一、指针简介
1.1 指针简介
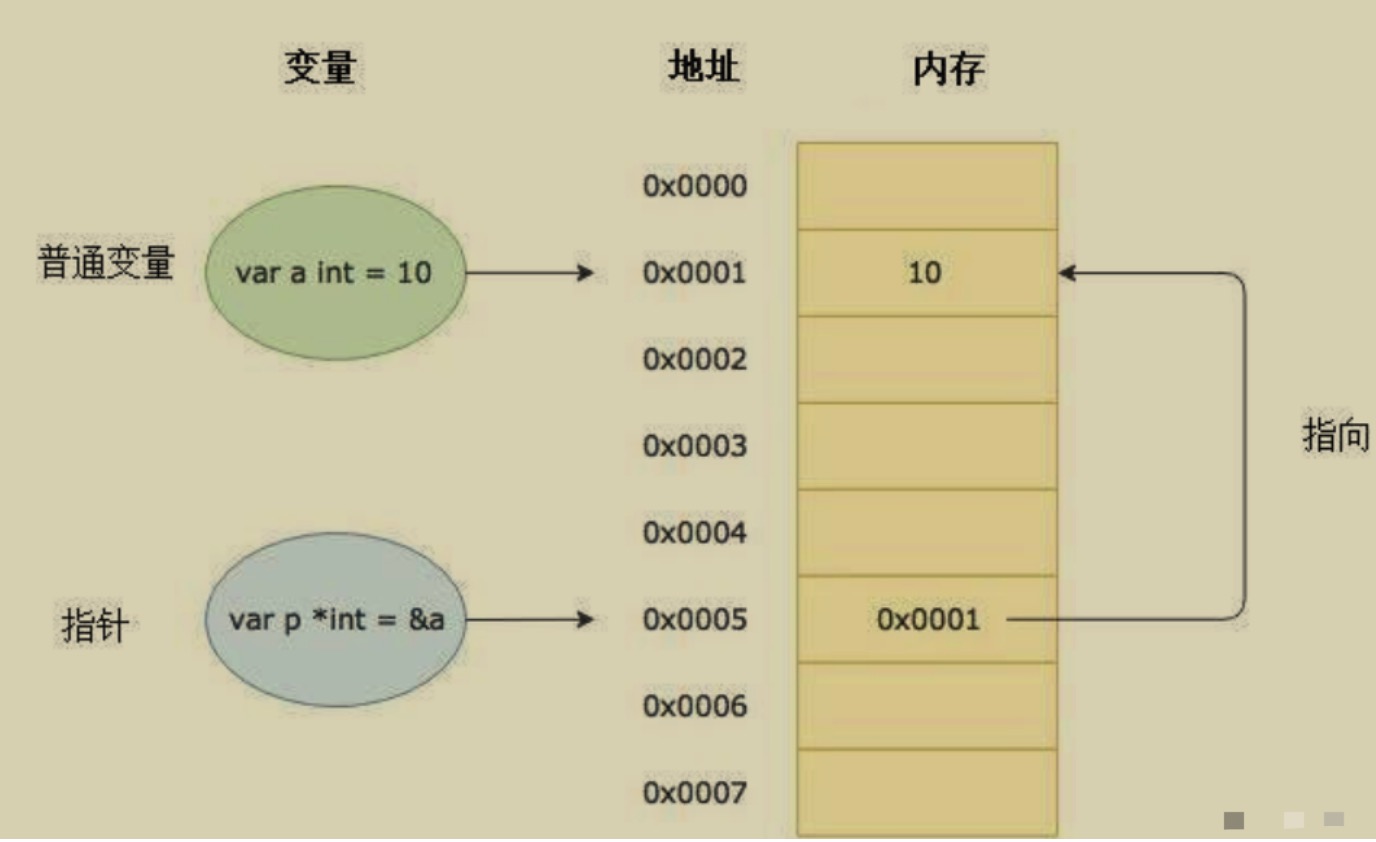
变量的本质是给存储数据的内存地址起了一个好记的别名。每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。
指针(pointer) 是一种特殊的变量,它存储的数据不是一个普通的值,而是另一个变量的内存地址,它存放的内存地址可能是另外一个变量、函数 或者 指针变量的内存地址等。如下图所示:
在 Golang 中,不免会使用指针,但是 大多数情况下使用的是类型安全的指针,类型安全的指针有助于写出安全的代码,但是却有诸多限制,比如 不能对地址进行算数运算、不支持任意两个类型相互转换 等。
Go语言中的类型安全指针操作非常简单,只使用到两个符号:&(取变量地址)和 *(根据地址取变量值)。
- Go 语言中使用
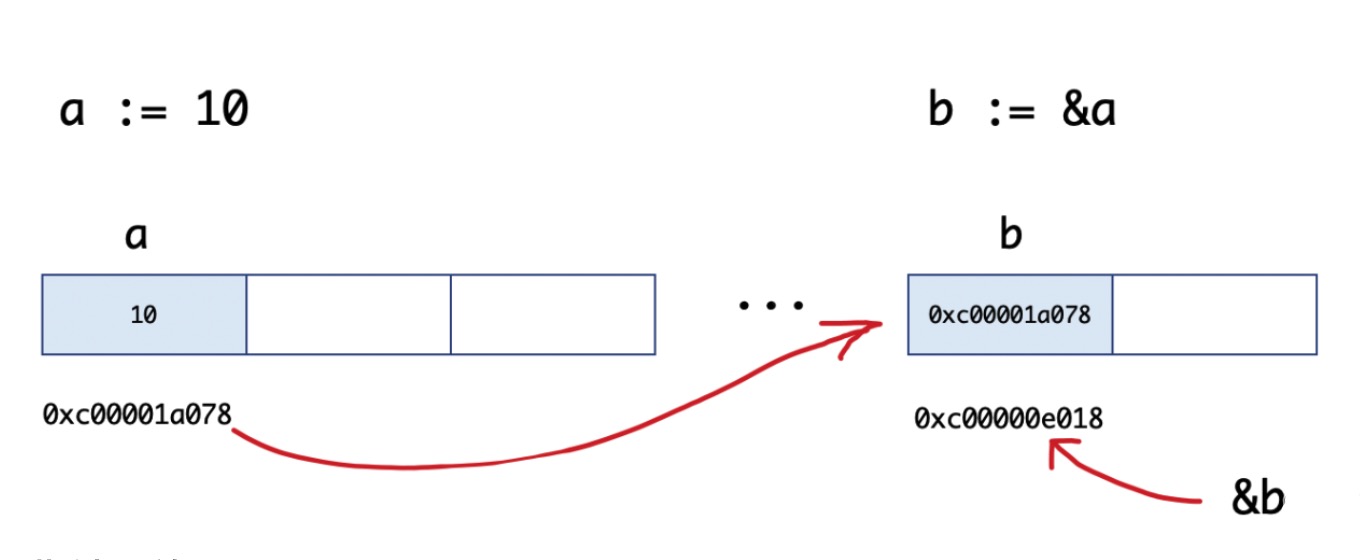
& 字符放在变量前面对变量进行 取地址操作,在对变量使用 & 操作符取地址后会获得这个变量的内存地址,这个地址通常称作 指针。例如:
1
2
3
4
5
6
7
|
var a int = 10
// 每一个变量都有自己的内存地址,可以使用 & 操作符取变量地址
fmt.Printf("a的值为%v a的类型为%T a的内存地址为%v\n",a,a,&a)
// 指针也是一个变量,但它是一种特殊的变量,它存储的数据不是一个普通的值,而是另一个变量的内存地址
b := &a // b 是指针变量,b 的类型 *int(指针类型)
fmt.Printf("b的值为%v b的类型为%T b的内存地址为%v\n",b,b,&b)
|
- 对指针使用
* 操作可以获取/修改指针指向的(内存地址)变量值,称作 解引用操。
1
2
3
4
5
6
7
8
|
var e int = 30
var d *int = &e
// d := &e
// *d :表示取出 d这个变量中存储的内存地址的 值
*d = 40 // 改变 d这个 变量中存储的内存地址的 值(也就是变量 e 的值)
fmt.Println(e)
fmt.Println(*d)
|
Tips: 取地址操作符 & 和 取值操作符 * 是一对互补操作符,& 取出变量地址,* 根据地址取出地址指向的内存中的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址 & 操作,可以获得这个变量的指针(内存地址);
- 指针变量(存放指针地址的变量)的值是指针地址;
- 对指针变量进行 * 操作,可以获得指针变量中的指针地址指向的变量的值;
当一个指针变量被定义后没有分配到(指向)任何变量时,它的值为 nil。
nil 指针也称为 空指针。
nil 在概念上和其它语言的 null、None、nil、NULL一样,都指代零值或空值。
1.2 非类型安全指针简介
Go 实际上是支持非类型安全的指针的,通过非类型安全指针,可以绕过诸多限制,在某些情况下甚至可以写出更高效的代码,但同时也可能会引入一些潜在的不容易发现的问题。其次,非类型安全指针没有受到 Golang的兼容性保证 的保护,在后续的Go版本中,使用非类型安全指针的代码可能会无法编译通过。
即使会有上述的风险,但目前源码的很多地方都使用了非类型安全指针,同时官方给出了正确的使用方式,本篇文章后面将做出详细介绍。
二、类型安全指针
2.1 为什么需要使用指针
在 Go 中,所有的参数传递都是值传递,没有引用传递。
Tips: 值传递就是把 实参变量的值 copy 一份到形参变量,对于值类型的形参 copy 的就是变量中存储的值;对于指针变量 copy 的是指针变量中存储的 内存地址(指向一块内存空间)。
如果参数占用内存过大,每次函数传递都需要变量拷贝,性能低下并且比较耗费内存,使用指针就只需 copy 要传递参数的 内存地址,可以有效降低copy 的数据量;
如果想要在函数内部修改变量的状态,并在调用完毕后看到这种修改,也需要使用指针。
