默认情况下,最长 2 分钟,由sysmon触发一次 GC (这个间隔在 src/runtime/proc.go:forcegcperiod 变量中被声明)
- 空间不足时触发 当前线程的内存管理单元中不存在空闲空间时,创建32KB以下的对象可能触发垃圾收集,创建32KB以上的对象时,一定会尝试触发
- 手动触发 程序代码中也可以使用 runtime.GC()来手动触发 GC。这主要用于 GC 性能测试和统计。
2.2 finalizer(终止器)
概念:finalizer(终止器)是与对象关联的一个函数,通过调用 runtime.SetFinalizer 来设置finalizer,如果某个对象定义了 finalizer,当它被 GC 时候,这个 finalizer 就会被调用来完成一些特定的任务,例如发信号或者写日志等。
- finalizer(终止器)用法介绍 runtime.SetFinalizer函数定义如下:
|
|
有几点需要注意:
- obj必须是对象指针。
- SetFinalizer使原本对象的回收延长到了两步,第一步是解除finalizer和obj对象的关联,另起一个协程执行finalizer。第二步gc时才真正回收obj对象。这造成了对象生命周期的延长,对于大量对象分配的高并发场景需要引起注意。
- finalizer的执行顺序具有依赖关系。如果A指向B,两者都设置了finalizer,则如果A和B均不可达,则在GC时首先执行A的finalizer,然后回收A。之后才能执行B的finalizer。
- 禁止指针循环引用和SetFinalizer同时使用。考虑到第3点,如果多个指针构成循环引用,则无法确定finalizer的依赖关系,因而无法执行SetFinalizer,目标对象不能变成不可达状态,造成内存无法回收。
示例:
|
|
2.3 GC版本发展与变化
- 相关概念解释
STW(Stop The World) Go中的STW就是停止所有的goroutine,专心做垃圾回收,等待回收完毕再恢复goroutine。 GC优化 主要缩短STW时间,不断优化GC算法。 写屏障 写屏障的作用是使goroutine与GC同时运行的手段。能够大大缩短STW时间。 GC过程中新分配的内存不会被立即标记,用的正是写屏障技术,即GC过程中分配的内存不会在本次GC中清理。 协助GC 为了防止内存分配过快,在GC过程中如果goroutine需要分配内存,那么该goroutine会参与一部分GC工作。这种机制称为Mutator Assist。
- Go V1.3版本之前 标记清除(mark and sweep)法
流程:
- 启动STW: 启动STW(Stop The World),暂停程序
- Mark标记: 对所有存活的内存单元进行扫描,遍历所有被引用的变量,被引用的对象被标记为“被引用",没有被标记的进行回收,内存单元并不会立刻回收对象,而是将其标记为“不可达”状态。直到到达某个阈值或者到达某个时间间隔后,对其进行垃圾回收
- Sweep清扫: 垃圾回收
- 停止STW: 暂停STW,程序继续运行
缺点:
- STW程序出现卡顿
- 标记需要扫描整个heap和stack(堆栈信息)
- 清除数据会产生heap碎片
- GoV1.3 标记清除(mark and sweep)法(优化STW)
流程:
- 启动STW
- Mark标记
- 停止STW
- Sweep清扫
- Go V1.5 三色标记法,堆空间启动写屏障,栈空间不启动,全部扫描之后,需要重新扫描一次栈(需要STW),效率一般。
基本思路:首先将所有对象都放入白色标记表中,然后遍历程序的根节点(只遍历一层),得到灰色节点,然后遍历该灰色节点,将可达的对象,从白色标记为灰色,自身变为黑色。重复上面步骤,直到灰色标记表中无任何对象。
