一、无继承关系类对象的内存模型
C++ 中类是创建对象的模板,不占用内存空间,不存在于编译后的可执行文件中;而对象是实实在在的数据,需要内存空间来存储。对象被创建时会在data段、栈区 或者 堆区 分配内存。
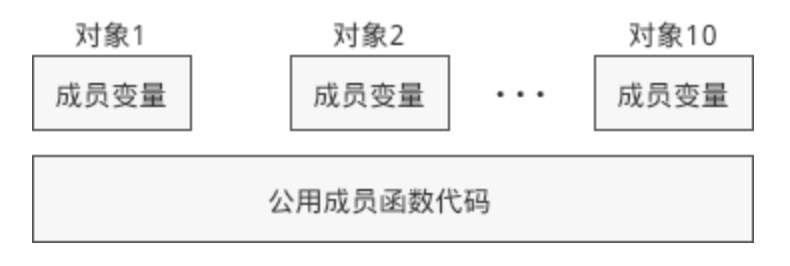
不同对象的成员变量的值一般不同,编译时需要单独分配内存空间来存储。但是不同对象的成员函数的代码是一样的,如果为每一个对象分配单独的内存空间(在text 段)来存储成员函数,可能会浪费了不少空间,所以编译器会将成员变量和成员函数分开存储:分别为每个对象的成员变量分配内存,但是所有对象都共享同一段函数代码。
Tips:
- const 成员变量 与 普通成员变量的内存分配位置相同。
- static 成员变量 与 独立存储在 data 区, 与普通成员变量的内存分配位置不相同, 不占用对象内存空间。
成员变量可能在 data 区(全局对象 和 内的静态变量)、栈区(局部对象) 或 堆区(new 或 malloc分配的内存对象) 分配内存,成员函数在 代码区 分配内存。
使用 sizeof 获取对象所占内存的大小不包含成员函数 和 静态成员变量(在data 区分配)所占内存大小。 示例:
|
|
类是一种复杂的数据类型,也可以使用 sizeof 求得该类型对象的内存大小。在使用 sizeof 计算类对象的大小时,只计算了成员变量(不包括static 成员)的大小,并没有把成员函数也包含在内。