2.2 如何获得一个指针
有两种方式来获取类型安全的指针:
- 通过取地址符 & 获取某个变量的指针(内存地址);
- 通过内置 new 函数申请一块适合存放某个类型的内存空间 也将获取该类型的指针(内存地址);
1
2
3
4
5
6
7
8
|
func main() {
a := new(int) // 通过 new 为int类型的值开辟一块内存,并返回指向内存起始地址的指针
fmt.Printf("%p\n", a) // 0xc00034a4b8
b := int32(1)
c := &b // 通过取地址符 & ,获取一个变量的指针
fmt.Printf("%p\n", c) // 0xc00034a4c0
}
|
new 是一个内置的函数(不太常用),用于一个具体类型的内存分配(动态分配内存),使用 new 函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值,它的函数签名如下:
- Type表示类型,new函数只接受一个参数,这个参数是一个类型;
- *Type表示类型指针,new函数返回一个指向该类型内存地址(指针);
Tips: new 和 make 的区别
- 在 Go 语言中 对于引用类型(slice、chan、map 等)的变量,在使用的时候不仅要声明它,还要为它分配内存空间,否则这类变量就没办法存储响应的值(触发panic)。
- 而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。
- Go 语言中 new 和 make 是内建的两个函数,主要用来分配内存。
make 用于内存分配 有别于 new,它只用于 slice、map 以及 chan 的内存创建,而且它返回的类型就是这三个类型本身,而不是它们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回它们的指针了。make函数的函数签名如下:
1
|
func make(t Type, size ...IntegerType) Type
|
2.3 类型安全指针的限制
1、不能对指针的地址进行算术运算
定义一个变量 a ,然后取地址 addr,对取到的地址 addr 做算术运算,如 addr++ 会编译不通过;*addr++ 编译可以通过,最后输出 a=1,其实 *addr++ 被编译器解释为了(*addr)++,即解引用操作符 * 的优先级 高于 自增符 ++。
2、两个任意指针类型不能随意转换
只有两个类型的底层数据类型是一致的,才可以完成转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
type MyInt int64
type T1 *int64
type T2 *MyInt
func main() {
var a *int64
var myInt *MyInt
var t1 T1
t1 = a // t1 底层是 *int64类型,a 是 *int64 类型,可以隐式转换
var t2 T2
t2 = myInt // t2 是 *MyInt类型,myInt 也是 *MyInt类型,不需要转换
t2 = a // t2 是 T2 类型,a 是 *int64 类型,不能隐式转换
t2 = (*MyInt)(a) // t2 (T2 类型)的底层类型是 *int64,a 是 *int64 类型,需要显式转换
t1 = (*int64)(t2) // t2 是 T2 类型,其底层是 *MyInt 类型,不能直接转换为 *int64类型,需要显式转换
t1 = (*int64)((*MyInt)(t2)) // t2 是 T2 类型,其底层是 *MyInt 类型,需要显示转换为其底层类型 *MyInt,
// *MyInt类型显示转换为 *int64,赋值时 *int64 隐式转换为 T1 类型
}
// 但是这些类型,无论怎么转换,都转换不了 *uint64 类型
|
三、非类型安全指针 unsafe.Pointer
