一、Golang关键字集
1.1 Golang关键字集简介
Go语言有25个预留的关键字,不能用作标识符。以下是这些关键字的列表以及它们的简要解释:
| 关键字 | 代码示例 | 代码作用 | 功能 |
|---|---|---|---|
| package | package main | 定义包名为 main | 定义包 |
| import | import “fmt” | 导入 fmt 包 | 导入包 |
| const | const PI = 3.14159 | 定义常量 PI | 定义常量或常量组 |
| var | var name string = “John” | 定义一个名为 name 的变量 | 声明变量或变量组 |
| func | func add(x, y int) int { return x + y } | 定义名为 add 的函数 | 定义函数/方法 |
| map | m := map[string]int{“one”: 1} | 创建一个键为字符串、值为整数的映射 | |
| chan | ch := make(chan int) | 创建一个新的整数类型的通道 | |
| type | type Point struct {x, y int} | 定义一个名为 Point 的结构体 | 定义新的数据类型、接口或类型别名 |
| struct | type Circle struct { Radius float64 } | 定义一个名为 Circle 的结构体 | |
| interface | type Writer interface { Write([]byte) error } | 定义一个名为 Writer 的接口 | |
| if | if x > 0 { /…/ } | 条件为 x > 0 时,执行某个操作 | |
| else | if x > 0 { /…/ } else { /…/ } | if 语句的否定分支 | |
| switch | switch x { case 1: /…/ } | 多分支选择 | |
| fallthrough | case 1: fallthrough | 在 switch 语句中,强制执行下一个 case | 用于switch语句,使得控制流穿透到下一个case |
| for | for i := 0; i < 10; i++ { /…/ } | 循环10次 | |
| range | for k, v := range m { /…/ } | 遍历映射 m | 用于循环遍历数组、切片、字符串、map或通道 |
| continue | if x < 0 { continue } | 如果 x < 0,则跳过当前循环迭代 | |
| break | if x > 0 { break } | 如果 x > 0,则跳出循环 | 用于中断循环或switch语句 |
| select | select { case <-ch: /…/} | 多路通道选择 | |
| case | case “apple”: fmt.Println(“It’s an apple”) | 在 switch 语句中,定义一个 case | 用于switch或select语句中的分支 |
| default | default: fmt.Println(“It’s default”) | 在 switch 语句中,定义一个默认 case | 用于switch或select语句,表示默认情况 |
| goto | goto myLabel | 跳转到 myLabel 标签(不推荐) | |
| go | go doSomething() | 在新的 goroutine 中执行 doSomething() 函数 | |
| defer | defer fmt.Println(“bye”) | 延迟执行 fmt.Println(“bye”) 直到函数退出 | |
| return | return x + y | 从函数中返回 x + y |
二、Golang数据类型
2.1 Golang数据类型简介
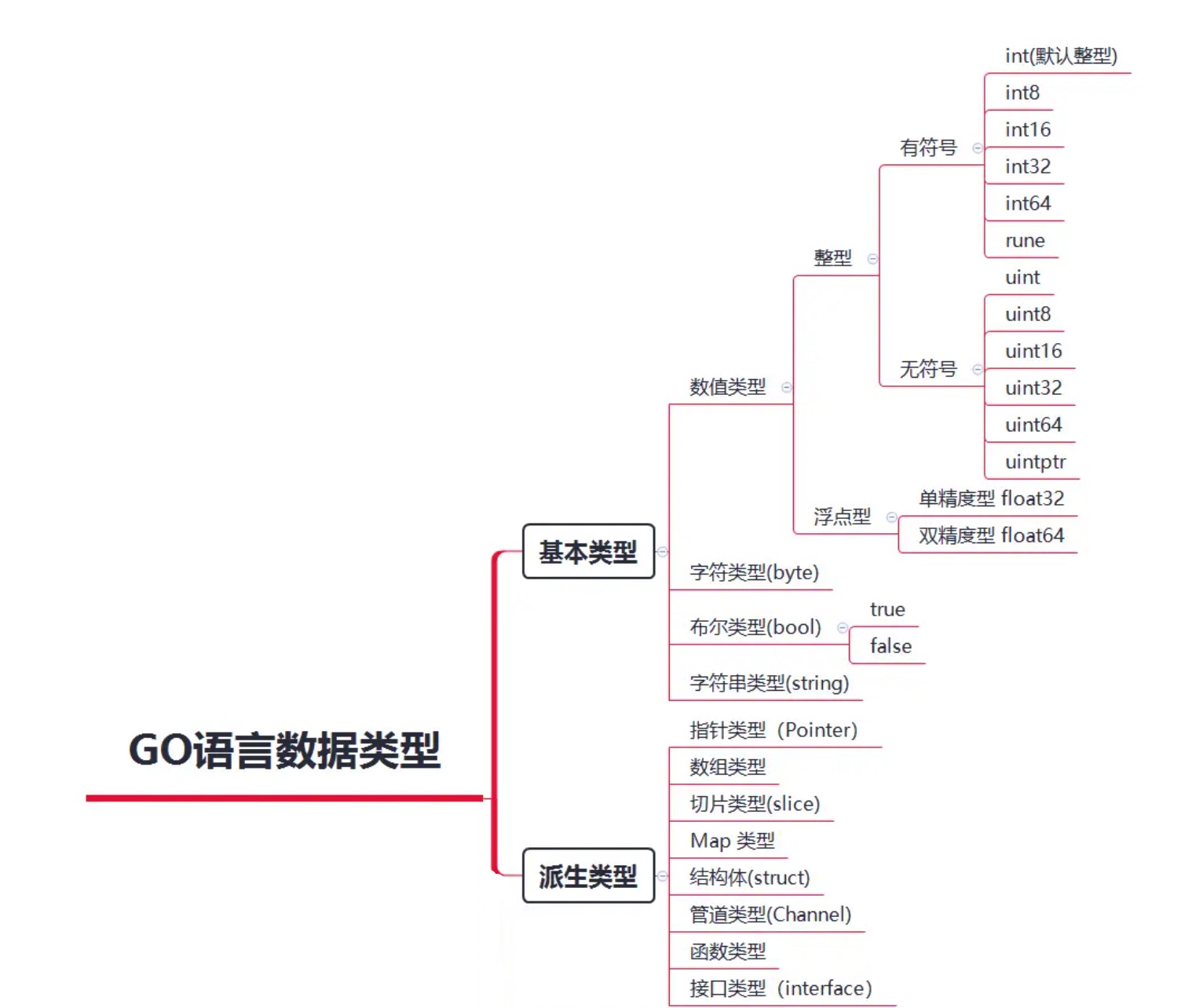
Golang 中的数据类型按数据类别(kind)分为以下几种数据类型:
- 布尔型:布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。
- 数字类型:整型 int 和 浮点型 float32、float64,Go 语言支持整型和浮点型数字,并且支持复数,其中数据类型的位运算采用补码。
- 字符串类型: 字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。
- 派生类型:包括 指针类型(Pointer)、数组类型(Array)、切片类型(slice)、Map 类型、结构化类型(struct)、 Channel 类型、 函数类型、 接口类型(interface)。
2.2 Golang数据存储方式
Golang 中数据类型按存储方式 有两大类数据类型:
- 值类型: 也叫基本数据类型, 包括数值类型、bool、string、数组(array)、结构体(struct);
- 引用数据类型:指针、slice切片、chan管道、map映射、以及 interface接口;
值类型:变量直接存储值,值类型的数据一般存储在栈内存空间中,栈在函数调用完成(返回时)栈内存会被回收释放。 引用类型:变量存储的是一个内存地址,这个内存地址存储最终的值,引用数据类型的数据一般存储在堆内存空间中,通过 GC 回收。
2.3 Golang基本数据类型
1、bool 类型
Golang 中以 bool 关键字声明布尔类型数据,布尔型的值只可以是 true 或者 false。代表条件成立(真)或条件不成立(假),bool类型有以下几个特性;
- 布尔类型变量的默认值为 false;
- Golang 中不允许将整型强制转换为布尔型;
- 布尔型无法参与数值运算,也无法与其它类型进行转换;
2、Golang数值类型
1)整型
整型就是整数,不同的整数类型,占用的内存空间也不同,主要有 int、int8、int16、int32、int64、uint、uint8、uint16、uint32、uint64;
有符号整型:
- int8: 有符号 8 位整型 -128(-2^7^) 到 127(2^7^-1)
- int16: 有符号 16 位整型 -32768(-2^15^) 到 32767(2^15^-1)