最不希望发生的事(会造成对象无辜的被清理):一个白色对象被黑色对象引用 且 灰色对象与它之间的可达关系的白色对象遭到破坏。
解决方法:强弱三色不变式(强 —— 破坏条件1,即强制性的不允许黑色对象引用白色对象;弱 —— 破坏条件2,黑色对象引用白色对象时,需要满足白色对象存在其它灰色对象对它的引用,或者可以达它的链路上游存在灰色对象),这种强弱不变式就是 屏障机制
三色标记将对象分为黑色、白色、灰色三种: 黑色:对象在这次GC中已标记, 且这个对象包含的子对象也已标记,表示对象是根对象可达的 白色:未标记对象,gc开始时所有对象为白色,当gc结束时,如果仍为白色,说明对象不可达,在 sweep 阶段会被清除 灰色:被黑色对象引用到的对象,对象在这次GC中已标记, 但这个对象包含的子对象未标记,灰色为标记过程的中间状态,当灰色对象全部被标记完成代表本次标记阶段结束
名词解释: 根对象: 包含了全局变量, 各个goroutine栈上的变量等 标记队列: GC的标记阶段使用"标记队列"来确定所有可从根对象到达的对象都已标记 辅助GC(mutator assist): 为了防止heap增速太快, 在GC执行的过程中如果同时运行的G分配了内存, 那么这个G称为"mutator", “mutator assist"机制被要求辅助GC做一部分的工作,辅助GC做的工作有两种类型: 一种是标记(Mark), 另一种是清扫(Sweep)
三色标记流程:
- 初始时所有对象都为白色
- gc开始扫描,将所有根对象标记为灰色,放入队列
- 遍历灰色对象,找到其引用的对象,将引用的对象标记为灰色,将灰色对象标记成黑色
- 重复以上3步骤,直至没有灰色对象
- 对所有白色对象进行清除
- Go V1.8 三色标记法,混合写屏障机制,栈空间不启动(全部标记成黑色),堆空间启用混合写屏障。整个过程几乎不需要STW,效率较高。 混合写屏障机制(GoV1.8的三色标记法),步骤如下: 1、GC开始将栈上的对象全部扫描并标记为黑色; 2、GC期间,任何在栈上创建的新对象,均为黑色; 3、被删除的对象标记为灰色; 4、被添加的对象标记为灰色;
2.3 屏障机制的实现(插入屏障 和 删除屏障)
插入屏障(强三色不变式):(对象被引用时触发的机制)在A对象引用B对象时候,B对象被标记为灰色。(插入屏障不在栈上使用,因为性能影响大,所以会导致栈上黑色对象创建对象时会有无辜对象被gc清理,所以最终需要进行stw,然后重新扫描一次栈)。缺点:结束时需要STW来重新扫描栈(防止对象丢失,因为黑色对象会创建对象,所以最终会重新扫描一次栈,需要进行短暂的STW)。
删除屏障(弱三色不变式):(对象被删除时触发的机制)被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。保护了被删除对象,因为它有可能此时被其它对象引用。缺点:回收精度低。一个对象被删除,此轮会存活。下一轮才会被GC清理掉。
三、Golang内存泄露简介
3.1 何为内存泄漏
内存泄漏:是指在程序运行过程中,分配的内存空间没有被正确释放或回收的情况。
内存泄漏并不是指物理上的内存消失,而是在写程序的过程中,由于程序的设计不合理导致对之前使用的内存失去控制,无法再利用这块内存区域;短期内的内存泄漏可能看不出什么影响,但是当时间长了之后,日积月累,浪费(失去控制)的内存越来越多,导致可用的内存空间减少、直至没有,轻则影响程序性能,严重可导致正在运行的程序突然崩溃(OOM)。
一个进程结束之后,内存会自动回收,同时也会自动回收那些被泄露的内存,当进程重新启动后,这些内存又可以重新被分配使用。但是正常情况下企业的程序是不会经常重启的,所以最好的办法就是从源头上解决内存泄漏的问题。
常见的内存泄漏:
- goroutine 在执行时被阻塞而无法退出
- 互斥锁未释放或者造成死锁会造成内存泄漏
- 使用了time.Ticker但是没有调用stop()方法
