一、Golang 中的协程(Goroutine)以及主线程
1.1 Golang 中的协程(Goroutine)简介
Golang 中 协程(Goroutine) 可以理解为 用户级线程,它们是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的。
Golang 的一大特色就是 从语言层面原生支持协程,在函数或者方法前面加 go 关键字就可创建一个协程(goroutine)。
Golang 程序中 main 函数运行的线程称为 主线程(可以理解为线程 / 也可以理解为进程),在一个 Golang 程序的主线程上可以 使用 go 关键字 起多个 goroutine 运行。在 goroutine 中还可继续 使用 go 关键字创建新的 goroutine。
Golang 中多个 goroutine 可以实现程序的并行或者并发。
Golang 中的多协程有点类似其它语言中的多线程。
Golang 中每个 goroutine (协程) 默认占用内存远比 Java 、C 的线thread程少。 OS 线程(操作系统线程thread)一般都有固定的栈内存(通常为 2MB 左右),一个 goroutine (协程) 占用内存非常小,只有 2KB 左右,多协程 goroutine 切换调度开销方面远比线程要少,这也是为什么越来越多的大公司使用 Golang 的原因之一。
1.2 Goroutine 的使用
Golang 中 使用 go 关键字调用 函数/方法 运行 就是创建启动一个新的 goroutine。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import(
"fmt"
"time"
)
func test() {
for i := 0; i < 10; i++ {
fmt.Println(i, "test() goroutine...")
time.Sleep(time.Millisecond * 100)
}
}
func main(){ // main 函数为进程的主线程,也称之为主程
go test() // 使用 go 关键字调用 test 函数运行 即 创建启动一个新的 goroutine。
// 在主线程中也每隔10毫输出信息, 输出2次后,退出程序
for i := 1; i <=2; i++ {
fmt.Println(i, "main goroutine...")
time.Sleep(time.Millisecond*10)
}
}
/* 输出:
1 main goroutine...
0 test() goroutine...
2 main goroutine...
*/
|
从输出结果看:
- 主线程执行完毕后即使协程没有执行完毕程序也会退出;
- 主线程可以在协程没有执行完毕前提前退出,协程是否执行完毕不会影响主线程的执行;
为了保证程序可以顺利让协程执行完毕后主进程再退出,可以使用 sync.WaitGroup 等待协程执行完毕。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
package main
import(
"fmt"
"time"
"sync"
)
//主线程退出后所有的协程无论有没有执行完毕都会退出,所以我们在主进程中可以通过WaitGroup等待协程执行完毕
var sw sync.WaitGroup
func test() {
for i := 0; i < 5; i++ {
fmt.Println("test goroutine...")
time.Sleep(time.Millisecond * 100)
}
sw.Done() //协程计数器-1
}
func main(){ // main 函数为进程的主线程,也称之为主程
sw.Add(1) //协程计数器+1// main 函数为进程的主线程,也称之为主程
go test() // 使用 go 关键字调用 test 函数运行 即 创建启动一个新的 goroutine。主线程和goroutine同时执行
// 在主线程中也每隔10毫输出信息, 输出2次后,退出程序
for i := 1; i <=2; i++ {
fmt.Println(i, "main goroutine...")
time.Sleep(time.Millisecond*10)
}
sw.Wait() //等待协程执行完毕...
fmt.Println("主线程执行完毕。")
}
/* 输出:
1 main goroutine...
test goroutine...
2 main goroutine...
test goroutine...
test goroutine...
test goroutine...
test goroutine...
主线程执行完毕。
*/
|
启动多个 Goroutine
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
package main
import(
"fmt"
"time"
"sync"
)
// 多个协程Goroutine启动
var sw sync.WaitGroup
func test0() {
for i := 0; i < 5; i++ {
fmt.Println("test0 goroutine...")
time.Sleep(time.Millisecond * 100)
}
sw.Done() //协程计数器-1
}
func test1() {
for i := 0; i < 5; i++ {
fmt.Println("test1 goroutine...")
time.Sleep(time.Millisecond * 100)
}
sw.Done() //协程计数器-1
}
func main(){
sw.Add(1) //协程计数器+1
go test0()//表示开启一个协程
sw.Add(1)//协程计数器+1
go test1()//表示开启一个协程
for i := 1; i <=2; i++ {
fmt.Println("main goroutine...")
time.Sleep(time.Millisecond*10)
}
sw.Wait() //等待协程执行完毕...
fmt.Println("主线程执行完毕。")
}
|
多次执行上面的代码,会发现每次打印的数字的顺序都不一致。这是因为 2 个 goroutine 是并发执行的,而 goroutine 的调度是随机的。
1.3 设置 Golang 并行运行占用的 CPU 数量
Go 运行时的调度器使用 GOMAXPROCS 参数来确定需要使用多少个 OS 线程来同时执行 Go 代码,默认值是机器的 CPU 核心数。例如在一个 8 核心的机器上,调度器会把 Go 代码同时调度到 8 个 OS 线程上。
Go 语言中可以通过 runtime.GOMAXPROCS() 函数设置当前程序并发时占用的 CPU 逻辑核心数。
Go1.5 版本之前,默认使用的是单核心执行,Go1.5 版本之后,默认使用全部的 CPU 逻辑核心数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
package main
import (
"fmt"
"runtime"
)
func main() {
//获取当前计算机上面的Cup个数
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum)
//可以自己设置使用多个cpu
runtime.GOMAXPROCS(cpuNum - 1)
fmt.Println("设置完成")
}
//cpuNum= 8
//设置完成
|
二、Channel 通道概述
2.1 Channel 通道的作用
在Go语言中,channel(通道) 是一种在语言级别上提供的用于在 goroutine 之间进行通信和同步的特殊数据结构,它可以看作是一条管道,可以在不同的goroutine之间传递数据。
channel(通道) 是可以让一个 goroutine 发送特定值到另一个 goroutine 的通信机制,channel(通道) 提供了一种安全、同步的方式来共享数据,它确保在发送操作完成之前,接收操作会一直等待,并且在接收操作完成之前,发送操作也会一直等待,这种同步机制可以有效地避免并发访问共享数据时出现的竞争条件和数据竞争。
Golang并发的核心是不要通过共享内存进行通信,所以数据在不同协程中的传输都是通过拷贝的形式完成的。
 上图中的两个 Goroutine,一个会向 Channel 中发送数据,另一个会从 Channel 中接收数据,它们两者能够独立运行并不存在直接关联,但是能通过 Channel 间接完成通信。
上图中的两个 Goroutine,一个会向 Channel 中发送数据,另一个会从 Channel 中接收数据,它们两者能够独立运行并不存在直接关联,但是能通过 Channel 间接完成通信。
Golang 中 Channel 收发操作均遵循了先进先出的的规则来保证收发数据的顺序一致,具体规则如下:
- 先写入 Channel 的数据 会先被读取出Channel;
- 先从 Channel 读取数据的 Goroutine 会先接收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
基于先入先出(FIFO) 的思想,使得 Channel 确保了接收的数据和发送的数据的顺序一致性。
每一个 channel(通道) 都是一个具体类型的管道,也就是声明 channel 的时候需要为其指定传输的元素类型。