成员函数 由编译器编译时在 text 段 分配存储空间进行存储。
Tips: 在 使用sizeof 计算 类对象占用的内存空间(字节数)时,可能会存在内存对齐导致类对象实际占用的内存空间大小超过 所有成员变量(静态成员变量除外)占用的内存空间总和。
没有定义成员变量的类的对象,要占用 1字节的内存空间(占位)。
|
|
总结:没有继承时类对象的 成员变量 和 成员函数会 分开存储:
- 对象的内存中只包含成员变量,存储在栈区或堆区(使用 new 创建对象);
- 成员函数与对象内存分离,存储在代码区。
二、派生类对象的内存模型
2.1 单继承下派生类没有成员变量遮蔽时的对象内存模型
有继承关系时,单继承派生类对象的内存模型可以看成是基类成员变量和新增成员变量的总和,而所有成员函数仍然存储在另外一个区域 —— 代码区,由所有对象共享。
请看下面的代码:
|
|
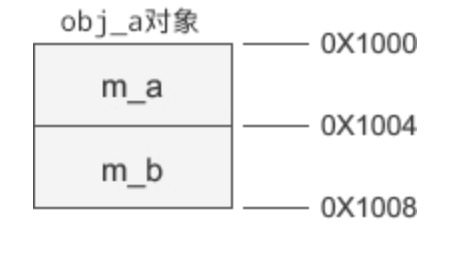
obj_a 是基类对象,obj_b 是派生类对象。假设 obj_a 的起始地址为 0X1000,那么它的内存分布如下图所示:
假设 obj_b 的起始地址为 0X1100,那么它的内存分布如下图所示:
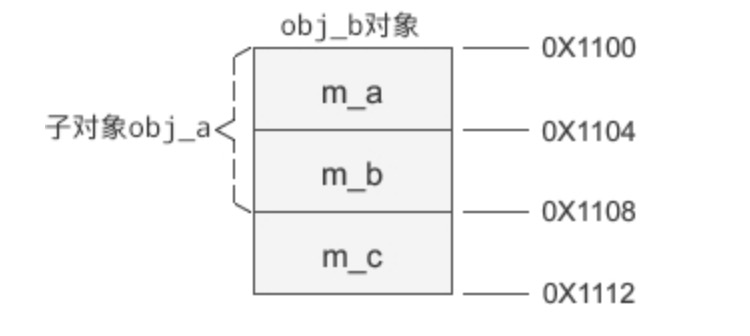 可以发现,基类的成员变量排在前面,派生类的排在后面。