3.1 unsafe 包中的 Pointer(非类型安全指针)
Golang中,非类型安全指针 是指 unsafe 包中的 Pointer。
unsafe 包用于编译阶段可以绕过 Go 语言的类型系统,直接操作内存。例如,利用 unsafe 包操作一个结构体的未导出成员。unsafe 包给程序员提供可以直接读写内存的能力。
非类型安全指针 类型定义为:
1
2
3
4
5
|
// unsafe 包中的 Pointer 定义
// 表示任意类型
type ArbitraryType int
type Pointer *ArbitraryType
|
ArbitraryType 类型的底层是 int类型,在 Go 中 ArbitraryType 有特殊的意义,用于表示任意类型,也就是说 Pointer 可以指向任意数据类型,可以和任意类型的指针相互转换。Pointer是底层 int指针类型 的一个别名,在 Go 中可以把任意指针类型转换成 unsafe.Pointer类型,也就是说 Pointer 可以指向任意数据类型,可以和任意类型的指针相互转换。
unsafe 包中有如下三个函数:
1
2
3
4
5
6
7
8
9
10
11
|
// 1. Sizeof 接受任意类型的值(表达式),返回一个变量占用的内存字节数
func Sizeof(x ArbitraryType) uintptr
// 2. Offsetof 返回结构体成员在内存中的位置距离结构体起始处的字节数(偏移量),
// 所传参数必须是结构体的成员(结构体指针指向的地址就是结构体起始处的地址,即第一个成员的内存地址)。
func Offsetof(x ArbitraryType) uintptr
// 3. Alignof 返回变量对齐字节数量,这个函数虽然接收的是任何类型的变量,
// 但是有一个前提,就是变量要是一个struct类型,且还不能直接将这个struct类型当作参数,
// 只能将这个struct类型的变量当作参数。
func Alignof(x ArbitraryType) uintptr
|
三个函数的参数均是 ArbitraryType类型,就是接受任何类型的变量。
三个函数都是在编译期间执行。
这三个函数的返回值的类型均为内置类型 uintptr,uintptr 是GO语言的内置整数类型,定义在 builtin 包下,定义如下:
1
2
3
|
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
|
- uintptr 是一个整数类型(这个非常重要),注意,它不是个指针;
- 但 uintptr 类型的变量足够保存任何一种指针类型(内存地址);
uintptr 用来 存储指针类型(内存地址),但是并没有指针的语义,即存储在 uintptr 中的值(内存地址)在Go发生GC时会被回收,在64位平台上底层的 数据类型是uint64。
uintptr 是一个整数值,用来保存变量的内存地址,可以和 Pointer 相互转换。
Pointer 表示指向任意类型的指针,也称为 通用指针,对于该类型有四种合法的操作:
- 任意类型的指针可以转为 unsafe.Pointer;
- unsafe.Pointer 可以转为任意类型的指针;
- uintptr 可以转为 unsafe.Pointer;
- unsafe.Pointer 可以转为 uintptr;
unsafe.Pointer是特别定义的一种指针类型(译注:类似C语言中的void类型的指针),它越过了类型检查,可以直接操作底层的内存,在Go 语言中是用于各种指针相互转换的桥梁,它可以持有任意类型变量的指针(地址)。
和普通指针一样,unsafe.Pointer 指针也是可以比较的,并且支持和 nil 比较判断是否为空指针。
unsafe.Pointer 不能直接进行数学运算,但可以把它转换成 uintptr,对 uintptr 类型进行数学运算后,再转换成 unsafe.Pointer 类型。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func main() {