2.2 Channel 的特性
对于 channel 的异常操作,空读写阻塞,写关闭异常,读关闭空零,关闭 nil 或 closed 的channel 将异常。
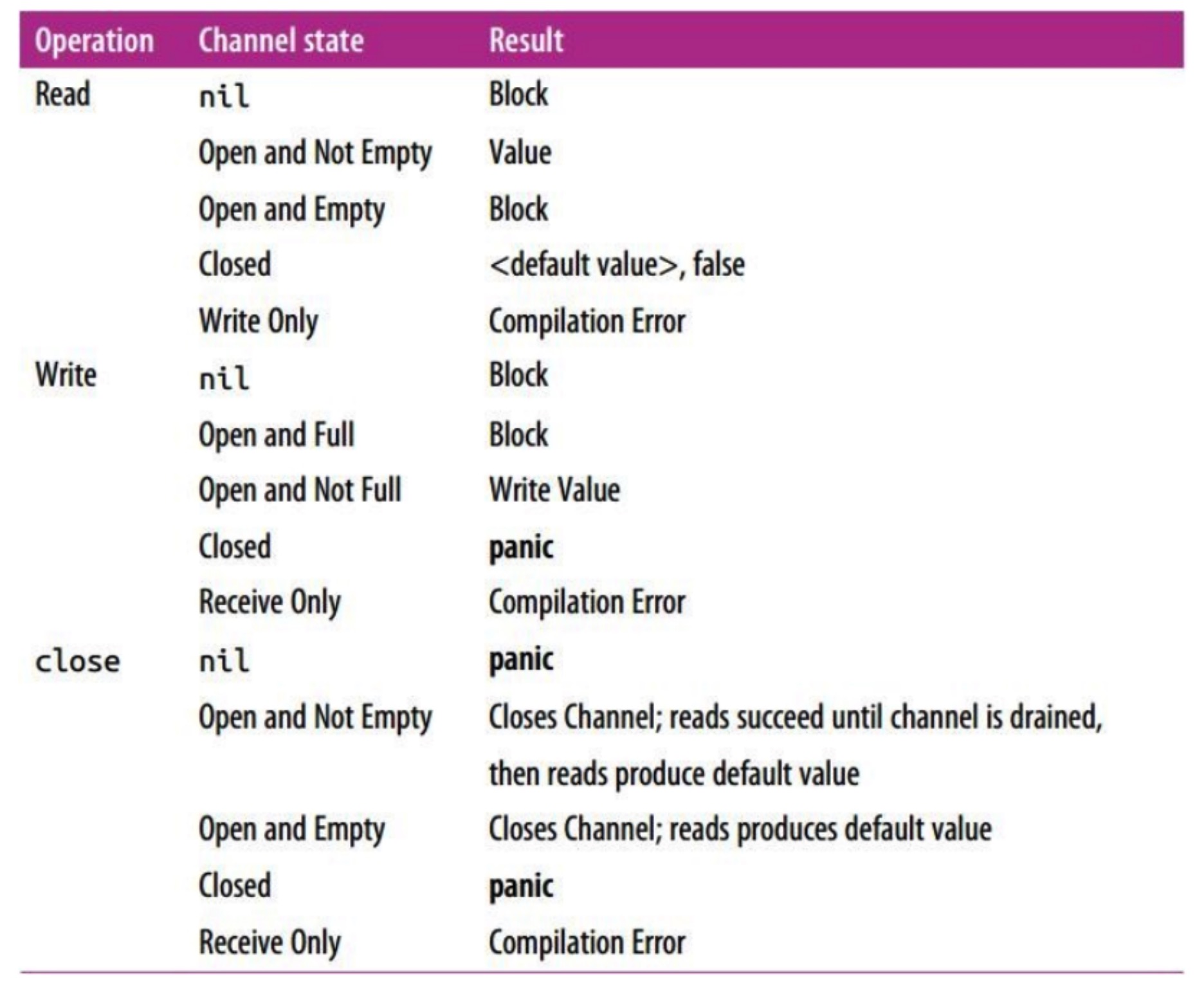 1、channel的状态
1、channel的状态
- nil 未初始化的状态,只进行了声明(做了 var chan Type 声明操作但是没有进行 make初始化),或者手动赋值为 nil;
- active/open 正常的 channel(make后的有缓冲或者无缓冲channel),可对 channel 进行 读
<- channel、写 channel <- data 或者 关闭 close(channel) 操作;
- closed 已关闭,千万不要误认为关闭channel后,channel的值是nil,关闭的 channel 还可以继续进行 读操作;
2、对未初始化的状态(nil)channel 的读、写、关闭操作
- 对未初始化的状态(nil)channel 的读写操作将导致 goroutine 阻塞;
- 对未初始化的状态(nil)channel 的关闭操作将导致 进程 panic;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
package main
import (
"fmt"
"time"
)
var nilChan chan int
// 对 空(nil)管道 读操作 将阻塞 goroutine,直至有其它 goroutine 初始化(make)管道 并对其 写操作
// 在主 goroutine 对空(nil)管道读将阻塞 goroutine,可能导致程序死锁:
// fatal error: all goroutines are asleep - deadlock!
func nilChanRead(){
fmt.Println("nilChanRead\n")
// 运行错误同上
// 编译器提醒 Receive may block because of 'nil' channel 从nil channel获取数据阻塞
<- nilChan
fmt.Println("nilChanRead1\n")
}
// 对 空(nil)管道 写操作 将阻塞 goroutine,直至有其它 goroutine 初始化(make)管道 并对其 读操作
// 在主 goroutine 对空(nil)管道写将阻塞 goroutine,可能导致程序死锁:
// fatal error: all goroutines are asleep - deadlock!
func nilChanWrite(){
fmt.Println("nilChanWrite\n")
// 编译器提醒 Send may block because of 'nil' channel 会向一个nil channel发送数据阻塞
nilChan <- 1
fmt.Println("nilChanWrite1\n")
}
// 对 空(nil)管道 关闭操作 将导致 进程 crash 并报错误:panic: close of nil channel
func nilChanClose(){
fmt.Println("nilChanClose\n")
fmt.Printf("nilChanClose: %p\n", &nilChan)
// 执行 close 操作时,如果 nilChan 任未make初始化,
// 进程将 crash 并报错误:panic: close of nil channel
close(nilChan)
fmt.Println("nilChanClose1\n")
}
func main() {
fmt.Printf("main: %p\n", &nilChan)
go nilChanRead()
go nilChanWrite()
go nilChanClose()
// 如果先执行 go nilChanClose(),后初始化 nilChan,可能可以正常 close
// nilChan = make(chan int)
time.Sleep(2*time.Second)
}
|
3、对关闭状态(closed)channel 的读、写、关闭操作
-
读已经关闭的 channel 操作(val, ok := <- channel ):
- 如果 channel 中还有未读取的数据,读操作将正常读取到数据(ok == true);
- 如果 channel 中没有未读取的数据,读操作将失败(ok == false) 并得到 零(空)值;
-
写已经关闭的 channel 操作将导致程序:panic: send on closed channel
-
关闭已经关闭的 channel 操作将导致程序:panic: close of closed channel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
package main
import (
"fmt"
"time"
)
// 读关闭空零(nil channel):读取已经关闭的空的 管道将操作失败并读取到 零值
func readClosed(){
// 读关闭空零 读关闭的int->0 string->"" struct->{}
chnClose := make(chan int, 1)
chnClose <- 0
close(chnClose)
d, ok := <- chnClose // chnClose 中还有未读取的数据,读操作将正常读取到数据(ok == true)
fmt.Println("readClose: ", d, ok) // readClosed: 0 true
d, ok = <- chnClose // chnClose 中没有未读取的数据,读操作将失败(ok == false) 并得到 零(空)值
fmt.Println("readClose: ", d, ok) // readClosed: 0 false
}
// 写关闭异常(nil channel)
func writeClosed(){
chnClose := make(chan int, 1)
close(chnClose)
// 向已经关闭的 channel 写操作将导致程序:panic: send on closed channel
chnClose <- 1
fmt.Println(chnClose)
}
// 关闭已经关闭的 channel 操作将导致程序:panic: close of closed channel
func closeClosed(){
// 读关闭空零 读关闭的int->0 string->"" struct->{}
chnClose := make(chan int, 1)
close(chnClose)
d, ok = <- chnClose // chnClose 中没有未读取的数据,读操作将失败(ok == false) 并得到 零(空)值
fmt.Println("readClose: ", d, ok) // readClosed: 0 false
close(chnClose) // 关闭已经关闭的 channel 操作将导致程序:panic: close of closed channel
}
// 判断 chan 是否关闭
func isClosedChan() {
c := make(chan int, 10)
c <- 0
c <- 1
c <- 2
c <- 3
close(c)
for {
i, ok := <-c
fmt.Println("read chan:", i, ok)
if !ok {
fmt.Println("channel closed!", ok)
break
}
}
}
func main() {
readClosed()
isClosedChan()
writeClosed()
closeClosed()
fmt.Printf("main over...\n")
}
|
对 channel 操作引起 panic出现的场景有:
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据
2.3 Channel 的基本操作(使用)
1、channel 的声明:
chan 是声明通道变量的关键字。
未初始化的 Channel 类型变量默认为零值(nil), 声明语法为:
- varName 为通道对象(变量)名
- Type 为通道的元素数据类型
Tips: 向未初始化的 chan 发生数据 将导致 goroutine 一直阻塞(即使其它goroutine 使用make 初始化了 该chan)
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package main
import "fmt"
import "time"
var ch1 chan int // 声明一个传递整型的通道
var ch2 chan bool // 声明一个传递布尔型的通道
var ch3 chan []int // 声明一个传递int切片的通道
func main() {
var ch chan int
go func () {
fmt.Println("goroutine running..")
ch <- 10 // 向未初始化的 chan 发送数据 将导致 goroutine 一直阻塞(即使后续其它 goroutine 使用make 初始化了 该chan)
fmt.Println("goroutine over..")