可以发现,基类的成员变量排在前面,派生类的排在后面。
存在多层继承时依次类推,示例:
|
|
假设 obj_c 的起始地址为 0X1200,那么它的内存分布如下图所示:
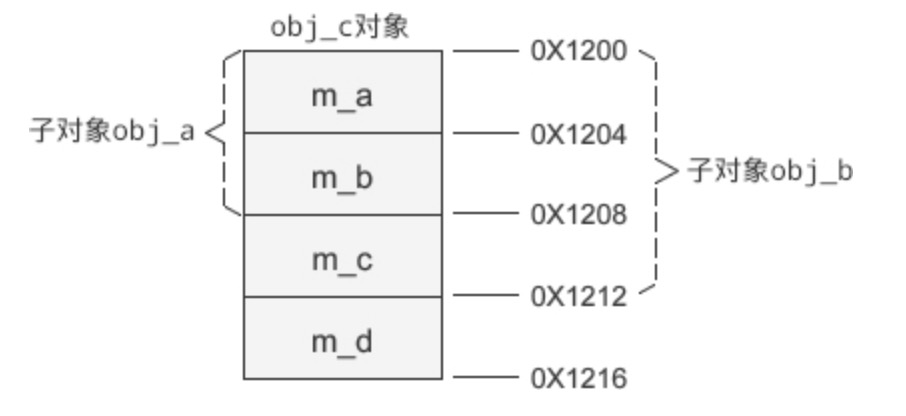
总结: 成员变量按照派生的层级依次排列,新增成员变量始终在最后。
2.2 单继承下派生类有成员变量遮蔽时的对象内存模型
更改上面的 C 类,让它的成员变量遮蔽 A 类和 B 类的成员变量: 示例:
|
|
假设 obj_c 的起始地址为 0X1300,那么它的内存分布如下图所示:
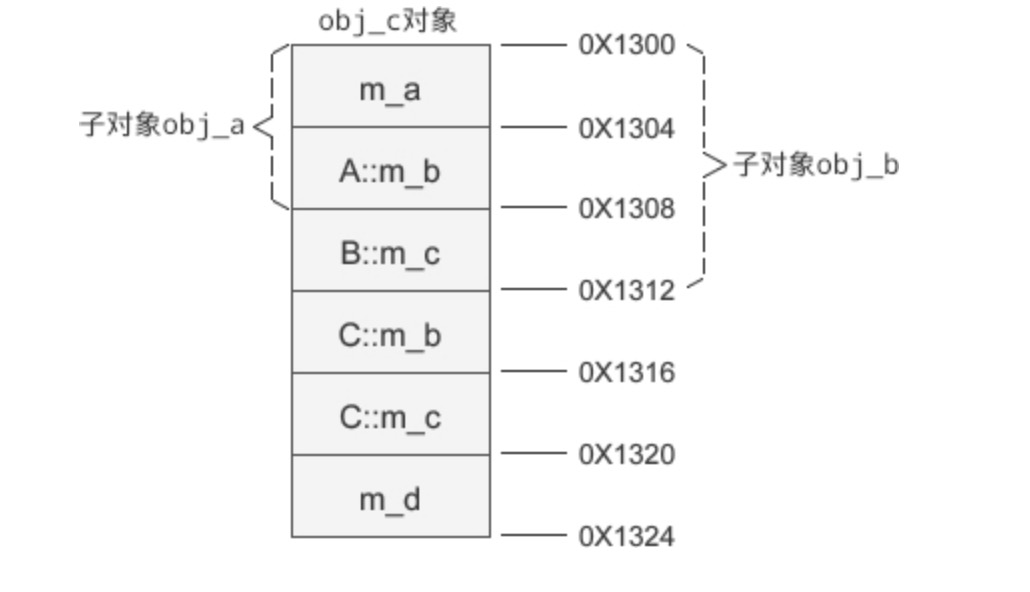
当基类 A、B 的成员变量被遮蔽时,仍然会留在派生类对象 obj_c 的内存中,C 类新增的成员变量始终排在基类 A、B 的后面。
总结: 在派生类的对象模型中,会包含所有基类的成员变量。这种设计方案的优点是访问效率高,能够在派生类对象中直接访问基类变量,无需经过好几层间接计算。
2.3 多继承时的派生类对象内存模型
和单继承派生类的对象内存模型一样,多继承下的派生类对象的内存模型可以看成是多个基类成员变量和新增成员变量的总和,而所有成员函数仍然存储在另外一个区域 —— 代码区,由所有对象共享。
多个基类成员变量的顺序按基类成员变量的定义顺序 和 继承是 基类的继承顺序 依次排列。 如下面的代码:
|
|
运行结果:
|
|
A、B 是基类,C 是派生类,假设 obj_c 的起始地址是 0X1000,那么 obj_c 的内存分布如下图所示:
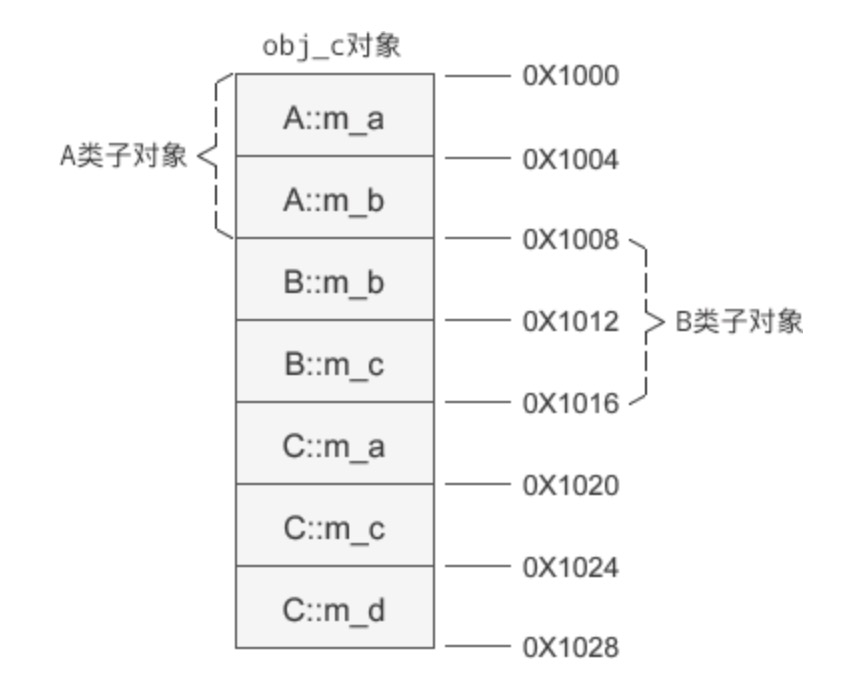 基类对象的排列顺序和继承时声明的顺序相同。
基类对象的排列顺序和继承时声明的顺序相同。
Tips: 多重继承下的派生类有成员变量遮蔽时的对象内存模型 与 单继承下派生类有成员变量遮蔽时的对象内存模型 相似。
三、虚继承派生类对象的内存模型
前面介绍过, 对于普通继承(单继承、多层继承、多重继承),基类子对象始终位于派生类对象的前面(也即基类成员变量始终在派生类成员变量的前面),而且不管继承层次有多深,它相对于派生类对象顶部的偏移量是固定的。
对于虚继承,恰恰和普通继承相反,大部分编译器会把 虚基类 成员变量放在派生类成员变量的后面,这样随着继承层级的增加,基类成员变量的偏移就会改变,就得通过其他方案来计算偏移量。 示例:
|
|
此示例中 类A 是 类B 的虚基类,obj_b、obj_c、obj_d 的内存模型就会发生变化,如下图所示:
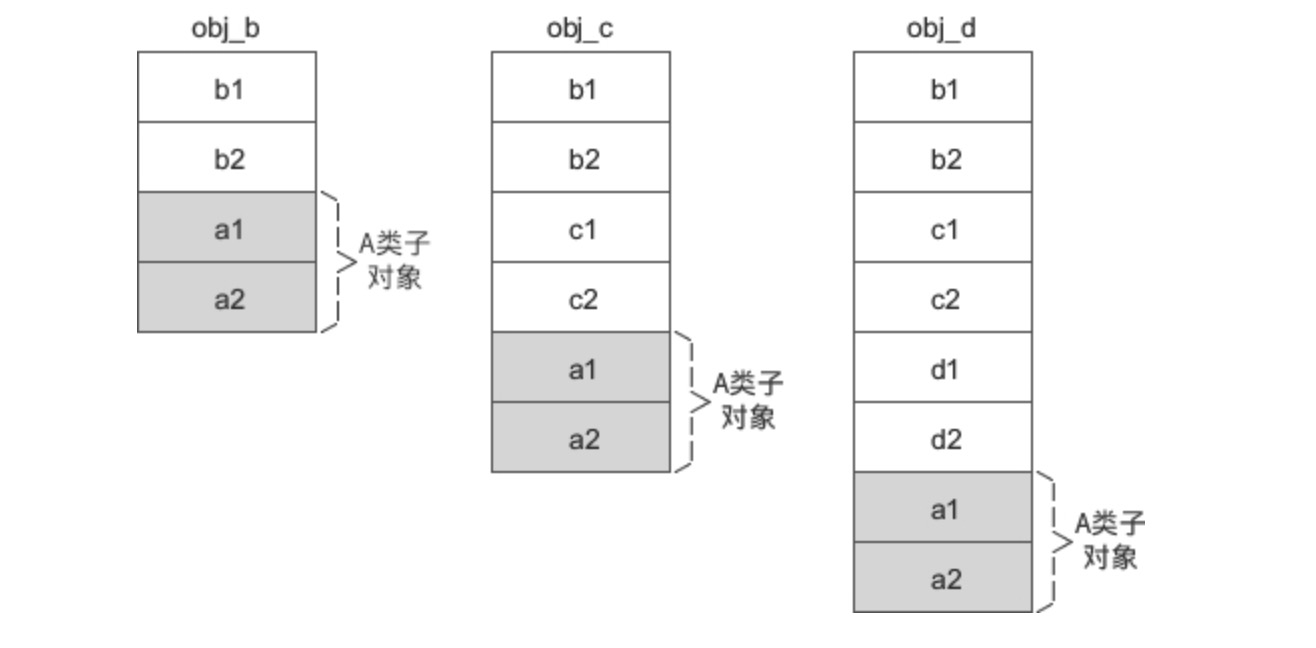 不管是虚基类的直接派生类还是间接派生类,虚基类的子对象始终位于派生类对象的最后面。