- int32: 有符号 32 位整型 -2147483648(-2^31^) 到 2147483647(2^31^-1)
- int64: 有符号 64 位整型 -9223372036854775808(-2^63^) 到 9223372036854775807(2^63^-1)
- int:有符号整型,在 32 位系统上通常为 32 位整型;在 64 位系统上则为 64 位整型;
无符号整型:
- uint8: 无符号 8 位整型 0 到 255(2^8^-1)
- uint16: 无符号 16 位整型 0 到 65535(2^16^-1)
- uint32: 无符号 32 位整型 0 到 4294967295(2^32^-1)
- uint64: 无符号 64 位整型 0 到 18446744073709551615(2^64^-1)
- uint:无符号整型,在 32 位系统上通常为 32 位整型;在 64 位系统上则为 64 位整型;
其它整数类型:
- byte:与uint8等价(uint8的别名),用于存储 ASCII码 字符,详见下一篇《Golang字符串》讲解;
- rune:与 int32一样(int32的别名),表示一个 unicode码,详见下一篇《Golang字符串》讲解;
- uintptr:用于存储指针(内存地址),在 32 位系统上通常为 32 位宽;在 64 位系统上则为 64 位宽;
Go 语言的 int、uint 和 uintptr 类型 是不可移植的类型,其长度根据宿主机的机器字长决定:
- 在 32 位系统上通常为 4字节 32位宽;
- 在 64 位系统上则为 8字节 64位宽;
Go 语言中可以使用 type 关键字来给已经存在的(基本数据类型 或 自定义的 struct、interface、func 等)类型取别名,语法为:
|
|
- TypeAlias 只是 Type 的别名,本质上 TypeAlias 与 Type 是同一个类型。
- Type可以是一些基本的数据类型,如 string、整型、浮点型、布尔等数据类型,也可以是已经定义过(已经存在)的struct、interface等。
例如在 Golang中 byte 和 rune 的定义如下:
|
|
Go 语言中整数默认声明为int型:
|
|
查看变量的字节大小和数据类型:
|
|
2)浮点型
浮点数类型就是带小数点的数值类型,有 float32、float64;
- float32: IEEE-754 32 位浮点型数
- float64: IEEE-754 64 位浮点型数
浮点数在机器中存放的形式:浮点数= 符号位+指数位+尾数位 浮点数都是有符号的数据类型
浮点数使用细节:
- 通常情况下应该使用
float64,因为它比float32更精确 - Golang 的浮点型默认声明为
float64类型 - 浮点型常量有两种表示形式:
- 十进制数形式:如 5.12、.512(必须有小数点,0.512)
- 科学计数法形式:如 5.1234e2 = 5.1234 * 10^2^、5.12E-2 = 5.12/(10^2^) (e / E 等效)
3)复数
- complex64: 32 位实数和虚数
- complex128: 64 位实数和虚数
4)强制类型转换
Golang 中只有强制类型转换,没有隐式类型转换。强制类型转换语法只能在两个类型之间支持相互转换的时候使用。
强制类型转换 的基本语法为:type(variable),可转换的数据包括变量、表达式、函数返回值等。 如下代码:
|
|
3、Golang字符串类型
1)字符类型
Golang中使用 byte类型 存储单个(ASCII码)字符;
|
|
Tips:
byte与uint8等价,用于存储 ASCII码 字符
字符类型使用细节:
- 字符常量是用单引号(’’)括起来的单个字符
例如:
var c1 byte = 'a' - GO中允许使用转义字符
'\'来将后面的字符转换为特殊字符 例如:var c3 char = '\n'\n 表示换行符 - Go语言的字符使用UTF-8编码(兼容ASCII码)
- 在Go中,字符的本质是一个整数,直接输出字符时,输出的是该字符在UTF-8编码表中对应的编码值
- 可以直接给某个变量赋一个整数值,然后按
%c格式化输出时会输出该数字对应的UTF-8编码字符 - 字符类型是可以进行运算的,相当于一个整数,因为它们都对应有Unicode码
Tips: UTF-8 编码是在互联网上使用最广的一种 Unicode 编码的实现方式;UTF-8 是一种变长的编码方式,编码规则如下:
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 的码点,兼容 ASCII
- 对于需要 n 字节来表示的符号(n > 1),第一个字节的前 n 位都设为 1,第 n+1 位设置为 0;后面字节的前两位一律设为 10,剩下的的二进制位则用于存储这个符号的 Unicode 码点(从低位开始)。
编码规则如下表:
Unicode符号范围(十六进制) |
UTF-8编码方式(二进制) |
|---|---|
| 00000000 - 0000007F | 0xxxxxxx |
| 00000080 - 000007FF | 110xxxxx 10xxxxxx |
| 00000800 - 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 00010000 - 0010FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
2)字符串类型
字符串定义:var str string
字符串一旦赋值,就不能修改,在go中字符串是不可变的
字符串有两种表示方式:双引号("");反引号,也叫原意符号(``),如下代码:
|
|
Tips: 反引号 定义的字符,会以字符串的原生形式输出,包括换行符和特殊字符,有防止攻击、输出源代码等效果;
4、基本数据类型的默认值
基本数据类型的变量,在声明后的默认值:
数据类型 |
变量默认值 |
|---|---|
| 整型 | 0 |
| 浮点型 | 0 |
| 字符串 | "" |
| 布尔型 | false |
2.4 Golang自定义数据类型
1、自定义数据类型简介
Go 语言中使用 type 关键字来定义自定义类型。
使用 type 关键字可以以一些基本的数据类型(如 string、整型、浮点型、布尔等数据类型)定义出一个新的数据类型,也可配合使用struct、interface 关键字定义新的复合类型。
|
|
1、结构体