}()
fmt.Println("Main running..")
time.Sleep(3*time.Second)
ch = make(chan int)
fmt.Println("Sleep")
time.Sleep(3*time.Second)
}
|
2、channel 初始化
通道类型变量 是引用类型,需要使用 make 进行创建。
声明 Channel 类型的变量后,需要使用 make() 函数初对其进行始化(创建)操作之后才能使用,语法为:
1
2
3
4
5
|
var ch chan Type
ch = make(chan Type, [N])
// 或者简写为
ch1 := make(chan Type, [N])
|
- Type 为通道的元素数据类型
- N 缓冲大小, 该参数可选参数 表示创建无缓存通道
示例:
1
2
3
4
|
var ch1 chan Type
ch1 = make(chan bool) // 创建无缓冲通道
// 或
ch2 := make(chan bool, 1) // 创建缓冲大小为1的通道
|
2、channel 的操作
channel 一般有发送(send)、接收(receive)和关闭(close)三种操作。
阻塞接收数据 和 非阻塞接收数据(select):
- 阻塞接收数据 阻塞 goroutine 直至有数据可读;
- 非阻塞接收数据(select)可以在没有数据可读时也可以 立即返回 或 结合计时器超时返回;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
// 阻塞接收数据 方式一
<- ch
data1 := <-ch
data2, ok := <-ch
// 为了能知道当前 channel 是否被关闭,可以使用下面的写法来判断。
if v, ok := <-ch; !ok {
fmt.Println("channel 已关闭,读取不到数据")
}
// 阻塞接收数据 方式二
// 使用 loop 写法不断的获取 channel 里的数据,这种方式可能会造成高cpu, 使用较少。
package main
import "fmt"
import "time"
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
go func () {
for t := range ch { // 如果 ch 中有数据一直读,如果ch 没数据则阻塞,ch 关闭 则结束循环
fmt.Println(t)
}
fmt.Println("goroutine over...")
}()
ch <- 4
ch <- 5
ch <- 6
// close(ch)
time.Sleep(3 * time.Second)
fmt.Println("main over...")
}
// 非阻塞接收数据(select)方式一:不管是否读到数据都立即返回
select {
case ack:= <- ch:
return ack, nil
default :
return 0, "Timeout"
}
// 非阻塞接收数据(select)方式二:实现接收超时检测,可以使用 select 和 计时器
select {
case ack:= <- ch:
return ack, nil
case <- time.After(time.Second):
return "", errors.New("time out")
}
|
使用 select 写法来可以用来管理多个 channel 的通信数据,如上面的 两个case 为不同的channel。
通道创建后,就可以使用通道进行发送(send)、接收(receive)和关闭(close)三种操作。
1
2
3
4
5
6
7
8
9
10
11
12
|
// 发送语法:
chanObj <- [dataObj]
// 接收语法:
varName := <- chanObj // 从通道中接收值并赋值给 varName变量
// 或者
varName, ok := <- chanObj // 从通道中接收值并赋值给 varName变量,并判断是否接受成功
// 或者
<- chanObj // 从通道中接收值,忽略结果
// 关闭语法:
close(chanObj)
|
- 从 chan 接收数据操作可以直接获取接收值,同时也可以 获取到 通道接收操作的状态(成功 或 失败)
- chanObj 为初始化了的 chan 对象(变量)
- dataObj 为要发生的数据对象
- varName 为 接收通道中发送的数据的变量
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
cha := make(chan int) // 创建无缓冲通道
// 发送
cha <- 10 // 将10发送到cha中
// 接收
x := <- cha // 从cha中接收值并赋值给x变量
x1, ok := <- cha // 从cha中接收值并赋值给x变量, 如果成功 ok 为true、x1 为从管道中接收到的值,
// 如果失败 ok 为 false、x1 为管道元素类型的 0 值
<- cha // 从cha中接收值,忽略结果
// 关闭
close(cha)
|
关于关闭通道需要注意的事情是,只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
2.4 缓冲通道 与 通道阻塞
Golang 中 Channel 按有无缓冲(buffer)可以分成 有缓冲Channel 与 无缓冲Channel,通过 make(chan Type, N) 来定义一个带有 buffer 的 channel,如果 N为0或者省略不填,则创建的为 无缓冲Channel,否则就是带有 N个单元的有缓冲Channel。
- 无缓冲 Channel
创建 chan 的时候没有指定容量的 chan 称为无缓冲的chan,又称为 阻塞的chan。
1
2
3
4
5
|
func main() {
ch := make(chan int) // make(chan int) 创建的就是无缓冲通道
ch <- 10
fmt.Println("发送成功")
}
|
以上代码执行会报错: fatal error: all goroutines are asleep - deadlock! 表示程序中的 goroutine 都被挂起导致程序死锁了。
造成死锁的原因: 无缓冲通道必须至少有一个接收方才能发送成功,同理至少有一个发送放才能接收成功。
使用 ch := make(chan int) 创建的是无缓冲的通道,无缓冲的通道只有在有人接收值的时候才能发送值。
因为此类通道没有提示进行接收操作,程序执行到 ch <- 10 会阻塞,但是如果这时创建了一个goroutine 进入recv,recv函数中有接收操作,最后代码就可以执行完毕结束:
1
2
3
4
5
6
7
8
9
10
11
|
func recv(c chan int) {
ret := <-c
fmt.Println("接收成功", ret)
}
func main() {
ch := make(chan int)
go recv(ch) // 创建一个 goroutine 从通道接收值
ch <- 10
fmt.Println("发送成功")
}
|
无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。
如下只有接收操作,没有发送同样会报错: fatal error: all goroutines are asleep - deadlock! 表示程序中的 goroutine 都被挂起导致程序死锁了。
1
2
3
4