a := int(1)
b := (*int64)(unsafe.Pointer(&a)) // 将 *int 先转为 Pointer,再转为 *int64
c := uintptr(unsafe.Pointer(&a)) // 将 *int 先转为 Pointer,再转为 uintptr
fmt.Printf("%p\n", b) // 打印地址 0xc0003cdbb0
fmt.Printf("%x\n", c) // 地址 c0002124b8
type T struct {
a string
b int
}
t := T{a: "abc", b: 1}
/*
1. 将 t 的地址转为 Pointer:符合第一种 unsafe.Pointer(&t)
2. 将 Pointer 转为 uintptr 后得到地址的整数值:符合第四种 uintptr(unsafe.Pointer(&t))
3. 加上 t.b 的offset,得到 t.b 的地址整数值:uintptr是整数,
可以直接相加 uintptr(unsafe.Pointer(&t)) + unsafe.Offsetof(t.b)
4. 将 uintptr 转为 Pointer:符合第三种
5. 将 Pointer 转为 *int :符合第二种
6. 最后解引用,得到具体的值
*/
d := *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&t)) + unsafe.Offsetof(t.b)))
fmt.Println(d) // 1
}
|
一个unsafe.Pointer指针也可以被转化为uintptr类型,然后保存到uintptr类型的变量中(注:这个变量只是和当前指针有相同的一个数字值,并不是一个指针),然后用以做必要的指针数值运算。(uintptr是一个无符号的整型数,足以保存一个地址)这种转换虽然也是可逆的,但是随便将一个 uintptr 转为 unsafe.Pointer指针可能会破坏类型系统,因为并不是所有的数字都是有效的内存地址。
uintptr 并没有指针的语义,意思就是存储 uintptr 值的内存地址在Go发生GC时会被回收。而 unsafe.Pointer 有指针语义,可以保护它不会被垃圾回收。
3.2 正确使用非类型安全指针
Pointer 越过了类型检查,可以直接操作底层的内存,因此使用时需要格外小心。对于 Pointer的操作,只有如下六种是合法的,其余的使用方式均为非法。
使用方式1:利用 Pointer 作为中介,完成 T1 类型 到 T2 类型的转换
T1 和 T2 是任意类型,如果 T1 的内存占用大于等于 T2,并且 T1 和 T2 的内存布局一致,可以利用 Pointer 作为中介,完成 T1类型 到 T2类型的转换。如果T1 的内存占用小于 T2,那么 T2 剩余部分没法赋值,就会有问题
math 包中的 Float64bits 函数将一个 float64 值转换为一个 uint64 值,Float64frombits 为此转换的逆转换,即 Float64bits(Float64frombits(x)) == x。
1
2
3
4
5
6
7
|
func Float64bits(f float64) uint64 {
return *(*uint64)(unsafe.Pointer(&f))
}
func Float64frombits(b uint64) float64 {
return *(*float64)(unsafe.Pointer(&b))
}
|
slice 和 string 结构的底层布局类似,且 slice 的内存占用大于 string,可以利用此种方式完成 slice 到 string 的正确转换,但是无法正确完成 string 到 slice 的转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// slice 和 string 的底层结构