结构体(struct) 是 Go 语言中对数据进行抽象和封装的主要方法。
2、接口(interface)
在Go中,接口(interface)是一种抽象类型,用于定义对象的行为,它没有属性,是仅包含方法名、参数、返回值的未具体实现的方法的集合。 接口(interface)定义了一类对象的行为规范,只定义规范不实现,由具体的对象来实现规范的细节。
2.5 Golang数据类型的底层实现
在 Go 语言中,类型(Type) 是用来描述数据的属性和操作的概念,它定义了数据的内部表示以及对数据进行操作的方法。类型(Type) 在编程语言中起到了限制和约束数据的作用,它决定了数据的取值范围、可用的操作,以及数据在内存中的布局方式。
在 Go 语言中,每个值都有一个明确的类型。例如,整数类型(int)、浮点数类型(float64)、布尔类型(bool)、字符串类型(string)等都是 Go 语言中的内置类型。
此外,我们还可以自定义结构体类型(struct)、接口类型(interface)和 函数类型(func),以及通过类型别名(type)来基于已有类型(基础类型或自定义类型)创建新的自定义类型。
在类型中都有一些公有属性,例如类型的大小、对齐方式、哈希值、标志位、种类、相等性函数、垃圾回收数据、名称和指针等是所有类型最原始的元信息。这些元信息,记录在位于 src/runtime/type.go 的 _type 结构体中,作为每个类型元数据的Header 结构:
|
|
Tips: _type 结构体是 Go 语言中实现 反射机制 和 接口机制 的基础
- 反射机制 可以在运行时动态地获取和操作任何值和类型的信息;
- 接口机制 可以实现多态性和抽象性,让不同的类型可以实现相同的行为;
- kind 基础类型,在 Go 语言中,基础类型是一个枚举常量,有 26 个基础类型,枚举值通过 kindMask 取出特殊标记位
|
|
- str 和 ptrToThis,对应的类型是 nameoff 和 typeOff。分别表示 name 和 type 针对最终输出文件所在段内的偏移量。在编译的链接步骤中,链接器将各个 .o 文件中的段合并到输出文件,会进行段合并,有的放入.text段,有的放入 .data 段,有的放入 .bss 段。nameoff和typeoff就是记录了对应段的偏移量。
对于int、string、bool等单一的基础结构,元信息存储于_type结构体内已经够用了,但对于 array、 chan、 slice、 func等复合型的结构体,它们除了基础的元信息,还需要存储一些额外的元数据,比如键和值类型、参数和返回值数量、结构体字段等,为了存储这些信息,Golang设定了很多内置类型来处理不同类型需要存储不同信息的需求。
对于内置复合类型,大部分也都在runtime/type.go文件里面,这些内置类型都是在 _type 基础上进一步封装而来,举例说明:
|
|
如果是自定义类型,后面还会有一个uncommontype结构体,uncommontype是指向一个函数指针的数组,收集了这类型的实现的所有方法:
|
|
- pkgpath 记录类型所在的包路径
- mcount 记录该类型关联到多少个方法
- xcount 记录该类型的导出型多少个方法
- moff 记录的是这些方法元数据组成的数组,相对于这个uncommontype 结构体偏移了多少字节
例如,基于[]string定义一个新类型myslice,它就是一个自定义类型,可以给它定义两个方法Len和Cap。
myslice的类型元数据中,首先是slicetype类型描述信息,然后在后面加上uncommontype结构体。注意通过uncommontype这里记录的信息,就可以找到myslice的方法元数据列表了。如下图所示:

Tips: 数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。
三、Golang变量
3.1 Golang变量的概念
变量 是表示内存中的一个存储区域,该区域有自己的 名称(变量名) 和 类型(数据类型),通过变量名可以访问(获取或修改)变量(值)。
Golang变量的作用域:
- 局部变量:是在函数(方法)内声明的变量,作用域在函数体内或函数体内的代码块(选择结构代码块、循环结构代码块等等)内,包括函数(方法)形式参数、返回参数、函数(方法)内部定义的变量,只可在函数内 或 函数内的代码块内使用;
- 包级变量: 在函数(方法)外声明的变量,变量名首字母必须小写,也就是 Golang 语言中的不可导出变量,包级变量的作用域是package,只能在同一个 package 中使用;
- 全局变量: 如果包级变量名首字母大写,也就是 Golang 语言中的可导出变量,那么这个变量就成为全局变量,可以在全局使用;
Tips: 可导出 与 不可导出
- 在Golang中,字段(或者方法)的导出与否是由其首字母的大小写决定的;
- 如果一个字段首字母是大写的,它就是可以导出的(即在其它包中可以访问到);
- 如果是小写的,则是不可导出的(即在其它包中不可以访问到);
- 当试图在包外部使用不可导出符号(变量、常量、函数、方法等)时,编译器就会报错。
3.2 Golang变量声明方式
在 Golang 中,变量声明可以使用以下几种方式:
|
|
四、Golang常量
4.1 Golang常量的概念
相对于变量,常量 是恒定不变的值,多用于定义程序运行期间不会改变的那些值。
Tips:
- 常量的声明和变量声明非常类似,只是把 var 换成了const,常量在定义的时候必须赋值;
- 常量中的数据类型只可以是 布尔型、数字型(整数型、浮点型和复数) 和 字符串型;
- 常量可以用
len()、cap()、unsafe.Sizeof()等内置函数去计算值
|
|
4.2 Golang常量的一般声明方式
在 Golang 中,常量声明可以使用以下几种方式:
|
|
4.3 使用 iota 常量声明块(枚举)
iota 是go语言的常量计数器,只能在常量的表达式中使用;
Tips:iota 在 const 关键字出现时将被重置为0,在 const 声明块中 每新增一行常量声明将使 iota 计数一次(iota可理解为const语句块中的行索引)。
iota 特殊常量,可以认为是一个可以被编译器修改的常量。
使用iota能简化定义,在定义枚举时很有用。
常见的iota示例:
|
|
五、Golang函数
5.1 Golang函数简介
函数(Function) 是一段封装了特定功能的可重用代码块,用于执行特定的任务或计算。函数接受输入(参数)(也可以不接收)并产生输出(返回值)(也可以不返回任何数据),可以带有副作用(修改状态或执行其它操作)。