5
|
func main() {
ch := make(chan int) // make(chan int) 创建的就是无缓冲通道
<- ch
fmt.Println("接收成功")
}
|
使用无缓冲通道进行通信将导致发送和接收的 goroutine 同步化。因此,无缓冲通道也被称为同步通道。
- 有缓冲 Channel
只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。
1
2
3
4
5
6
7
8
|
func main() {
ch := make(chan int, 2) // 创建一个容量为2的有缓冲区通道
ch <- 10
fmt.Println("发送成功")
ch <- 11
ch <- 12 // 如果一直没有其它goroutine对 ch 进行 接收,则此处将因为管道发送数据占满缓冲,
// 导致发送操作的 groutine 阻塞,直到 有其它goroutine 从 ch 中接收了数据,腾出缓冲空间
}
|
如果当通道内已有元素数达到最大容量后,再向通道执行发送操作就会阻塞,除非有从通道执行接收操作。
同理,从发送过数据的缓冲 chan 中 接收数据 或接收完缓冲 chan 中的数据后继续接收数据,也将导致 groutine 阻塞,直到 有其它goroutine 向 chan 中发送数据数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func main() {
ch := make(chan int, 2) // 创建一个容量为2的有缓冲区通道
<- ch // 如果没有其它goroutine对 ch 进行发送数据操作,则此处将因为缓冲管道中数据为空,
// 导致此 groutine 阻塞,直到 有其它goroutine 向该 ch 中发送数据,此处接收操作才能得到执行。
fmt.Println("接收成功")
ch1 := make(chan int, 2) // 创建一个容量为2的有缓冲区通道
go func () {
ch1 <- 10
}()
<- ch1 // 此处 接收操作将在前面goroutine 中 发送数据操作完成后得到执行
<- ch1 // 此处 接收操作将因为缓冲管道中数据为空,导致此 groutine 阻塞,
// 直到 有其它goroutine 向该 ch 中发送数据,此处接收操作才能得到执行
}
|
2.5 单向通道
在Go语言中,通道(channel)可以被声明为单向通道,即只允许发送或接收数据。单向通道可以用于限制通道的使用范围,增加代码的可读性和安全性。
声明单向通道的语法如下:
1
2
3
4
5
|
// 发送通道(Send-only Channel)的声明语法
var sendChanNmae chan<- Type
// 接收通道(Receive-only Channel)的声明语法
var recvChanName <-chan Type
|
单向通道的类型是基于普通的双向通道类型而来的。因此,需要首先创建一个双向通道,然后使用类型转换将其转换为单向通道。
例如,如果想声明一个只允许发送数据的通道,可以按照以下步骤进行声明和初始化:
1
2
|
var ch chan<- int
ch = make(chan int)
|
类似地,如果想声明一个只允许接收数据的通道,可以按照以下方式进行声明和初始化:
1
2
|
var ch <-chan int
ch = make(chan int)
|
单向通道的实际用途在于函数参数和返回值中,用于限制通道的使用范围,并提高代码的可读性和安全性。在一般情况下,应该使用双向通道来进行通信和同步操作。
2.6 通道(channel)的多返回值模式
在Go语言中,通道(channel)可以用于实现多返回值的机制。通道的使用使得在函数之间传递多个返回值变得更加简洁和灵活。
通常情况下,Golang 一个函数返回一个值,如果要返回多个值,需要一一列出要返回的多个值,但是通过使用通道,可以将多个值封装在一个通道中,然后在调用方进行接收,这种方式使得函数返回多个值,就像返回一个值一样,而不需要显式地声明多个返回类型。
下面是一个示例,演示了如何在函数中使用通道实现多返回值的机制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func computeSumAndProduct(a, b int) <-chan int {
resultChan := make(chan int)
go func() {
sum := a + b
product := a * b
resultChan <- sum
resultChan <- product
close(resultChan)
}()
return resultChan
}
func main() {
values := computeSumAndProduct(2, 3)
sum := <-values
product := <-values
fmt.Println("Sum:", sum)
fmt.Println("Product:", product)
}
|
在上面的示例中,定义了一个名为 computeSumAndProduct 的函数,它接收两个整数参数 a 和 b,并返回一个只允许接收整数的通道。
需要注意的是:
- 当向通道发送完数据时,通过close函数来关闭通道,当一个通道关闭后再向其发送数据会引发panic。
- 取值操作会先取完通道中的值,取完之后在执行接受操作得到的都是对应元素的0值,如果有发生 0值的情况,需要对 通道接收状态做判断,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
func computeSumAndProduct(a, b int) <-chan int {
resultChan := make(chan int)
go func() {
sum := a + b
product := a * b
resultChan <- sum
resultChan <- product
resultChan <- 0
close(resultChan)
}()
return resultChan
}
func main() {
values := computeSumAndProduct(2, 3)
sum, _ := <-values // 忽略接收状态
product, _ := <-values // 忽略接收状态
val0, ok := <-values // 接收状态存入ok中
val, ok := <-values // 接收状态存入ok中
fmt.Println("Sum:", sum) // Sum: 5
fmt.Println("Product:", product) // Product: 6
fmt.Println("val0:", val0, ", ok: ", ok) // val0: 0, ok: true
fmt.Println("val:", val, ", ok: ", ok) // val: 0, ok: false —— 表示通道已经关闭
}
|
2.7 Channel 底层数据结构
Go 语言的 Channel 在运行时使用 runtime.hchan 结构体(源码runtime/chan.go )表示。在 Go 语言中创建新的 Channel 时,实际上创建的都是如下所示的结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type hchan struct {
qcount uint
dataqsiz uint
buf unsafe.Pointer
elemsize uint16