type slice struct {
array unsafe.Pointer
len int
cap int
}
type stringStruct struct {
str unsafe.Pointer
len int
}
// -----------------------------
func main() {
// slice 转 string,可以正确转换
sli := []byte{'a', 'b', 'c'}
str := *(*string)(unsafe.Pointer(&sli))
fmt.Println(str) // abc
fmt.Println(len(str)) // 3
// string 转 slice,cap 字段无法赋值,无法正确转换
str = "1234"
b := *(*[]byte)(unsafe.Pointer(&str))
fmt.Println(string(b)) // 1234
fmt.Println(len(b)) // 4
fmt.Println(cap(b)) // 824634066744
sli[0] = 'd'
sli[1] = 'e'
fmt.Println(str) // dec
}
|
slice 转为 string 后,两者对应的指针指向的是同一个字节数组,因此修改底层的数组值,string 相应的也会跟着改变。
使用方式2:将 Pointer 转为 uintptr (不再转回 Pointer)
从 Pointer 转 uintptr 本质产出的是这个 Pointer 指向的值的内存地址,一个整型。
将 Pointer 转为 uintptr,并且不再转回 Pointer,此方式用处不大,通常只用来打印值。
此方式相当于取变量的内存地址,由于 uintptr 是个变量值,而非引用,后续该变量被移动到其它位置,其对应的 uintptr 值不会更新;其次,如果后续没有使用该变量,随时可能会被垃圾回收掉。
1
2
3
4
5
6
|
// 每次运行得到的内存地址,可能不一样
func main() {
a := int(10)
fmt.Printf("%p\n", &a) // 0xc0001184b8
fmt.Printf("%x\n", uintptr(unsafe.Pointer(&a))) // c0001184b8
}
|
- uintptr 指的是具体的内存地址,不是个指针,没有指针的语义,可以将 uintptr 打印出来比对地址是否相同。
- 即便某个对象因为 GC 等原因被回收,uintptr的值也不会连带着变动。
- uintptr地址关联的对象可以被垃圾回收。GC不认为uintptr是活引用,因此unitptr地址指向的对象可以被垃圾收集。
因此,将 uintptr 转回 Pointer 是存在风险的,只有接下来列举的几种转换方式合法的。
使用方式3:将Pointer转为 uintptr,进行算术运算后再将 uintptr 转回 Pointer
可以将一个变量的 Pointer 转为 uintptr,然后再加上一定的偏移量转回 Pointer,这种方式通常用来获取结构体中的成员变量地址或者数组中第i个元素的地址。
结构体:可以先拿到结构体变量 e 的地址,然后加上 成员b 的偏移量,就可以得到 e.b 的地址,再转回 Pointer 就能够拿到对应的值了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func main() {
type Example struct {
a int32
b string
}
e := Example{
a: 1,
b: "test",
}
// 等价于 *(*string)(unsafe.Pointer(&e.b))
c := *(*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&e)) + unsafe.Offsetof(e.b))) // uintptr是整数,可以直接相加