参考博文:https://blog.csdn.net/qqxjx/article/details/131130538
Tips: 只要通过调用函数的名称,就能执行一段定义好的代码程序;
Go语言中,函数被认为是一等公民(First-class citizens),这意味着函数在语言中具有与其他类型(如整数、字符串等)相同的权利和地位。以下是函数在Go语言中被视为一等公民的原因:
- 函数可以作为值进行传递:在Go语言中,函数可以像其它类型的值一样被传递给其它函数或赋值给变量。这意味着可以将函数作为参数传递给其它函数,也可以将函数作为返回值返回(Golang的函数只能返回匿名函数)。
- 函数可以赋值给变量:在Go语言中,可以将函数赋值给变量,然后通过变量来调用函数。这种能力使得函数可以像其它数据类型一样被操作和处理。
- 函数可以匿名定义:Go语言支持匿名函数的定义,也称为闭包。这意味着可以在不给函数命名的情况下直接定义和使用函数,更加灵活和便捷。
- 函数可以作为数据结构的成员:在Go语言中,函数可以作为结构体的成员,从而使得函数与其它数据一起存储在结构体中。这种特性使得函数能够更好地与数据相关联,实现更复杂的功能。
函数作为一等公民的特性使得Go语言具有很高的灵活性和表达力,可以方便地实现函数式编程的思想,并且支持构建高阶函数和函数组合等高级编程技巧。
函数定义格式:
|
|
函数参数列表及调用函数传参:
函数参数列表由 参数变量(形参) 和对应的 参数变量的类型 组成,函数参数列表可以有一个参数,也可以有多个,也可以没有(省略函数参数列表);多个参数之间使用 , 分隔;多个参数时参数变量要么全写,要么全省略;如果多个相邻参数的类型是一样的,可以只保留同一类型最后一个参数的类型声明。
Go语言中所有的函数调用传参(实参)都是 值传递(传值),都是一个拷贝副本。
拷贝的内容有时候是非引用类型(int、string、struct等这些),这样在函数中就无法修改实参内容数据;有的是引用类型(指针、map、slice、chan等这些),这样可以修改实参(引用指向)内容数据。
Golang中所有函数参数传递都是传值(包括指针),slice、map和chan等看上去像引用只是因为它们内部有指针或本身就是指针而已(slice其实是一个含有指针的结构体,而map和slice本身就是一个指针)。在被调函数中修改 slice、map和chan等,对调用者同样可见,所以 slice、map和chan 作为函数实参传递时表现出了引用传递的效果。
一般情况下,对于需要修改原对象值,或占用内存比较大的结构体,选择传指针。对于只读的占用内存较小的结构体,直接传值能够获得更好的性能 和 安全性。
|
|
返回值参数列表
返回值参数列表 由返回值变量和其变量类型组成,返回值变量可以省略,可以有一个返回值,也可以有多个,也可以没有;多个返回值必须用()包裹,并用 , 分隔;多个返回值时返回值变量要么全写,要么全省略。
|
|
函数使用细节说明:
-
函数的参数可以没有、可以有一个或多个,返回值也可以没有、可以有一个或多个;
-
形参列表和返回值列表的数据类型可以是值类型和引用类型;
-
函数命令遵循标识符命名规范: 3.1 首字符不能是数字; 3.2 首字符大写该函数可以被本包文件和其它包文件使用,首字母小写只能被本包文件使用;
-
基本数据类型和数组默认都是值传递的,即进行值拷贝,在函数内修改不会影响到原来的值;
-
如果希望函数内的变量能修改函数外的变量可以传入变量的地址&,函数内以指针的方式操作变量;
-
Go函数不支持重载;
-
在GO中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量,通过该变量可以对函数调用;
-
函数既然是一种数据类型,因此在go中,函数可以作为形参,并且在其它函数内调用;
-
为了简化数据类型定义,go支持自定义数据类型
-
支持对函数返回值命名
1 2 3 4 5func cal(n1 int,n2 int) (sum int, sub int){ sum = n1 + n2 sub = n1 - n2 return }
5.2 Golang函数值(Function Value)
函数,在GO语言中属于头等对象,可以被当作参数传递、也可以作为函数返回值、也可绑定到变量。 如果一个函数像其它类型一样被赋值给变量、作为参数传递给其他函数或从函数返回的,则称为 Function Value。
函数值( Function Value)是函数作为值的表达形式。
|
|
在上面的示例中,函数 add 被赋值给了名为 sumFunc 的函数变量,然后可以通过 sumFunc 来调用 add 函数。
Function Value本质上是一个指针,却不直接指向函数指令入口,而是指向runtime.funcval结构体。
|
|
其中的 fn 字段存储的是函数变量的地址,而根据下面的注释能够知道这个结构的大小是不确定的,实际上编译器会把捕获外层函数的 “捕获列表”追加到fn字段之后,至于捕获列表中存储的是值还是地址,需要根据实际情况而定。

5.3 Golang的init函数
init函数 也称作 初始化函数,是一种没有参数、没有返回值、名为init 的特殊的函数,定义方式如下:
|
|
init的特征:
- init 函数没有输入参数、没有返回值,也未声明,所以无法被显示的调用,不能被引用(赋值给函数变量),否则会出现编译错误
- 一个go文件可以拥有多个init函数,执行顺序按定义顺序执行
- 初始化常量/变量优于 init 函数执行,init 函数先于 main函数自动执行。执行顺序先后为: const常量 > var 变量 > init函数 > main函数
- init初始化函数,会在main函数执行前执行,如果 import 了其它的包中包含init函数,那么会按导入包的顺序优先去扫描导入包中的init函数并执行。

以上这张图片很清晰的反应了init函数的加载顺序:包加载优先级排在第一位,先层层递归进行包加载,每个包中加载顺序为:const > var > init,首先进行初始化的是常量,然后是变量,最后才是init函数。
init函数的使用场景:
- 初始化全局变量或常量。
- 注册/初始化数据库连接。
- 执行配置加载和解析。
- 注册/初始化各种组件或模块。
- 进行一些必要的预处理操作等。
|
|
init() 函数在包被导入时自动执行,因此可以用于进行一些初始化操作。它们可以包含任何合法的 Go 代码,并且可以有多个 init() 函数,按照定义的顺序依次执行。