closed uint32
elemtype *_type
sendx uint
recvx uint
recvq waitq
sendq waitq
lock mutex
}
|
- hchan.qcount: 当前通道中元素的数量,即通道中待接收的元素个数
- hchan.dataqsize: 通道的容量,即通道可以容纳的最大元素个数,即make(chan T,N) 中的N
- hchan.buf: 指向通道的缓冲区的指针,实际存储通道元素的地方
- hchan.elemsize: 每个元素的大小(以字节为单位)
- hchan.closed: 标志通道是否已关闭的标识。当通道关闭时,该字段的值为非零
- hchan.elemtype: 元素类型的指针,指示通道中存储的元素类型
- hchan.sendx: 环形缓冲区的状态字段,Channel 的下一个发送操作应该写入的位置,即发送索引
- hchan.recvx: 环形缓冲区的状态字段,Channel 的下一个接收操作应该读取的位置,即接收索引
- hchan.recvq: 接收等待队列,用于阻塞等待接收操作的goroutine
- hchan.sendq: 发送等待队列,用于阻塞等待发送操作的goroutine
- hchan.lock: 用于保护对通道进行并发访问的互斥锁
runtime.hchan的结构图如下:
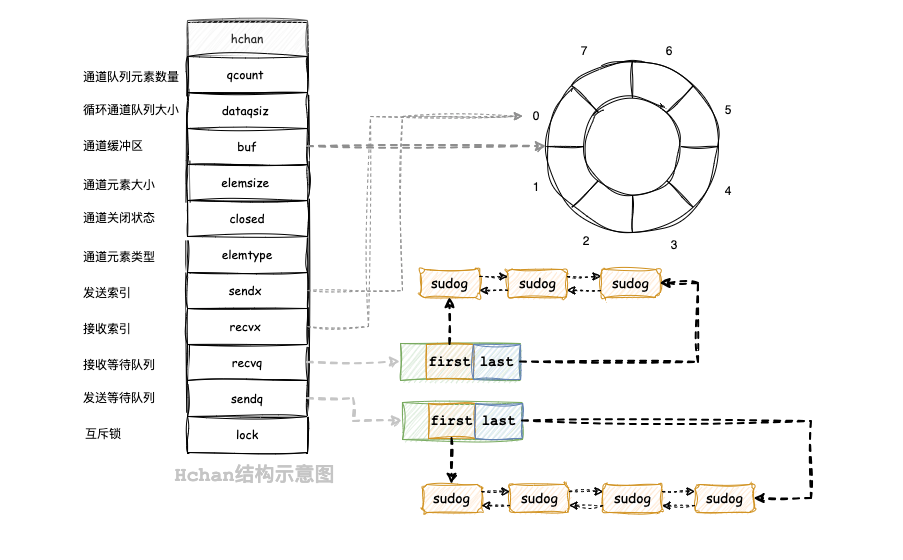 该示意图只是展示相关字段对应的数据关联结构,具体的各个字段的配合后续具体操作会详细讲解。
该示意图只是展示相关字段对应的数据关联结构,具体的各个字段的配合后续具体操作会详细讲解。
环形队列(Circular Queue)
通道(channel)在底层实现上使用了环形队列(Circular Queue)的数据结构,以实现高效的数据传输和同步机制。
通道的环形队列主要由以下字段组成:
- buf: 指向环形队列的缓冲区的指针。缓冲区是一个连续的内存块,用于存储通道中的元素。
- sendx:发送操作的索引,表示下一个元素应该写入的位置。
- recvx:接收操作的索引,表示下一个元素应该读取的位置。
环形队列(Circular Queue)通过循环利用缓冲区中的空间,实现了高效的数据传输和存储:
- 当发送操作发生时,元素将被写入缓冲区的当前 sendx 位置,并将 sendx 递增;
- 当接收操作发生时,元素将从缓冲区的当前 recvx 位置读取,并将 recvx 递增;
- 当 sendx 和 recvx 达到缓冲区的边界时,它们将通过取模运算返回到缓冲区的起始位置,形成了环形的特性;
下图列出环形队列的各种状态:
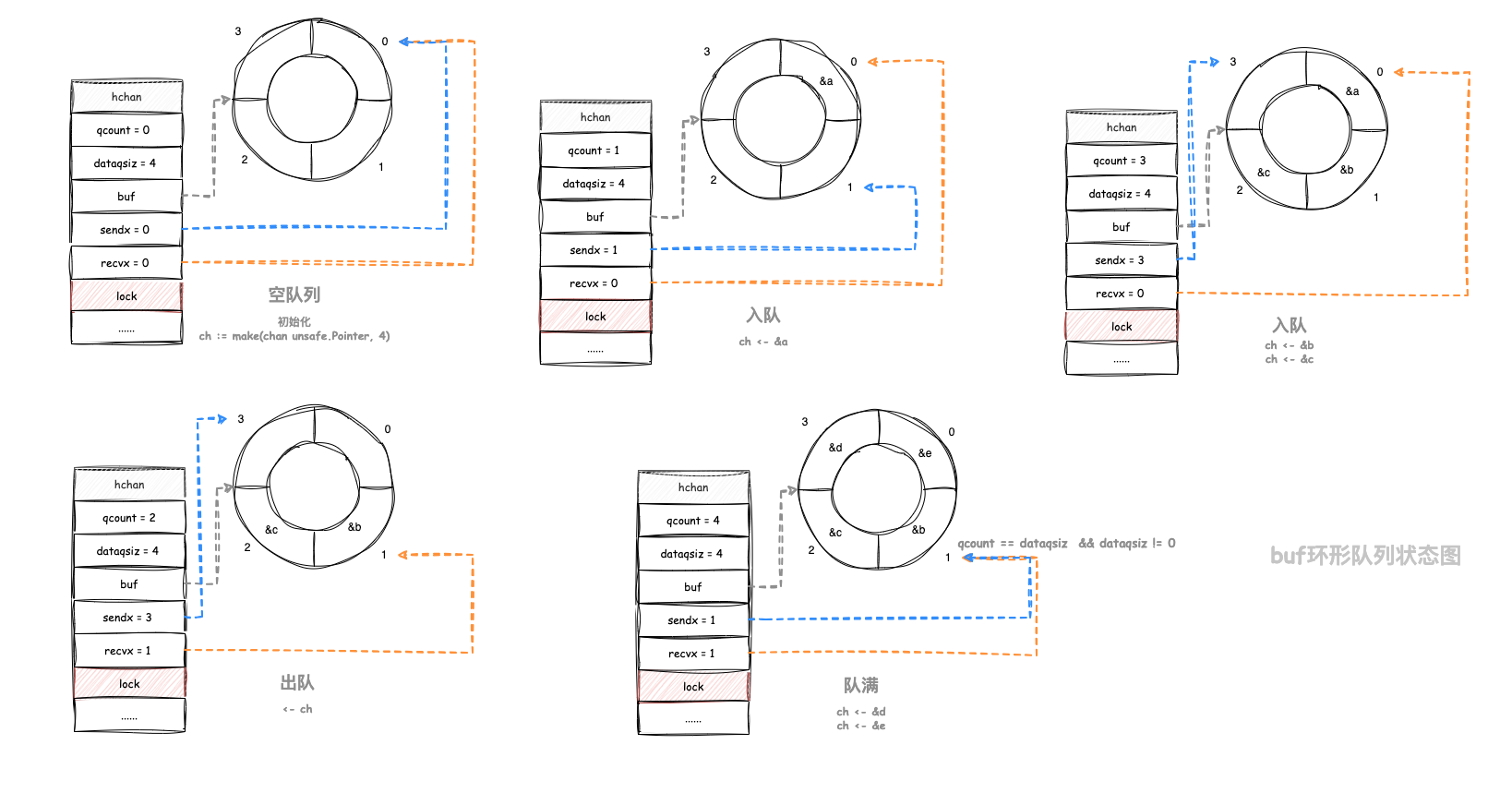 使用环形队列的好处是,可以避免频繁地进行内存分配和释放,提高了数据传输的效率。而且,环形队列的结构可以简单地通过索引运算来实现元素的读写,避免了复杂的指针操作。
使用环形队列的好处是,可以避免频繁地进行内存分配和释放,提高了数据传输的效率。而且,环形队列的结构可以简单地通过索引运算来实现元素的读写,避免了复杂的指针操作。
需要注意的是,Go语言的环形队列在底层实现中是固定大小的数组,大小由通道的容量决定。一旦通道的容量确定,缓冲区的大小也就确定了,并且在通道的生命周期中不会改变。这也是为什么在创建通道时,需要指定通道的容量而不是动态调整容量的原因。
通过使用环形队列,Go语言的通道实现了高效的数据传输和同步机制,为并发编程提供了方便且可靠的工具。
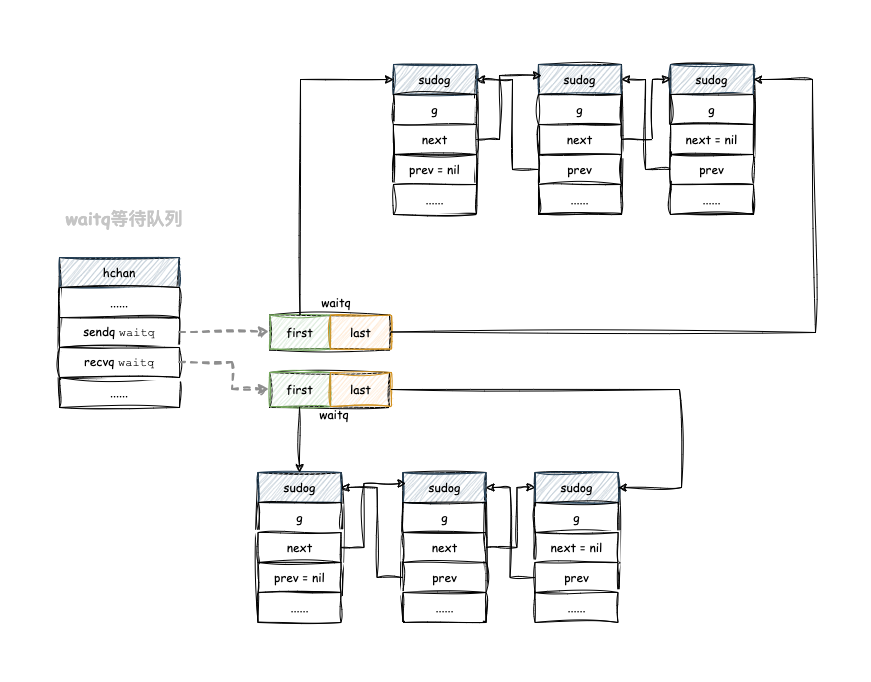
waitq & sudog
在Go语言的通道(channel)实现中,waitq 是一个等待队列,用于管理 等待发送操作 或 接收操作 的 goroutine。它的作用是在通道的 发送 和 接收 操作中提供 阻塞 和 唤醒 的机制。
通道的 发送操作 和 接收操作 可能会导致 goroutine 进入阻塞状态,直到满足特定的条件才能唤醒继续执行。这些条件包括 通道是否已满、是否为空 以及 是否已关闭 等。当条件不满足时,相应的 goroutine 需要被阻塞,并添加到等待队列中,等待条件满足时再被唤醒。
runtime.hchan 结构中的 hchan.sendq 以及 hchan.recvq采用的就是 waitq 结构 :
1
2
3
4
|
type waitq struct {
first *sudog // 指向等待队列中第一个等待的 sudog 结构体的指针
last *sudog // 指向等待队列中最后一个等待的 sudog 结构体的指针
}
|
waitq 结构体用于表示通道(channel)中的等待队列,其中的 sudog 结构体是等待队列中的元素。
通道的等待队列用于管理等待发送操作或接收操作的 goroutine。当一个 goroutine 需要等待发送或接收操作时,它会被封装成一个 sudog 结构体,并添加到等待队列中。等待队列中的 `sudog`` 结构体按照一定的顺序连接起来,形成一个链表结构,以维护等待的顺序。
当满足某个条件时,例如通道已经准备好发送或接收数据,需要从等待队列中选择一个或多个 sudog 结构体,并将它们唤醒,使得相应的 goroutine 可以继续执行。
通过 waitq 结构体的 first 和 last 字段,可以方便地找到等待队列中的第一个和最后一个 sudog 结构体,以支持等待队列的操作,例如添加和移除等待的 goroutine。
通过等待队列的机制,通道能够实现发送和接收操作之间的同步,确保发送和接收的配对正确,并避免竞态条件和数据竞争的问题。
sudog 结构体用于存储等待的 goroutine 相关的信息,如 goroutine 的标识符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
type sudog struct {
g *g // 关联的 goroutine
next *sudog // 下一个 sudog 结构体
prev *sudog // 上一个 sudog 结构体
elem unsafe.Pointer // 元素指针
acquiretime int64 // 获取时间
releasetime int64 // 释放时间
ticket uint32 // 票据(用于调度)
isSelect bool // 是否处于 select 操作
success bool // 操作是否成功
parent *sudog // 父 sudog(用于嵌套等待)
waitlink *sudog // 等待链接(用于等待队列)
waittail *sudog // 等待尾部(用于等待队列)
c *hchan // 关联的通道
}
|
sudog 结构体在Go语言运行时系统中扮演着关键的角色,用于实现通道的阻塞和唤醒操作,以及协程的调度和管理。它通过存储和传递与调度相关的信息,确保并发程序的正确执行和同步。对于通道的使用者来说,通常不需要直接操作或访问sudog 结构体,而是通过使用通道的高级接口进行发送和接收操作。
waitq 等待队列示意图:
创建 channel
Go 语言中所有 Channel 的创建都会使用 make 关键字。编译器会将 make(chan int, 10) 表达式转换成 OMAKE 类型的节点,并在类型检查阶段将 OMAKE 类型的节点转换成 OMAKECHAN 类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
// src/cmd/compile/internal/typecheck/func.go
func tcMake(n *ir.CallExpr) ir.Node {
args := n.Args
......