fmt.Println(c, d)
}
|
Tips: Pointer 到 uintptr 和 uintptr 到 Pointer 的转换一定要在一个表达式,不能用 uintptr 存起来,下个表达式再转。
数组:拿到数组第一个元素 a[0] 的地址,转为 uintptr 后,加上 2(倍)个元素类型占用的内存大小,就可以得到第 3 个元素的地址值,再转回 Pointer,最后转为 int,就得到了第三个元素的值。
1
2
3
4
5
|
func main() {
a := []int{1, 2, 3, 4}
b := *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&a[0])) + 2*unsafe.Sizeof(a[0])))
fmt.Println(b)
}
|
同理,获取一个成员或元素的地址,然后减去相应的偏移量,也是合法操作。但是无论怎么操作,需要保证最后得到的地址,是在当前变量占用的地址范围内,不能超出, 如下几种就是非法的操作:
1
2
3
4
5
6
7
|
// 从初始地址,最多加 unsafe.Sizeof(s)-1
var s thing
end = unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Sizeof(s))
// 声明了 n 个字节的长度,从初始地址最多加 n-1
b := make([]byte, n)
end = unsafe.Pointer(uintptr(unsafe.Pointer(&b[0])) + uintptr(n))
|
- 非法操作2:使用变量保存 uintptr 的值
Pointer 到 uintptr 的转换以及计算必须在一个表达式中完成(需要保证原子性)。
在将 uintptr 类型转为 Pointer 类型之前,不能将 uintptr 的的值赋值给变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 非法操作示例
func main() {
type Example struct {
a int32
b string
}
e := Example{
a: 1,
b: "test",
}
// 正确操作 c := *(*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&e)) + unsafe.Offsetof(e.b)))
addr := uintptr(unsafe.Pointer(&e)) + unsafe.Offsetof(e.b)
// 到这里,变量 e 没有任何引用了,因此可能随时被垃圾回收器回收,一旦被回收,再使用 e.b 原来的地址将是非常危险的
c := *(*string)(unsafe.Pointer(addr))
fmt.Println(c)
}
|
- 非法操作3:Pointer 指向 nil
Pointer 需要指向一个分配过内存的变量,不能指向 nil
1
2
3
|
// Pintere指向nil是非法的
u := unsafe.Pointer(nil)
p := unsafe.Pointer(uintptr(u) + offset)
|
使用方式4:将 Pointer 转为 uintptr,传递给系统调用 syscall.Syscall
uintptr 是一个整数,获取到了一个变量的 uintptr 值,并不能保证变量不被垃圾回收掉,如果变量被垃圾回收掉,使用原先的 uintptr 值将是非常危险的。
下面这个函数是危险的原因在于,函数本身不能保证传递进来的地址对应的内存块一定没有被回收。 如果此内存块已经被回收了或者被重新分配给了其它变量,那么此函数内部的操作将是非法和危险的。
1
2
3
|
func DoSomething(addr uintptr) {
// 对处于传递进来的地址处的值进行读写...