在实际开发中,init() 函数通常用于进行一些初始化设置、资源的注册和初始化,以及其他需要在程序启动时执行的任务。
5.4 Golang匿名函数
在 Go 语言中,匿名函数是一种没有名称的函数。它是一种函数字面量,可以在代码中直接定义和使用,而无需事先命名。
匿名函数通常用于需要在某个特定位置定义、传递或执行函数的场景,而不需要在其它地方重复使用该函数。它们可以作为变量的值,传递给其它函数,可以从函数中返回给调用者 或 直接调用。
匿名函数的语法类似于普通函数,但没有函数名。它可以包含参数列表、函数体和返回值。
|
|
全局匿名函数:
|
|
|
|
上述代码中,f 可以被任何输入一个整型参数、无返回值的函数赋值,这类似于C++中的函数指针。因此 f 可以看成是一个函数类型的变量。这样,可以动态的改变 f 的功能。
匿名函数可以动态的创建 和 随时改变功能,与之成对比的常规函数必须在包中编译前就定义完毕(定义后不可再改变功能)。
5.5 Golang函数闭包
1、闭包简介
闭包 是 匿名函数 与 匿名函数所引用环境(变量)的组合。匿名函数有动态创建的特性,该特性使得匿名函数不用通过参数传递的方式,就可以直接引用外部的变量,这就类似于 常规函数直接使用全局变量一样,匿名函数和它引用的变量以及环境,类似常规函数引用全局变量处于一个包的环境。
Tips: 闭包 类似于C++ 类中的静态变量 和 静态成员方法;
闭包可以看成函数的高阶应用,是Golang高级开发的必备技能。
|
|
在上述代码中
|
|
就是一个闭包,类比于常规函数+全局变量+包。f 不仅仅是存储了一个函数的返回值,它同时存储了一个闭包的状态。
闭包作为函数返回值
|
|
闭包作为函数返回值返回后被赋予一个函数类型的变量时,同时赋值的是整个闭包的状态,该状态会一直存在外部被赋值的变量中,直到变量被销毁,整个闭包也被销毁。
2、Golang并发中的闭包
Go语言的并发时,一定要处理好循环中的闭包引用的外部变量。如下代码:
|
|
这种现象的原因在于闭包共享外部的变量 i,for循环中每次循环调用 go就会启动一个goroutine,这需要一定时间;但是,启动的goroutine与循环变量递增不是在同一个goroutine,i 处于 主goroutine中。启动一个goroutine的速度远小于循环执行的速度,所以即使是第一个goroutine刚起启动时,外层的循环也执行到了最后一步了。由于所有的goroutine共享 i,而且这个 i 会在最后一个使用它的goroutine结束后被销毁,所以最后的输出结果都是最后一步的 i==5。
可以使用循环的延时在验证上述说法:
|
|
每一步循环至少间隔一秒,而这一秒的时间足够启动一个goroutine了,因此这样可以输出正确的结果。
在实际的工程中,不可能进行延时,这样就没有并发的优势,一般采取下面两种方法:
1、共享的环境变量作为函数参数传递
|
|
输出结果不一定按照顺序,这取决于每个goroutine的实际情况,但是最后的结果是不变的。
可以理解为,函数参数的传递是瞬时的,而且是在一个goroutine执行之前就完成,所以此时执行的闭包存储了当前 i 的状态。
2、使用同名的变量保留当前的状态
|
|
同名的变量 i 作为内部的局部变量,覆盖了原来循环中的 i,此时闭包中的变量不在是共享外循环的 i,而是都有各自的内部同名变量 i,赋值过程发生于循环goroutine,因此保证了独立。
5.6 Golang函数defer的
1、defer机制简介
在Golang中,提供了在函数体执行完毕后执行额外指令(函数)的机制,这一机制称为 延时机制defer。
defer 还有错误捕获、修改函数返回值、资源释放等功能。
在Golang 函数/方法 中使用 defer 关键字调用的每个 defer函数语句,Go运行时都会为其创建一个 defer结构体,并将创建的defer结构体添加到当前函数的 defer栈 中缓存。当函数返回时,Go运行时会依次执行 defer栈中的 defer函数,直到链表为空为止,这个过程是在被调函数返回之前执行的,因此可以保证被延迟执行的函数在函数返回之前被执行。
即使函数执行发生 panic,在panic中断函数或进程前,也要先执行完已经压入 defer栈 中的 defer语句,panic 之后的defer语句由于还没进入 defer栈,所以不会被执行。
在函数/方法中, defer语句 可有可无、可有一条或多条。
defer延时指令的特点:
- 当go执行到一个
defer语句时,会将defer后的语句先压入到一个栈中,然后继续执行函数下一个语句; - 待函数其它语句执行完毕后,在从defer栈中弹出延迟语句依次执行(注: 遵守 栈 后进先出 的特征来出栈);
- 在defer将语句放入到栈中的同时,会将相关的值拷贝入栈(也就是说:defer 调用的函数参数的值 在 defer被定义时就确定了,之后的修改不影响defer调用);
- 在defer中操作调用(defer)函数的局部变量、返回值变量 或 全部变量(非defer调用参数传递),变量的值为函数return 时的值,且在 defer 中的操作(修改)将会反应到 局部变量(函数调用结束后自动回收,所以一般无语)、返回值变量(影响返回值)或 全部变量上。
2、return语句 先于 defer 语句执行
|
|
3、defer 语句按照后进先出的顺序执行执行
|
|
4、panic发生之后的 defer语句不会执行
当函数执行时发生 panic 时候,会首先按照 后进先出 的顺序执行 已经入栈的defer语句(也就是panic发生之前的defer语句),最后才会执行panic,panic发生之后的defer语句由于发生了panic函数终止执行后续语句,故不会入栈、也不会执行(不进不出不执行)。
|
|
Tips: defer 语句的执行顺序是 后进先出先执行,不进不出不执行。
5、defer延时语句通常用于释放函数内创建的资源 或 配合 recover() 用于函数执行过程中的异常处理
defer延时语句 一般用于释放函数内创建的资源(比如: 网络连接、文件句柄、锁等资源)或 配合 recover() 用于函数执行过程中的异常(panic)处理等工作。
|
|
Tips:
- defer 配合 recover() 用于 捕获和处理 函数执行过程中的 panic异常,阻止进程因 panic异常退出导致程序 或 在退出进程之前做一下记录(log)、清理等类型的工作;
- defer - recover() 只能捕获该定义后发生的panic,定义之前的任何 panic不会被捕获,因为defer语句 还未进入 defer栈 中;