- 字符串的截取引发的内存泄漏
- 切片截取引起子切片内存泄漏
- 函数数组传参引发内存泄漏(参数内存很大)
3.2 内存泄漏排查方式
如果出现内存泄漏,可以使用以下方式进行分析,找出内存泄漏的原因并进行修复。
1.使用 Go 语言自带的 pprof 工具进行分析
pprof 可以生成程序的 CPU 和内存使用情况的报告,帮助开发者找出程序中的性能瓶颈和内存泄漏问题。可以通过在代码中添加 import _ “net/http/pprof” 和 http.ListenAndServe(“localhost:6060”, nil) 来开启 pprof 工具。
2.使用 Golang 内置的 runtime 包进行分析
runtime 包提供了一些函数,包括 SetFinalizer、ReadMemStats 和 Stack 等,可以帮助开发者了解程序的内存使用情况和内存泄漏问题。
3.使用第三方工具进行分析
例如,可以使用 go-torch 工具生成火焰图,帮助开发者找出程序中的性能瓶颈和内存泄漏问题。
4.使用 go vet 工具进行静态分析
go vet 可以检查程序中的常见错误和潜在问题,包括内存泄漏问题。
5.代码审查
开发者可以通过代码审查来找出程序中的潜在问题和内存泄漏问题。
四、Goroutine泄露的危害、成因、检测与防治
参考博客:https://cloud.tencent.com/developer/article/2296700
4.1 Goroutine泄露的危害
Go内存泄露,相当多数都是goroutine泄露导致的。 虽然每个goroutine仅占用少量(栈)内存,但当大量goroutine被创建却不会释放时(即发生了goroutine泄露),也会消耗大量内存,造成内存泄露。 使用 runtime.NumGoroutine() 监视goroutine的数量。
另外,如果goroutine里还有在堆上申请空间的操作,则这部分堆内存也不能被垃圾回收器回收。
4.2 goroutine造成泄露的原因
- 从 channel 里读,但是同时没有写入操作
- 向 无缓冲 channel 里写,但是同时没有读操作
- 向已满的 有缓冲 channel 里写,但是同时没有读操作
- select操作在所有case上都阻塞
- goroutine进入死循环,一直结束不了
goroutine造成内存泄露的原因 大多都是因为 goroutine阻塞 导致占用的内存无法释放、进程的 goroutine 越积越多 使得进程占用的内存空间一直上升,因而影响性能,直至 OOM。
五、其它常见的内存泄漏成因与防治
5.1 time.Ticker造成内存泄漏
go语言的time.Ticker主要用来实现定时任务,time.NewTicker(duration) 可以初始化一个定时任务,里面填写的时间长度duration就是指每隔 duration 时间长度就会发送一次值,可以在 ticker.C 接收到。 这里容易造成内存泄漏的地方主要在于编写代码过程中没有stop掉这个定时任务,导致定时任务一直在发送,从而导致内存泄漏。
|
|
- 原理分析
要了解为什么会产生内存泄漏,我们需要看看time package里面time.After函数的的定义。https://pkg.go.dev/time
|
|
该方法可以在一定时间(根据所传入的 Duration)后主动返回 time.Time 类型的 channel 消息。
注意: 描述里面写的很清楚: - 在计时器触发之前,垃圾收集器不会回收Timer - 如果考虑效率,需要使用NewTimer替代
|
|
- 解决方案
使用NewTimer来做定时器,不需要每次都创建定时器对象。 time.After虽然调用的是timer定时器,但是它没有使用time.Reset()方法再次激活定时器,所以每一次都是新创建的实例,才会造成的内存泄漏。