case types.TCHAN:
l = nil
if i < len(args) {
l = args[i]
i++
l = Expr(l)
l = DefaultLit(l, types.Types[types.TINT])
if l.Type() == nil {
n.SetType(nil)
return n
}
if !checkmake(t, "buffer", &l) {
n.SetType(nil)
return n
}
} else {
l = ir.NewInt(0)
}
nn = ir.NewMakeExpr(n.Pos(), ir.OMAKECHAN, l, nil)
}
if i < len(args) {
base.Errorf("too many arguments to make(%v)", t)
n.SetType(nil)
return n
}
nn.SetType(t)
return nn
}
|
这一阶段会对传入 make 关键字的缓冲区大小进行检查,如果不向 make 传递表示缓冲区大小的参数,那么就会设置一个默认值 0,也就是当前的 Channel 不存在缓冲区。
OMAKECHAN 类型的节点最终都会在 SSA 中间代码生成阶段之前被转换成调用 runtime.makechan`` 或者 runtime.makechan64` 的函数:
1
2
3
4
5
6
7
8
9
10
11
|
// src/cmd/compile/internal/walk/builtin.go
func walkMakeChan(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
size := n.Len
fnname := "makechan64"
argtype := types.Types[types.TINT64]
if size.Type().IsKind(types.TIDEAL) || size.Type().Size() <= types.Types[types.TUINT].Size() {
fnname = "makechan"
argtype = types.Types[types.TINT]
}
return mkcall1(chanfn(fnname, 1, n.Type()), n.Type(), init, reflectdata.MakeChanRType(base.Pos, n), typecheck.Conv(size, argtype))
}
|
runtime.makechan 和 runtime.makechan64 会根据传入的参数类型和缓冲区大小创建一个新的 Channel 结构,其中后者用于处理缓冲区大小大于 2 的 32 次方的情况,因为这在 Channel 中并不常见,所以重点关注 runtime.makechan:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
// src/runtime/chan.go
func makechan(t *chantype, size int) *hchan {
//获取channel类型元数据所在的地址指针
elem := t.elem
/**
编译器会检查类型是否安全,主要检查下面内容:
1. 类型大小大与 1<<16 时会法生异常(即大与65536)
2. 内存对齐,当大与maxAlign(最大内存8字节数)时会发生异常
3. 传入的size大小大与堆可分配的最大内存时会发成异常
*/
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
//获取需要分配的内存
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
//chan的size或元素的size为0,就不必创建buf
case mem == 0:
c = (*hchan)(mallocgc(hchanSize, nil, true))
// 竞争检测器使用此位置进行同步
c.buf = c.raceaddr()
// 元素不是指针,分配一块连续的内存给hchan数据结构和buf
case elem.ptrdata == 0:
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
//hchan数据结构后面紧接着就是buf
c.buf = add(unsafe.Pointer(c), hchanSize)
//元素包含指针,单独为hchan 和缓冲区分配内存
default:
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
//更新chan的元素大小、类型、容量
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}
|
上述代码根据 Channel 中收发元素的类型和缓冲区的大小初始化 runtime.hchan 和 缓冲区:
- 如果当前 Channel 中不存在缓冲区,那么就只会为 runtime.hchan 分配一段内存空间;
- 如果当前 Channel 中存储的类型不是指针类型,会为当前的 Channel 和 底层的数组分配一块连续的内存空间;
- 在默认情况下会单独为 runtime.hchan 和 缓冲区分配内存;
在函数的最后会统一更新 runtime.hchan 的 elemsize、elemtype 和 dataqsiz 几个字段。
从代码中也可以看出,make 函数在创建channel的时候会在该进程的 heap区 申请一块内存,创建一个 hchan 结构体,返回执行该内存的指针,所以获取的的 ch变量本身就是一个指针,在函数之间传递的时候是同一个channel。
chan 发送数据
当要向 Channel 发送数据时,就需要使用 ch <- i 语句,编译器会将它解析成 OSEND 节点并转换成 runtime.chansend1:
1
2
3
4
5
6
7
8
|
// src/cmd/compile/internal/walk/expr.go
func walkSend(n *ir.SendStmt, init *ir.Nodes) ir.Node {
n1 := n.Value
n1 = typecheck.AssignConv(n1, n.Chan.Type().Elem(), "chan send")
n1 = walkExpr(n1, init)
n1 = typecheck.NodAddr(n1)
return mkcall1(chanfn("chansend1", 2, n.Chan.Type()), nil, init, n.Chan, n1)
}
|
runtime.chansend1 其实只是一个简单调用,调用了函数 runtime.chansend,代码如下:
1
2
3
4
|
// src/runtime/chan.go
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
|
runtime.chansend 是向 Channel 中发送数据时一定会调用的函数,该函数包含了发送数据的全部逻辑,如果在调用时将 block 参数设置成 true,那么表示当前发送操作是阻塞的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
|
// src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
//如果channel为nil
if c == nil {
//如果非堵塞模式,则直接返回false
if !block {
return false
}
// nil channel 发送数据会永远阻塞下去
// 挂起当前 goroutine
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
//如果非堵塞模式,如果chan没有被close并且chan缓冲满了,直接返回false
if !block && c.closed == 0 && full(c) {
return false
}
var t0 int64
//未启用阻塞分析,由于CPU分支预测
if blockprofilerate > 0 {
t0 = cputicks()
}
//上锁
lock(&c.lock)
//chan已经关闭,解锁,panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 如果在接收等待队列上存在正在等待的G,则直接将数据发送
// 不必将数据缓存到队列中
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
/**
如果当前chan的缓存区未满,将数据缓存到队列中;否则阻塞当前G
*/
//当前chan的缓存区未满
if c.qcount < c.dataqsiz {
//计算下一个缓存区位置指针
qp := chanbuf(c, c.sendx)
//将数据保存到缓冲区队列
typedmemmove(c.elemtype, qp, ep)
//sendx位置往后移动一位
c.sendx++
//如果c.sendx == c.dataqsiz,表示sendx索引已经达到缓冲队列最尾部了,则将sendx移动到0(第一个位置),这个是环形队列思维
if c.sendx == c.dataqsiz {
c.sendx = 0
}
//Chan中的元素个数+1
c.qcount++
//解锁,返回即可
unlock(&c.lock)
return true
}
//如果未堵塞模式,缓冲区满了则直接解锁,返回false
if !block {
unlock(&c.lock)
return false
}
//缓冲队列已满或者创建的不带缓冲的channel,则阻塞当前G
//获取当前goroutine
gp := getg()
// 获取一个sudog对象并设置其字段
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep //将指向发送数据的指针保存到 elem 中
mysg.waitlink = nil
mysg.g = gp //将g指向当前的goroutine
mysg.isSelect = false
mysg.c = c //当前阻塞的 channel
gp.waiting = mysg
gp.param = nil // param 可以用来传递数据,其他 goroutine 唤醒该 goroutine 时可以设置该字段,然后根据该字段做一些判断
c.sendq.enqueue(mysg)// 将sudog加入到channel的发送等待队列hchan.sendq中
atomic.Store8(&gp.parkingOnChan, 1)
// 当前 Goroutine 切换为等待状态并阻塞等待其他的Goroutine从 channel 接收数据并将其唤醒
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
// 在没有其他的接收队列将数据复制到队列中时候,需要保证当前需要被发送的的值一直是可用状态
KeepAlive(ep)
/**
协程被唤醒后
*/
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
//更新goroutine相关的对象信息
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
//释放sudog对象
releaseSudog(mysg)
//如果channel已经关闭
if closed {
// close标志位为0,则抛出假性唤醒异常
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
//直接panic
panic(plainError("send on closed channel"))
}
return true
}
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src 是发送的数据源地址,dst 是接收数据的地址
// src 在当前的 goroutine 栈中,而 dst 在其他栈上
dst := sg.elem
// 使用 memove 直接进行内存 copy
// 因为 dst 指向其他 goroutine 的栈,如果它发生了栈收缩,那么就没有修改真正的 dst 位置
// 所以会加读写前加一个屏障
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
......
