一、Fluentbit 简介
1.1 Fluentbit 简介
Fluent Bit(简称为Fluent-Bit 或 Fluentbit)是一个开源的、轻量级的日志数据收集器(log collector)和 转发器(log forwarder),旨在高效地收集、处理和转发日志数据。它是Fluentd项目的一个子项目,旨在解决日志收集和处理的特定需求。
1.2 Fluentbit 主要特点和功能
- 轻量级:FluentBit被设计为轻量级的日志收集器,具有较小的资源占用,适用于在资源受限的环境中运行,例如边缘设备或嵌入式系统。
- 高性能:由于其轻量级设计,FluentBit能够在高吞吐量的场景下表现出色,可以处理大量的日志数据。
- 多种输入和输出插件:FluentBit支持多种输入和输出插件,使其能够从不同的数据源收集日志,并将日志转发到多种目标。
- 可扩展性:FluentBit可以通过插件进行扩展,用户可以根据需求编写自定义插件来实现特定功能。
- 支持多种日志格式:FluentBit支持解析和处理多种日志格式,如JSON、Grok、Syslog等。
- 容器友好:FluentBit特别适用于容器化环境,可以与容器编排工具(如Kubernetes)和容器运行时(如Docker)集成,以收集容器日志。
- 跨平台:FluentBit支持多个操作系统平台,包括Linux、Windows、macOS等。
二、Fluentbit 的架构
Fluent Bit 的架构是模块化和高度可扩展的,它由多个核心组件和插件构成,每个组件负责不同的功能。以下是 Fluent Bit 的主要组件和架构:
- 输入插件(Input Plugins):输入插件负责从不同的数据源收集日志数据。Fluent Bit 支持多种输入插件,包括文件输入、系统日志输入、TCP/UDP 输入、HTTP 输入等。每个输入插件能够收集特定类型的日志数据,并将其传递给处理插件。
- 处理插件(Filter Plugins):处理插件负责对收集到的日志数据进行处理和转换。它可以应用过滤、解析、格式化等操作,以便在后续处理中进行进一步的处理或存储。Fluent Bit 提供多种处理插件,如解析 JSON、Grok 解析、重命名字段等。
- 输出插件(Output Plugins):输出插件负责将处理后的日志数据发送到目标存储或传输系统。Fluent Bit 支持多种输出插件,如 Elasticsearch、InfluxDB、Kafka、Amazon S3 等。通过输出插件,用户可以将日志数据传输到不同的目标,以便进一步的存储和分析。
- Buffer:Fluent Bit 有一个缓冲区(Buffer)用于临时存储日志数据,以防止数据丢失或出现流量波动。数据在输入插件收集后存储在缓冲区中,然后逐步传递到处理插件和输出插件。
- 主引擎(Engine):主引擎是 Fluent Bit 的核心,它负责协调输入插件、处理插件和输出插件之间的数据流动。主引擎根据配置文件指定的插件组合和过滤条件,将数据从输入插件传递给处理插件,再传递给输出插件,同时通过缓冲区来处理数据流。
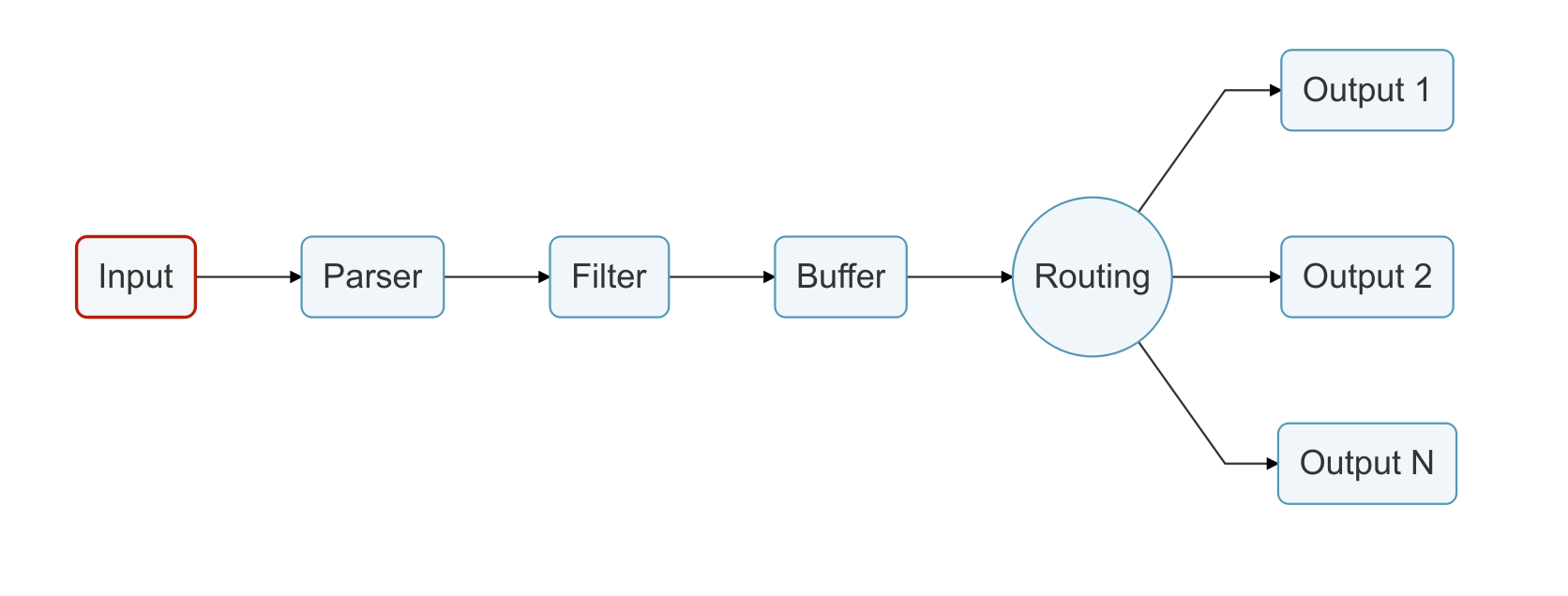
通过这种模块化的架构,Fluent Bit 允许用户根据需求选择合适的输入、处理和输出插件,以构建高度定制化的日志收集和传输系统。它的轻量级和高性能使得它在各种环境中都能表现出色,特别适用于容器化和云原生应用场景。

三、Fluentbit 使用场景
FluentBit被广泛用于日志采集和传输,特别是在容器化和云原生应用中,它可以作为轻量级的日志收集器在各种环境中运行,将日志数据传输到中央日志存储或其他目标,以便进行日志分析和监控。同时,它与Fluentd之间的兼容性也使得用户能够灵活地搭建日志处理和分析系统,根据需求选择最适合的组件。