}
|
然而系统调用则有这种特权,保证了地址对应的内存块在函数执行过程中不被回收和移动。例如 syscall 标准库包中的 Syscall 函数的原型为:
1
|
func Syscall(trap, a1, a2, a3 uintptr) (r1, r2 uintptr, err Errno)
|
那么此函数是如何保证传递给它的地址参数值a1、a2和a3处的内存块在执行过程中一定没有被回收和被移动呢? 此函数无法做出这样的保证,事实上,是编译器做出了这样的保证。 这是 syscall.Syscall 这样函数的特权,其它自定义函数无法享受到这样的待遇。
正确的使用姿势为:
1
2
|
// 将 p 对应的 Pointer 值转为 uintptr
syscall.Syscall(SYS_READ, uintptr(fd), uintptr(unsafe.Pointer(p)), uintptr(n))
|
同时需要注意的是,我们也不能先将 uintptr 的值赋值给一个变量,然后再传入 syscall.Syscall
1
2
3
|
u := uintptr(unsafe.Pointer(p))
// 此时 p 可能被回收或者移动
syscall.Syscall(SYS_READ, uintptr(fd), u, uintptr(n))
|
使用方式5:将 reflect.Value.Pointer 或者 reflect.Value.UnsafeAddr 的 uintptr 值转为 unsafe.Pointer
reflect包中,Value 类型的 Pointer 和 UnsafeAddr 方法都返回一个 uintptr 值,而不是 unsafe.Pointer 值,这样做是为了避免用户在没有引入 unsafe 包的条件下,就可以将这两个方法的返回值转为任意类型安全的指针。(比如返回值 a 是 unsafe.Pointer 类型,不引入unsafe包,可以直接进行(*int32)(a),将其转为 int32 类型的指针 )。
因此,这种设计需要我们在调用完 reflect.Value.Pointer 或者 reflect.Value.UnsafeAddr后,立即调用 unsafe.Pointer 转为 Pointer 类型,否则在调用的空窗期,变量可能被移动或者回收。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func main() {
type Example struct {
a int32
b string
}
e := Example{
a: 1,
b: "test",
}
// 1. 正确使用方式
b := *(*string)(unsafe.Pointer(reflect.ValueOf(&e.b).Pointer()))
fmt.Println(b) // test
// 2. 错误使用方式
p := reflect.ValueOf(&e.b).Pointer()
// 此时变量可能被移动或者回收
b = *(*string)(unsafe.Pointer(p))
fmt.Println(b)
}
|
使用方式六:将 reflect.SliceHeader 或者 reflect.StringHeader 的 Data 域对应的 uintptr 转为 Pointer,或者将其它 Pointer 转为 uintptr 赋值给 Data
slice 和 string 底层的数据结构如下:其中 slice 结构的 array 字段和 string 结构的 str 字段底层其实都指向 字节数组。
SliceHeader 和 StringHeader 分别是 slice 和 string 结构的运行时表示,对于任意一个 slice 或者 string,我们可以拿到它的运行时表示,然后修改其 Data 值,达到修改其底层数据的目的。即我们可以将一个字符串的指针值 转换为 *reflect.StringHeader ,进而可以对此字符串的内部进行修改。类似,我们也可以将一个切片的指针值转换为 *reflect.SliceHeader ,从而对此切片的内部进行修改。
这样做的好处是,在不重新分配内存的情况下,将 string 或 slice 的底层数据改变。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
type slice struct {
array unsafe.Pointer
len int
cap int
}
type stringStruct struct {
str unsafe.Pointer
len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
type StringHeader struct {
Data uintptr
Len int
}
|
和上面第五条同样的原因,为了避免用户没有引入 unsafe包 就可以直接转换,reflect.SliceHeader 或者 reflect.StringHeader 的 Data 域都是 uintptr 类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 修改字符串对应的Data域
func main() {
str := "test"
// 字节数组,修改后字符串底层数据指向这个数组