// sg.elem 是指向待接收 goroutine 中接收数据的指针
// ep是指当前发送数据所在的指针
// 如果待接收 goroutine 需要接收具体的数据,那么直接将数据 copy 到 sg.elem
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
//gp是指接收的goroutine
gp := sg.g
unlockf()
// 赋值 param,待接收者被唤醒后会根据 param 来判断是否是被发送者唤醒的
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
//将gp唤醒,放入处理器P的本地运行队列,等待被调度
goready(gp, skip+1)
}
// 计算缓冲区下一个可以存储数据的位置
func chanbuf(c *hchan, i uint) unsafe.Pointer {
return add(c.buf, uintptr(i)*uintptr(c.elemsize))
}
|
总结一下发送流程:
- 如果当前channel的 接收等 待队列 recvq 中有 等待的sudog,则取出一个sudog并将数据直接发送过去并返回,不必将数据缓存到channel的缓冲区队列中;否则将数据暂存到缓存队列里;
- 将数据暂缓到队列缓存中分两种情况:
- 如果channel的数据缓冲区队列 buf 没有满,说明可以将数据缓存到该队列中,通过 chanbuf() 计算队列下一个可以存储数据的地址并将数据拷贝到该地址上并结束返回。
- 如果 buf 已满或者c.qcount=c.dataqsiz(即不带缓冲的channel),将 当前G 和 数据对象 封装到sudog并加入到channel的 发送等待队列 recvq,最后挂起当前的Goroutine,直到唤醒。
runtime.chansend 代码的流程图如下:
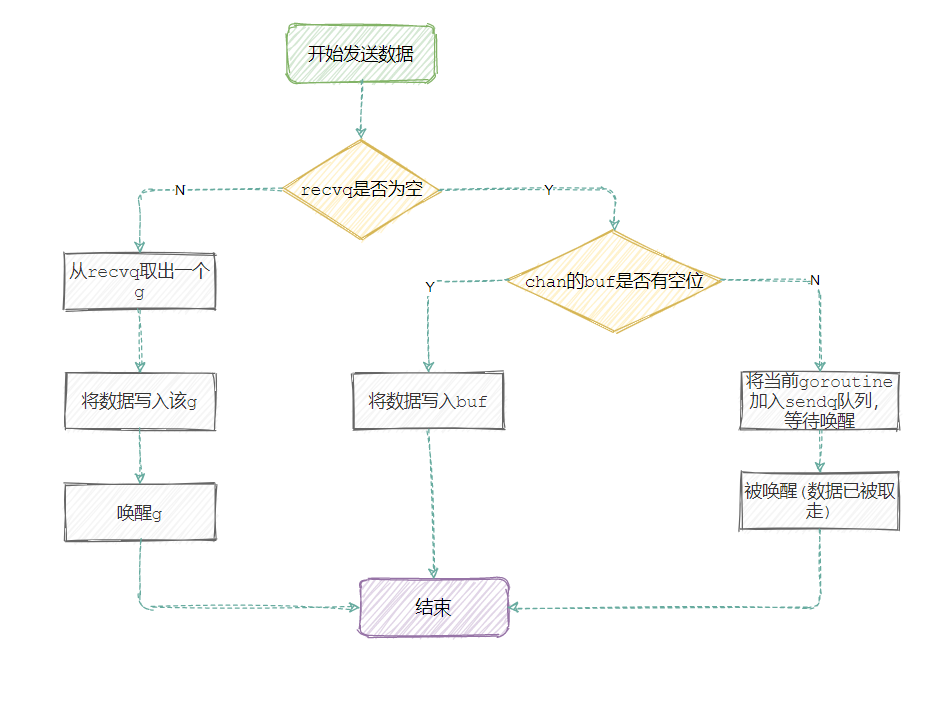
除了流程以外,从代码中可以重点列出几个要点信息:
- 当channel为nil时,如果是非阻塞调用,直接返回 false,意味着向 nil channel 发送数据不会被选中 ,而阻塞调用就被 gopark 挂起,永久阻塞
- 往一个已经关闭的channel中发送数据,会直接 panic
chan 接收数据
接下来继续介绍 Channel 操作的另一方:接收数据。Go 语言中可以使用两种不同的方式去接收 Channel 中的数据,这两种不同的方法经过编译器的处理都会变成 ORECV 类型的节点,后者会在类型检查阶段被转换成 OAS2RECV 类型。数据的接收操作遵循以下的路线图:
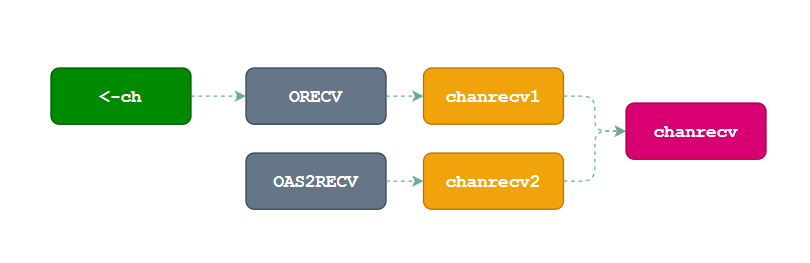 虽然不同的接收方式会被转换成
虽然不同的接收方式会被转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是这两个函数最终还是会调用 runtime.chanrecv。
runtime.chanrecv源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
|
//go 1.20.3 path: /src/runtime/chan.go
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
//如果chan为空且是非阻塞调用,那么直接返回 (false,false)
if !block {
return
}
// 阻塞调用直接等待
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
/**
快速检测,在非阻塞模式下,和发送一样有些条件不需要加锁就可以直接判断返回。
当前非阻塞并且chan未关闭,并符合下列条件之一:
1. 非缓冲channel且没有待发送者
2. 缓冲channel且是缓冲区为空
*/
if !block && empty(c) {
//chan未关闭,直接返回(false,false)
if atomic.Load(&c.closed) == 0 {
return
}
//channel 处于关闭,并且empty(c),返回(true,false)
if empty(c) {
if ep != nil {
//将接收的值置为空值
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
//未启用阻塞分析,由于CPU分支预测
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
//加锁
lock(&c.lock)
//channel 处于关闭
if c.closed != 0 {
//如果channel元素为空
if c.qcount == 0 {
//如果竞态检测功能已启用(即 raceenabled 为 true),则调用 raceacquire() 函数检测
if raceenabled {
raceacquire(c.raceaddr())
}
//解锁
unlock(&c.lock)
if ep != nil {
//将接收的值置为空值
typedmemclr(c.elemtype, ep)
}
return true, false
}
} else {
//待发送队列sendq中有 goroutine,说明是非缓冲channel或者缓冲已满的 channel,将数据从待发送者复制给接收者
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
//chan的缓存队列中还有数据
if c.qcount > 0 {
//获取一个缓存队列数据的指针地址
qp := chanbuf(c, c.recvx)
if ep != nil {
//将该数据复制到接收对象
typedmemmove(c.elemtype, ep, qp)
}
//清空该指针地址的数据
typedmemclr(c.elemtype, qp)
//recvx+1
c.recvx++
//如果接收游标 等于环形链表的值,则接收游标清零。
if c.recvx == c.dataqsiz {
c.recvx = 0
}
//循环数组buf元素数量-1
c.qcount--
unlock(&c.lock)
return true, true
}
//非阻塞接收,因为chan的缓存中没有数据,则解锁,selected 返回 false,因为没有接收到值
if !block {
unlock(&c.lock)
return false, false
}
// 缓冲区队列没有数据可以读取,则将当前G打包成Sudo结构并加入到接收等待队列
gp := getg()
/**
创建一个sudog结构体,并将其与当前的goroutine (gp) 关联。
sudog结构体用于在并发环境中进行同步操作和调度。其中的字段和赋值操作可能会在其他代码中使用