使用NewTimer创建定时器,再加上每次调用time.Reset重新激活(设置)定时器(是指上只创建了一个定时器,每次循环时重复使用该定时器),即可完美解决问题。
|
|
5.2 slice造成内存泄漏
切片本质是对数组的引用,在传递过程中是引用传递(在传递大容量的切片时是可以节省空间的),只需要传递一个地址,但是正因为这一特性,使得slice在使用不当的情况下会发生内存泄漏
|
|
- 解决办法
- 采用append的方法,append不会直接引用原来的数组,而是会新申请内存来存放数据
|
|
- 使用copy代替直接切片的写
|
|
5.3 map中存大长度类型对象数据删除后不会GC
map在内存中总是一直在增长、不会收缩。因此,如果map导致了一些内存问题,可以尝试不同的选项,比如强制 Go 重新创建map 或 使用指针做键值对的值。
在 Go 中,map增长和收缩有一些重要特性,使用不当可能导致内存泄漏的问题。 示例:
|
|
m 的每个元素都是一个包含 128 字节的数组,执行以下操作:
- 1)分配一个空的map;
- 2)添加 100 万个元素到map中;
- 3)删除所有元素,并运行垃圾回收(GC);
在完成每个步骤之后,我们都打印堆的大小(使用一个 printAlloc 实用函数)。这将展示这个示例内存占用的变化情况:
|
|
运行结果
|
|
创建 map 起初,堆大小很小。 然后,在将 100 万个元素添加到map后,它显著增长了(如果期望在删除 map 中所有元素后堆大小会减小,这并不是 Go 中map的工作方式)。 最后,尽管 GC 已经收集了所有元素,但堆大小仍然是 293 MB。
因此,内存缩小了,但这并非我们预期的方式和效果。
这其中的原理是什么?我们需要深入了解一下 Go 中map的工作原理:
map提供了一个无序的键值对集合,其中所有的键都是唯一的。在 Go 中,map 是基于哈希表的数据结构:一个数组,其中每个元素都是指向键值对存储桶的指针,如图所示:
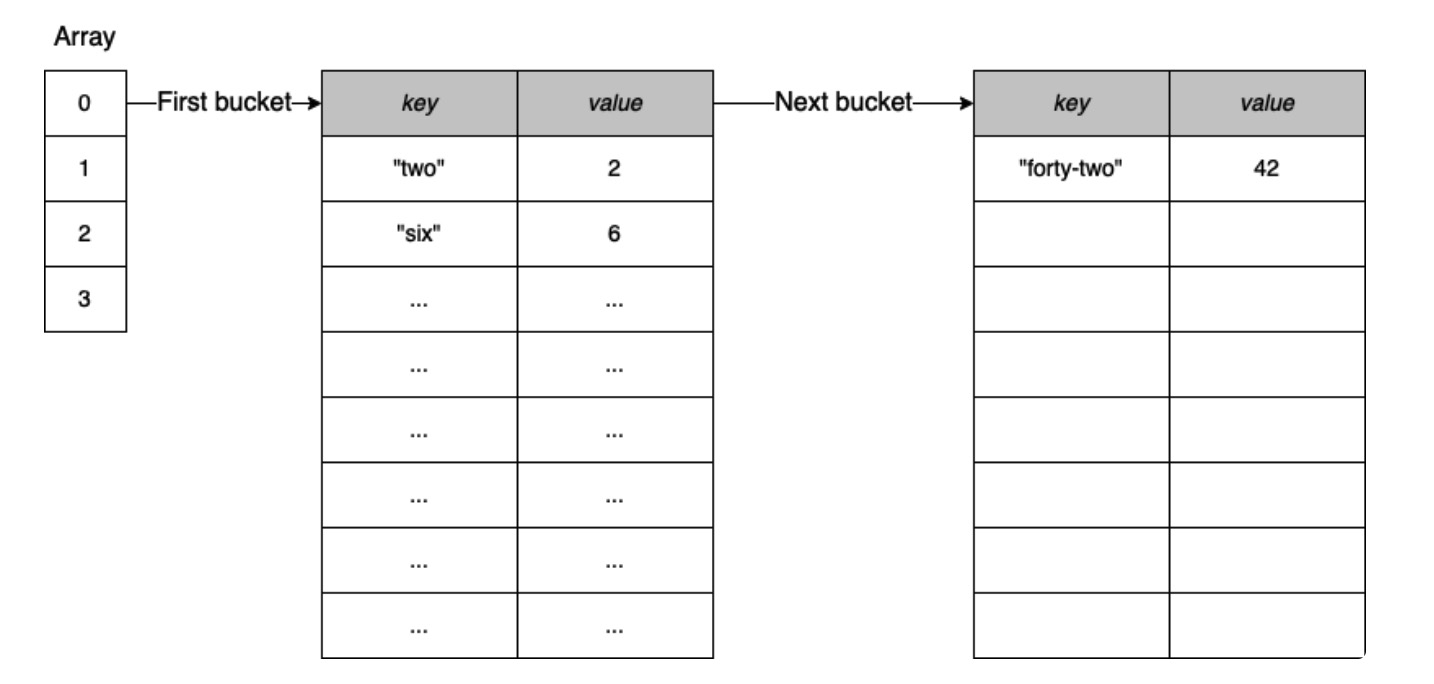 每个存储桶都是一个固定大小的数组,包含8个元素(键值对)。如果要将元素插入已经满了的存储桶(即存储桶溢出),Go 会创建另一个包含八个元素的存储桶,并链接到将前一个存储桶上。
每个存储桶都是一个固定大小的数组,包含8个元素(键值对)。如果要将元素插入已经满了的存储桶(即存储桶溢出),Go 会创建另一个包含八个元素的存储桶,并链接到将前一个存储桶上。
在底层,Go 中的map是指向 runtime.hmap 结构体的指针。该结构体包含多个字段,其中包括一个 B 字段,表示map中存储桶的数量(2^B^):
|
|
在添加了100万个元素之后,map 至少需要 1 000 000 / 8 = 125000个存储桶(2^B^ * 8 >= 1 000 000)B的值等于17(2^17^ = 131072),这意味着此时 map 至少有 2^17^ = 131072 个存储桶用于存放插入的 1 000 000 个元素(键值对)。
当我们删除了100万个元素后,B 的值是多少呢?仍然是17,map仍然包含相同数量的存储桶。原因在于map中存储桶的数量是不可缩减的。
因此,从map中删除元素不会影响现有存储桶的数量;它只是将存储桶中的槽清零。map只能增长并拥有更多的存储桶;它永远不会缩小(map 不会自动回收 存储桶)。
在前面的示例中,我们从461 MB减少到了293 MB,这是因为元素被收集,但运行垃圾回收并没有影响map本身,即使那些额外存储桶的数量(因为溢出而创建的存储桶)也保持不变。
现在弄清楚了map 存储桶只会增长、不会减少的特性后,讨论map无法缩小的情况何时可能成为问题;