6、defer 中发生 panic
|
|
在上面例子中,panic(“panic1”)先 触发 defer 强制出栈,第一个执行触发 panic(“defer panic2)“异常,此时会覆盖前一个异常 panic,最后继续执行 defer, 最终被 recover()捕获住。
7、defer对函数返回值的操作及影响
defer 可以影响函数的具名返回值。
在defer中操作 调用(defer的)函数的 局部变量、具名返回值变量 或 全部变量(非defer调用参数传递),函数使用这些类型变量为 return 的返回值时,在 defer 中的操作(修改)将会反应到 局部变量(函数调用结束后自动回收,所以一般无语)、具名返回值变量(影响返回值)或 全部变量上。
1)返回参数指定返回值变量(具名返回值),return 后不声明返回值 或 声明返回值为具名返回值
|
|
2)返回参数指定返回值变量,return 后声明返回值并且声明的返回值不是返回参数变量
|
|
返回参数不指定返回值变量,return 后声明返回值并且声明的返回值为常量
|
|
返回参数不指定返回值变量,return 后声明返回值并且声明的返回值为函数内局部变量
|
|
Tips: defer 函数调用的执行时机是外层函数设置返回值之后, 并且在即将返回之前
8、defer 函数嵌套子函数
|
|
先分析下执行顺序,有 2 个 defer,则会产生 2 次入栈操作,分别是 f1 、f2。
- f1 入栈时,因为形参 y 是一个函数,则需要执行该函数,故执行一次输出 (x:3 y:0)
- f2 入栈时,因为形参 y 是一个函数,则需要执行该函数,故执行一次输出(x:4 y:0) main 函数执行完后,执行 defer 函数,所有 defer 出栈,所有执行顺序为 f2、f1。所以程序最终输出的结果是:
|
|
9、使用defer实现方法插桩调用
以下代码可用于 计算一个函数的执行时间
|
|
六、Go 命令简介
6.1 go 命令列表
以下是一些常用的Go命令,这些命令可以在Go开发中进行编译、测试、运行和管理依赖项等任务。
| 命令 | 描述 |
|---|---|
| go bug | 启动一个用于报告bug的工具 |
| go build | 编译Go程序包及其依赖项 |
| go clean | 删除编译生成的对象文件和缓存文件 |
| go doc | 显示有关包或符号的文档 |
| go env | 打印有关Go环境的信息 |
| go fix | 更新包以使用新的API |
| go fmt | 使用gofmt重新格式化Go包的源代码 |
| go generate | 通过处理源代码来生成Go文件 |
| go get | 下载并安装包和依赖(下载包和依赖,并对它们进行编译安装) |
| go install | 编译并安装指定包及它们的依赖包 |
| go list | 列出包或模块的信息 |
| go mod | 用于模块维护,包括初始化模块、添加和更新依赖项等 |
| go work | 用于工作区维护,例如查看、清理或打印工作区信息 |
| go run | 编译并运行Go程序 |
| go test | 运行Go程序的测试 |
| go tool | 运行指定的Go工具 |
| go version | 打印Go的版本信息 |
| go vet | 对Go代码进行静态分析,检查可能存在的错误 |
6.2 go build 编译命令
Golang 是强类型编译型语言,因此编译时会将所有依赖编译进同一个二进制文件。
go build 用于编译导入的包,包括import导入的包,以及这些包所依赖的其他关系包,但是并不会将编译后的结果进行安装。
Golang 的编译是以 package main 的 main() 函数作为程序主入口,生成可执行文件。
go build 所在包为main 包时:
- 若 go build 后跟多个 .go文件,编译时会认为这几个文件是在同一个包中,且已第一个 .go 文件名为输出结果(比如:go build ed.go rx.go 输出为 ed 或 ed.exe);
- 如果 go build 后跟一个目录比如:go build /unix/sam 编译结果输出为:sam 或 sam.exe
go build 多个包或非main 包时,会丢弃编译结果,只检查是否可以执行编译。
go build 编译包时,会忽略 _test.go 结尾的文件(即测试文件)
如果 go build 后不跟任何参数则会编译当前目录所对应的代码包,生成目录名 或 目录名.exe 可执行文件。
go build -i:默认不写 -i 情况下,编译后的 .a 文件是不会保存也不会安装到 pkg 目录下的 windows_amd64 目录中,但是只要加上 -i 编译后的 .a 文件就会自动保存到 pkg 目录中,就是说:标记 -i 会使 go build 命令安装那些编译目标依赖的且还未被安装的代码包。
Golang 编译命令格式:
|
|

go build 编译命令参数介绍:
| 参数 | 含义 |
|---|---|
| -o | output 指定编译输出的名称,代替包名 |
| -i | install 安装作为目标的依赖关系的包(用于增量编译提速) |
| -a | 强行对项目所有的代码包(包含标准库中的代码包)进行重新构建,即使它们已经是最新的了 |
| -n | 打印编译期间所用到的命令,仅仅是打印并不真正执行它们 |
| -p n | 指定编译过程中执行各任务的并行数量(确切地说应该是并发数量)。在默认情况下,该数量等于CPU的逻辑核数。但是在darwin/arm平台(即iPhone和iPad所用的平台)下,该数量默认是1 |
| -race | 开启竞态条件的检测。不过此标记目前仅在linux/amd64、freebsd/amd64、darwin/amd64和windows/amd64平台下受到支持 |
| -msan | 使用内存清除器启用互操作。只支持Linux/AMD 64、Linux/ARM 64,并且只有clang/llvm作为主机c+编译器 |
| -v | 打印出那些被编译时的代码包的名字 |
| -x | 打印编译期间所用到的其它命令(且执行),注意它与-n标记的区别 |
| -work | 打印出编译时生成的临时工作目录的路径,并在编译结束时保留它。在默认情况下,编译结束时会删除该目录以下为不常用命令 |
| -asmflags | 此标记可以后跟另外一些标记,如-D、-I、-S等。这些后跟的标记用于控制Go语言编译器编译汇编语言文件时的行为 |