Fluent Bit 在以下场景下使用得非常广泛:
- 容器化环境:FluentBit 在容器化平台中特别有用,如 Kubernetes、Docker 等。它可以收集容器日志,并将其转发到中央日志存储或日志分析系统。由于其轻量级和高性能的特点,它适用于在容器中运行,并且不会给容器增加太大的负担。
- 边缘计算设备:FluentBit 作为轻量级的日志收集器,适用于边缘设备或资源有限的环境。在 IoT 和边缘计算场景中,FluentBit 可以帮助收集设备产生的日志,并将其转发到远程服务器或云端进行存储和分析。
- 云原生应用:在云原生应用中,特别是使用微服务架构的应用,往往有许多小型服务生成日志。Fluent Bit 可以在这些服务中收集日志,并将它们集中到中央日志存储,以方便监控和故障排查。
- 多数据源日志收集:FluentBit 支持多种输入插件,可以从不同的数据源收集日志,如文件、系统日志、TCP、UDP、HTTP 等。因此,它适用于收集多种类型和来源的日志数据。
- 日志转发和集中式存储:FluentBit 可以将收集到的日志数据转发到各种目标,如 Elasticsearch、InfluxDB、Kafka、Amazon S3 等,或者发送到中央日志收集系统(如 Fluentd)以进行进一步处理和存储。
总的来说,FluentBit 是一个灵活、轻量级且高性能的日志收集器和转发器,适用于各种不同的场景,包括容器化环境、边缘设备、云原生应用和多数据源日志收集等。它可以帮助用户收集和转发大量的日志数据,并将其有效地传送到中央日志存储或日志分析系统,以进行监控、故障排查和数据分析。
四、使用 Fluentbit 采集K8s集群日志
4.1 部署 & 测试
1、获取安装 fluent-bit
|
|
解压后可以修改默认的 values.yaml 文件, 按需输出到 es 或者 kafka 集群
2、采集日志到转发到 es 集群
|
|
服务部署完成后,过一段时间就可以在 es 中看到采集的日志。
3、采集日志到转发到 kafka 集群
|
|
服务部署完成后,过一段时间就可以在 kafka 中看到采集的日志。
4.2 注意事项
1、若直接向 es 写入数据,需要设置 Logstash_Format Off,否则会自动生成 logstash-2022.08.16 格式的索引。
2、默认会采集很多不必要的 pod 字段,因此需要 filter,例如 Labels Off 和 Annotations Off 会去掉 Label 和 Annotation 信息, 更多内容可以参考 https://docs.fluentbit.io/manual/pipeline/filters/kubernetes
3、使用 DaemonSet 部署的 agent 默认不会部署在有污点的节点上,例如 master节点 和 用户加污点的节点。为了让这类节点能正常部署上 agent,需要在 DaemonSet 中加如下参数(允许任何污点):
|
|
4、fluent-bit 添加字段,如果需要加入字段,可以通过 FILTER 的 modify 模块来添加字段,例如给不同的集群加上对应的 cluster 信息,那么可以用如下方式
|
|
5、fluent-bit 过滤掉指定命名空间日志
如果需要过滤掉某些命名空间日志,只需要在INPUT中增加 Exclude_Path 即可,如下过滤掉 monitoring 和 kube-system 命名空间的日志
|
|
更详细的安装配置请参见官方指引文档:https://docs.fluentbit.io/manual/installation/getting-started-with-fluent-bit