想象一下使用 map[int][128]byte 来构建缓存。这个map以每个客户ID(int)为键,保存一个长度为128字节的序列。现在,假设我们想保存最近的1000位客户。map的大小将保持不变,所以我们不必担心map无法缩小的问题。
但是,假设我们想要存储一小时的数据。如果,我们的公司决定在某一天进行大促销活动:在一个小时内,可能会有数百万的客户连接到我们的系统。但是在促销活动结束之后,我们的map将一直包含与高峰期相同数量的存储桶(实际存储一小时的数据量远远小于高峰时的数据量),直至我们服务进程重新启动。这就解释了为什么在这种情况下map数据结构可能会遇到内存消耗高却不会显著减少的情况。
map数据结构内存消耗高却不会显著减少问题的解决方案:
- 1)手动重启服务来清理map消耗的内存量(不推荐,会中断服务);
- 2)定期重新创建当前map的副本,例如,每小时构建一个新map,复制旧map所有元素,并释放先前的map;主要缺点是,在复制后直到下一次垃圾回收之前,我们可能会在短时间内消耗两倍于当前内存。
- 3)将map类型更改为存储数组指针:
map[int]*[128]byte。这并没有解决会有大量存储桶的问题;然而,每个存储桶条目将只需为值保留指针的大小,而不是128字节(64位系统上为8字节,32位系统上为4字节)。
回到原始场景,让我们修改map的元素类型为数字指针后观察在每个步骤后的内存消耗:
|
|
运行结果:
|
|
以下表格显示了比较:
| Step | map[int][128]byte | map[int]*[128]byte |
|---|---|---|
| 分配一个空的 map | 0MB | 0MB |
| 添加100万个元素 | 461MB | 180MB |
| 删除所有元素并运行GC | 293MB | 38MB |
正如我们所看到的,在删除所有元素后,使用 map[int]*[128]byte 类型所需的内存量明显较少。此外,在这种情况下,由于一些优化措施以减少内存消耗,高峰时期所需的内存量也较少显著。
注意:如果键或值超过128字节,Go 将不会直接将其存储在map存储桶中。相反,Go 将存储用于引用键或值的指针。
map使用总结:
- 向map添加 n 个元素,然后删除map中所有元素意味着在内存中将继续保持与删除前相同数量的存储桶。
- 因此,必须记住,由于 Go map 的存储桶只能增长,因此其内存消耗也会随之增加。它没有自动化的策略来缩小存储桶数量(释放存储桶占用的内存)。
- 如果这导致了内存消耗过高,可以尝试不同的选项进行优化,比如强制 Go 重新创建map 或 存储指向大对象的指针 来代替直接存储大对象数据(这样删除元素后大对象会被GC)。
5.4 未关闭的文件或网络连接句柄
如果程序打开了文件句柄或网络连接句柄(TCP连接、HTTP请求连接、DB连接等)但没有关闭它们,那么这些文件句柄、网络连接句柄所占用的内存就无法被回收,可能会导致内存泄漏。
5.5 对象的循环引用
如果两个或多个对象相互引用,且没有其它对象引用它们,那么它们就会被垃圾回收机制误认为是仍在使用的对象,导致内存泄漏。
5.6 大规模全局变量
在Golang中,全局变量的生命周期与程序的生命周期相同,一个全局变量被创建后一直存在于内存中,那么它所占用的内存就无法被回收,直至进程结束。
- 程序中创建大数据量类型的全局变量可能会占用过多内存,如切片 或 map等集合类型全局变量一直在增长,有可能导致内存泄漏;
- 程序中创建大量的全局变量会一直占用内存空间;
5.7 大量的临时对象
- 程序进程创建了大量的临时对象,但没有及时释放它们,那么这些对象所占用的内存就无法被回收,可能会导致内存泄漏。
- 程序进程创建了大量的临时对象,但是释放的速度小于创建的速度,那么进程占用的内存空间就会越积累也多,最终可能影响进程的性能 或 导致进程 OOM。