*/
//创建一个新的sudog结构体,并将其赋值给变量mysg
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg) // 加入到接收等待队列recvq中
atomic.Store8(&gp.parkingOnChan, 1)
// 阻塞等待被唤醒
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
//唤醒后,设置goroutine的部分字段值,并释放该g的Sudo
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}
func empty(c *hchan) bool {
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
//无缓冲 channel
if c.dataqsiz == 0 {
//如果ep 不为 nil,那么直接从发送 goroutine 中将数据 copy 到接收位置
if ep != nil {
recvDirect(c.elemtype, sg, ep)
}
} else {
//从数据缓冲区队列中取出一个元素地址
qp := chanbuf(c, c.recvx)
if ep != nil {
// 将待接收数据复制到接收位置
typedmemmove(c.elemtype, ep, qp)
}
//将数据取出后,会腾出一个位置,此时将从sendq队列中的取出的数据sg.elem复制到该位置gp
typedmemmove(c.elemtype, qp, sg.elem)
//调整 recvx
c.recvx++
//如果recvx已经到达队列尾部,则将recvx移动到0位置
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 通过c.sendx = (c.sendx+1) % c.dataqsiz计算得出,环形队列方式
c.sendx = c.recvx
}
sg.elem = nil //清空发送者数据
gp := sg.g //获取发送者协程
unlockf()
gp.param = unsafe.Pointer(sg) //赋值发送者的 param,发送者被唤醒后会根据 param 来判断是否是关闭唤醒的
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
//将G重新放入处理器P的本地运行队列,等待被调度处理
goready(gp, skip+1)
}
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
src := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
|
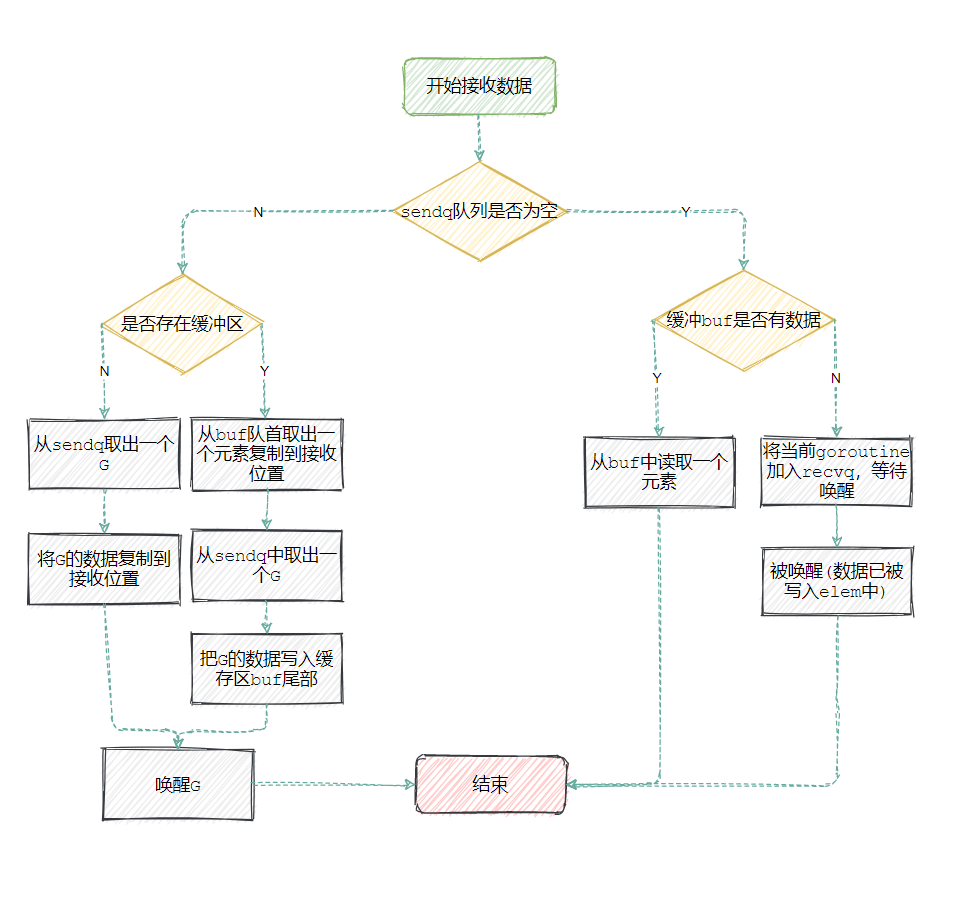
总结一下发送流程:
- 如果当前 Channel 已经被关闭并且缓冲区中不存在任何数据,那么会清除 ep 指针中的数据并立刻返回
- 如果等待发送的队列sendq不为空,通过 runtime.recv从阻塞的发送者或者缓冲区中获取数据;此处分有两种情况:
- 如果该channel没有缓冲区,调用 runtime.recvDirect将 Channel 发送队列中 Goroutine 存储的 elem 数据拷贝到目标内存地址中;
- 如果该channel有缓冲区, 从缓冲区首部读出数据, 把G中数据写入缓冲区尾部,把G唤醒,结束读取过程
- 当缓冲区队列存在数据时,从 Channel 的缓冲区中接收数据;
- 当缓冲区中不存在数据时,将当前goroutine加入recvq队列中,进入睡眠,等待其他 Goroutine 向 Channel 发送数据唤醒;
除了流程以外,几个注意点:
- 当channel为nil时,如果是非阻塞调用,直接返回 false,而阻塞调用就被 gopark 挂起,永久阻塞
- 在非阻塞调用下,当 channel没有关闭,但是满足并符合下列条件之一,则也可快速判断,直接返回:
- 有缓冲channel但是缓冲区为空
- 无缓冲channel且等待发送队列 sendq 中没有待发送者
简单接收数据流程图如下:
关闭channel
关闭 channel 直接调用 close 函数即可,编译器会将用于关闭管道的 close 关键字转换成 OCLOSE 节点以及 runtime.closechan 函数。但是贸然关闭 channel 会引发很多的问题,还是从源码来看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
func closechan(c *hchan) {
//当chan为空的时候,close会panic
if c == nil {
panic(plainError("close of nil channel"))
}
//上锁
lock(&c.lock)
......
//当chan已经关闭状态,close会panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
//设置c.closed为1
c.closed = 1
//保存channel中所有等待队列的G的list
var glist gList
//将 channel所有等待接收队列的里 sudog 释放
for {
//接收队列中出一个sudog
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
//取出goroutine
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
// 加入队列中
glist.push(gp)
}
//将channel中等待接收队列里的sudog释放,如果存在这些goroutine将会panic
for {
//从发送队列中出一个sudog
sg := c.sendq.dequeue()
if sg == nil {
break
}
//发送者panic
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
//取出goroutine
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
// 加入队列中
glist.push(gp)
}
//解锁
unlock(&c.lock)
//唤醒所有的glist中的goroutine
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
|
关闭channel会把recvq中的G全部唤醒,本该写入G的数据位置为nil。把sendq中的G全部唤醒,但这些G会panic
除此之外,panic出现的场景还有:
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据