a := [3]byte{'a', 'b', 'c'}
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&str))
strHeader.Data = uintptr(unsafe.Pointer(&a))
strHeader.Len = len(a)
fmt.Println(str) // abc
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func main() {
sli := []byte{'h', 'e', 'l', 'l', 'o'}
array := [4]byte{'1', '2', '3', '4'}
// 将切片转为 reflect.SliceHeader 结构
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&sli))
// 修改对应的字段数据,修改后 sli 底层的数据指向了 array
sliceHeader.Data = uintptr(unsafe.Pointer(&array))
// 先设置长度为2
sliceHeader.Len = 2
sliceHeader.Cap = len(array)
fmt.Printf("%s\n", sli) // 12
// 修改 sli 的长度
sli = sli[:cap(sli)]
fmt.Printf("%s\n", sli) // 1234
}
|
一般来说,应该从一个已经存在的字符串得到 *reflect.StringHeader,或者从一个已经存在的切片得到 *reflect.SliceHeader,不能直接声明 reflect.SliceHeader 或 reflect.StringHeader 变量:
1
2
3
4
5
6
|
// 错误使用方式
var hdr reflect.StringHeader
hdr.Data = uintptr(unsafe.Pointer(new([5]byte)))
// 在此时刻,上一行代码中刚开辟的数组内存块已经不再被任何值所引用,所以它可以被回收
hdr.Len = n
s := *(*string)(unsafe.Pointer(&hdr)) // 危险
|
使用 reflect.SliceHeader 和 reflect.StringHeader,我们可以在不重新分配底层数据内存的情况下,完成 slice 和 string 类型互换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// 字节切片转 string
func ByteSlice2String(slice []byte) (s string) {
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&slice))
stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
stringHeader.Data = sliceHeader.Data
stringHeader.Len = sliceHeader.Len
return
}
// string 转字节切片
func String2ByteSlice(s string) (slice []byte) {
stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&slice))
sliceHeader.Data = stringHeader.Data
sliceHeader.Len = stringHeader.Len
sliceHeader.Cap = stringHeader.Len
return
}
func main() {
b := []byte{'h', 'e', 'l', 'l', 'o'}
fmt.Println(ByteSlice2String(b)) // hello
s := "hello"
fmt.Println(String2ByteSlice(s)) // [104 101 108 108 111]
}
|
由于默认字符串内存是分配在不可修改区的,使用上述的 String2ByteSlice 将 string 转为 slice 后,只能进行读取,不能修改其底层数据值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func main() {
s1 := "Goland" // 官方标准编译器会将 s1 的字节开辟在不可修改内存区
b1 := String2ByteSlice(s1) // 转为字节数组
fmt.Printf("%s\n", b1) // Goland
// 由于字符串 s1 底层指向的字节数组在不可修改区,此时不能修改值,否则会panic
// b1[5] = 'a'
// 这种方式不会存放在不可修改区,转为字节数组后,可以修改值
s2 := strings.Join([]string{"Go", "land"}, "")
b2 := String2ByteSlice(s2)
fmt.Printf("%s\n", b2) // Goland
b2[5] = 'g' // 相当于修改底层数组的值,原字符串的值也会随之改变
fmt.Println(s2) // Golang
}
|