| -buildmode | 此标记用于指定编译模式,使用方式如-buildmode=default(这等同于默认情况下的设置)。此标记支持的编译模式目前有6种。借此,我们可以控制编译器在编译完成后生成静态链接库(即.a文件,也就是我们之前说的归档文件)、动态链接库(即.so文件)或/和可执行文件(在Windows下是.exe文件) go help buildmode |
| -compiler | 此标记用于指定当前使用的编译器的名称。其值可以为gc或gccgo。其中,gc编译器即为Go语言自带的编辑器,而gccgo编译器则为GCC提供的Go语言编译器 |
| -gccgoflags | 此标记用于指定需要传递给gccgo编译器或链接器的标记的列表 |
| -gcflags | 此标记用于指定需要传递给go tool compile命令的标记的列表 |
-installsuffix |
为了使当前的输出目录与默认的编译输出目录分离,可以使用这个标记。此标记的值会作为结果文件的父目录名称的后缀。其实,如果使用了-race标记,这个标记会被自动追加且其值会为race。如果我们同时使用了-race标记和-installsuffix,那么在-installsuffix标记的值的后面会再被追加_race,并以此来作为实际使用的后缀 |
| -ldflags | 此标记用于指定需要传递给go tool link命令的标记的列表 |
| -linkshared | 此标记用于与-buildmode=shared一同使用。后者会使作为编译目标的非main代码包都被合并到一个动态链接库文件中,而前者则会在此之上进行链接操作 |
| -pkgdir | 指定一个目录,并从改目录下加载编译好的.a 文件,并把编译可能产生新的 .a 文件放入到该目录中 |
| -tags | 此标记用于指定在实际编译期间需要受理的编译标签(也可被称为编译约束)的列表 |
| -toolexec | 此标记可以让我们去自定义在编译期间使用一些Go语言自带工具(如vet、asm等)的方式 |
-ldflags 'flag list' 可在 go install、go build、go run、go test中使用:
-s: 去掉符号表-w: 去掉调试信息,不能gdb调试了-X: 设置包中的变量值
-w 和 -s 通常一起使用:go build -ldflags "-s -w" -o xxx,用来减少可执行文件的体积。但删除了调试信息后,可执行文件将无法使用 gdb/dlv 调试。
例:编译的时候,带上编译的人的姓名:
|
|
执行编译好的程序,可以看到 Developer: zhangsan 输出。
编译是动态添加版本相关信息:
|
|
-gcflags:
-N:参数代表禁止优化;-l:参数代表禁止内联;-c int:编译过程中的并发数,默认是1;
go在编译目标程序的时候会嵌入运行时(runtime)的二进制,禁止优化和内联可以让运行时(runtime)中的函数变得更容易调试。
|
|
go tool compile 和 go build -gcflags -S 生成的是过程中的汇编,最终的机器码的汇编可以通过 go tool objdump 生成。
-gcflags 参数不光优化编译的二进制包,还能进行项目的逃逸分析
|
|
- 这一命令中,-m 表示打印出逃逸分析信息,-l 表示禁止内联,可以更好地观察逃逸。
- 从以下输出结果可以看到,发生了逃逸,也就是说指针作为函数返回值的时候,一定会发生逃逸。
|
|
用于项目编译过程展示:项目版本号、日期、git版本、go版本;
|
|
build.sh
|
|
6.3 go clean 命令
go clean命令是Go语言中常用的命令之一,用于清理项目目录下生成的可执行文件、测试结果和临时文件等。
使用go clean命令非常简单,只需在终端中输入以下命令:
|
|
该命令会删除项目目录下生成的可执行文件、测试结果和临时文件等。它会根据项目的构建配置和操作系统的不同,删除不同的文件。
- 清理测试结果:
|
|
该命令会删除项目目录下生成的测试结果缓存文件。
- 清理临时文件:
|
|
该命令会删除项目目录下生成的临时文件和缓存文件。
需要注意的是,go clean命令会删除项目目录下生成的文件,因此在使用该命令之前,建议先备份重要的文件。
参数介绍:
| 参数名 | 说明 |
|---|---|
| -i | 同时删除与可执行文件相关的安装目录 |
| -r | 递归删除。该参数会删除指定目录及其子目录下的文件 |
| -n | 显示将要执行的清理操作,但不实际执行。使用该参数可以查看清理操作的详细信息,而不会真正删除文件 |
| -cache | 清理临时文件和缓存文件。该参数会删除项目目录下生成的临时文件和缓存文件 |
| -testcache | 清理测试结果缓存文件。该参数会删除项目目录下生成的测试结果缓存文件 |
| -modcache | 清理模块缓存文件。该参数会删除项目目录下生成的模块缓存文件 |
| -x | 显示执行的清理操作。使用该参数可以查看清理操作的详细信息,并同时执行清理操作 |
6.4 go run 命令
用于编译并运行 Go 源代码文件。它是一个方便的工具,可以在不生成可执行文件的情况下,直接编译并运行Go程序。常用的参数包括:
-n:打印执行的命令,但不执行。-x:打印执行的命令及参数。-race:启用数据竞争检测。-gcflags:传递参数给编译器,如优化级别等。-buildmode:指定编译模式,如共享库或插件等。-ldflags:传递参数给链接器。-trimpath:去除输出中的文件路径信息。-memprofile:写入内存概要文件。-cpuprofile:写入CPU概要文件。-blockprofile:写入阻塞概要文件。-timeout:执行超时时间。-args:传递参数给程序,放在最后。
例如:
|
|
此命令会启用竞争检测和移除调试信息,并传递args参数给main.go执行。
6.5 go test 命令
go test命令用于运行测试代码并生成测试报告。它可以自动识别项目中的测试文件,并执行其中的测试函数,然后输出测试结果。
使用go test命令非常简单,只需在终端中输入以下命令:
|
|
该命令会自动在当前目录下寻找以_test.go结尾的文件,并执行其中的测试函数。测试函数的命名必须以Test开头,并接着是要测试的函数名,例如TestAdd()。
除了默认的输出结果外,go test命令还支持一些可选的参数,例如-v参数可以输出更详细的测试结果,-cover参数可以生成代码覆盖率报告等。参数说明:
参数 |
说明 |
|---|---|
| -v | 显示详细的测试信息。使用该参数可以查看每个测试用例的详细输出 |
| -run | 指定要运行的测试用例的正则表达式。使用该参数可以选择性地运行符合指定正则表达式的测试用例 |
| -cover | 生成代码覆盖率报告。使用该参数可以生成代码覆盖率报告,显示测试代码对被测试代码的覆盖情况 |
| -coverprofile | 指定生成的代码覆盖率文件的名称和路径。使用该参数可以将生成的代码覆盖率报告保存到指定的文件中 |
| -covermode | 指定代码覆盖率的模式。该参数可以用于指定代码覆盖率的计算方式 |
| -bench | 运行性能测试。使用该参数可以运行性能测试,并输出性能测试的结果 |
| -benchmem | 显示内存分配的统计信息。使用该参数可以显示性能测试过程中的内存分配情况 |
| -benchtime | 指定性能测试的运行时间。该参数可以用于指定性能测试的运行时间,例如设置为"10s"表示运行10秒 |
| -timeout | 指定测试的超时时间。该参数可以用于指定测试的超时时间,例如设置为"5s"表示测试超过5秒将被终止 |
| -short | 运行短时间的测试。使用该参数可以运行短时间的测试,例如跳过一些耗时较长的测试用例 |
go test 命令的参数可以组合使用,以满足不同的测试需求。例如,可以使用go test -v -cover命令来运行测试并生成代码覆盖率报告。
6.6 go tool 命令
go tool 命令 运行指定的go工具,命令格式:
|
|
可选参数:
- -n 打印要执行的命令, 但是不真正的执行
go tool 工具列表:
Tips: 各个工具源码位于
${GOROOT}/src/cmd目录下。
|
|
查看工具帮助文档
|
|
go tool compile:
go tool compile 编译由传入的file组成的单独的包。默认的,产物是一个.o的的中间目标文件 (intermediate object file) 。 目标文件可以被用来与其他的目标文件组成包集合 (package archive) , 也可以直接传递给链接器使用。
Tips: compile本身也是go实现的,其源码位于src/cmd/compile目录下
生成的目标文件包含包本身暴露的符号的类型信息, 也包含包引用的其他包的符号的类型信息。 所以在编译调用一个包的包时, 只需要读取被调用的包的目标文件即可。
用法:
|
|
- file一定需要是一整个package所有的代码文件。
flags参数:
- -D path 用于本地引用依赖的相对路径。
- -I dir1 -I dir2 在查询完$GOROOT/pkg/$GOOS_$GOARCH之后, 进一步从dir1和dir2查询需要的依赖包。
- -L 在错误信息中展示完整的文件路径。
- -N 禁用优化。
- -S 将code的汇编输出到标准输出。
- -S -S code和data都输出。
- -V 输出编译器的版本。
- -asmhdr file 将汇编的头写到file中。
- -buildid id 将id作为build_id写入输出的元数据中。
- -blockprofile file 将编译时的block profile写入到file中。
- -c int 编译时并发度,默认是1,表示不并发。
- -complete 假定包不含有非go的部分。
- -cpuprofile file 将编译时的CPU profile写入到file中。
- -dynlink 允许引用在共享库中的go符号。
- -e 移除错误数量的上限。
- -goversion string 定义使用的go tool版本, 用于runtime的版本和goversion不匹配的情况。
- -h 当第一个错误被发现时停止,并输出堆栈trace。
- -importcfg file 从file读取配置。 配置包含importmap/packagefile。
- -importmap old=new 在编译时,将对old的引用更换为new。 这个flag可以有多个来设置多个映射。
- -installsuffix suffix 从$GOROOT/pkg/$GOOS_$GOARCH_suffix查找包, 而不是$GOROOT/pkg/$GOOS_$GOARCH。
- -l 禁用内联。
- -lang version 使用的语言版本,如-lang=go1.12, 默认使用当前版本。
- -linkobj file 将面向链接器的目标文件写入到file。
- -m 输出优化决定。可以传入整数 (-m=10) ,越大的整数输出越详细。
- -memprofile file 输出编译时的内存profile到file。
- -memprofilerate rate 设置编译时的runtime.MemProfileRate为rate。
- -msan 开启内存检查器 (memory sanitizer) 。
- -mutexprofile file 编译时的mutex profile写入到file。
- -nolocalimports 禁用本地引用/相对引用。
- -o file 将目标文件写入到file。
- -p path 判断如果增加了对于path的引用是否会出现循环引用的问题。
- -pack 输出打包过的格式,而不是目标文件。
- -race 开启数据竞争检测。
- -s 输出对于可简化掉的Composite literals的警告。
- -shared 生成可以链接到共享库的代码。
- -spectre list 在list中启用减轻幽灵攻击的机制。
- -traceprofile file 将执行trace写入到file中。
- -trimpath prefix 移除记录的源文件路径的前缀。
关于调试信息的flag:
- -dwarf 生成DWARF符号。
- -dwarflocationlists 在优化模式中, 向DWARF增加位置列表 (location list)。
- -gendwarfinl int 生成DWARF的内联信息记录。
调试编译器本身的标志:
- -E 调试符号导出。
- -K 调试缺失的行号。
- -d list 打印有关列表中项目的调试信息,尝试 -d help 以获得更多信息。
- -live 调试活性分析。
- -v 增加调试详细程度。
- -% 调试非静态初始值设定项。
- -W 类型检查后调试解析树。
- -f 调试堆栈帧。
- -i 调试行号堆栈。
- -j 调试运行时初始化的变量。
- -r 调试生成的包装器。
- -w 调试类型检查。