不管是虚基类的直接派生类还是间接派生类,虚基类的子对象始终位于派生类对象的最后面。
假设 A 是 B 的虚基类,B 又是 C 的虚基类,那么各个对象的内存模型如下图所示:
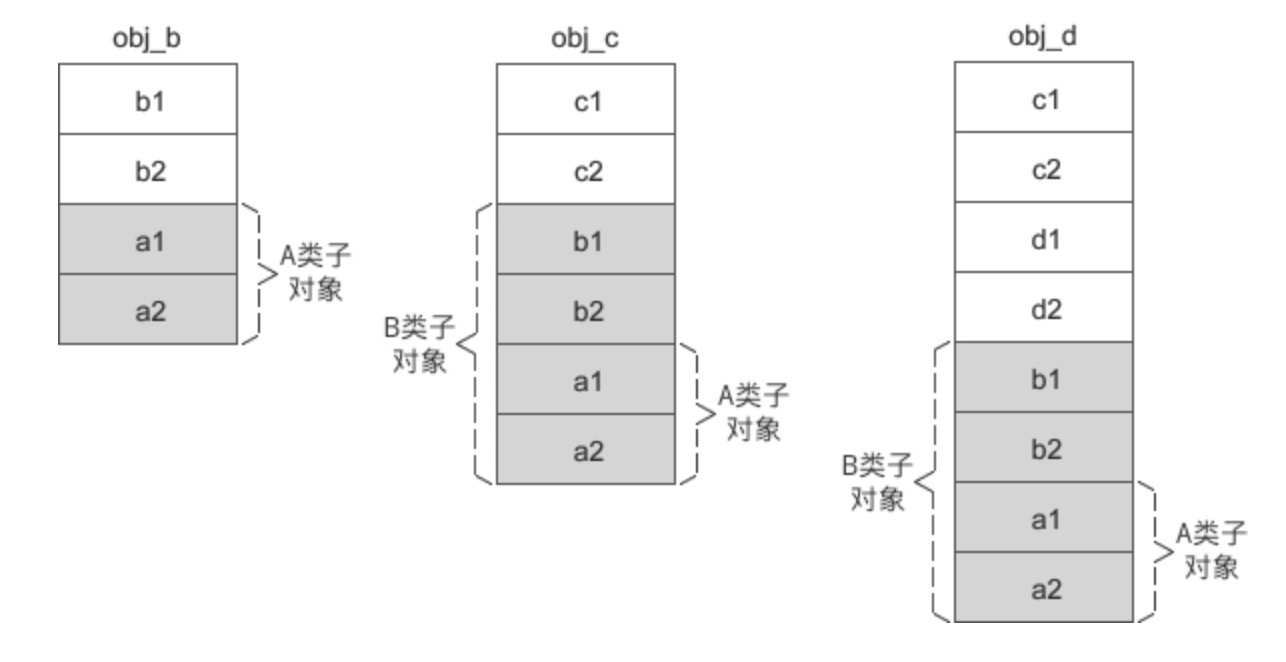
从上面的两张图中可以发现,虚继承时的派生类对象被分成了两部分:
- 不带阴影的一部分偏移量固定,不会随着继承层次的增加而改变,称为 固定部分。
- 带有阴影的一部分是虚基类的子对象,偏移量会随着继承层次的增加而改变,称为 共享部分。
当要访问对象的成员变量时,需要知道对象的首地址和变量的偏移,对象的首地址很好获得,关键是变量的偏移。对于固定部分,偏移是不变的,很好计算;而对于共享部分,偏移会随着继承层次的增加而改变,这就需要设计一种方案,在偏移不断变化的过程中准确地计算偏移。各个编译器正是在设计这一方案时出现了分歧,不同的编译器设计了不同的方案来计算共享部分的偏移。
Tips: 对于虚继承,将派生类分为固定部分和共享部分,并把共享部分放在最后,几乎所有的编译器都在这一点上达成了共识。主要的分歧就是如何计算共享部分的偏移,可谓是百花齐放,没有统一标准。
cfront解决方案:
早期的 cfront 编译器会在派生类对象中安插一些指针,每个指针指向一个虚基类的子对象,要存取继承来的成员变量,可以使用指针间接完成。
1、 如果 A 是 B 的虚基类,那么各个对象的实际内存模型如下所示:
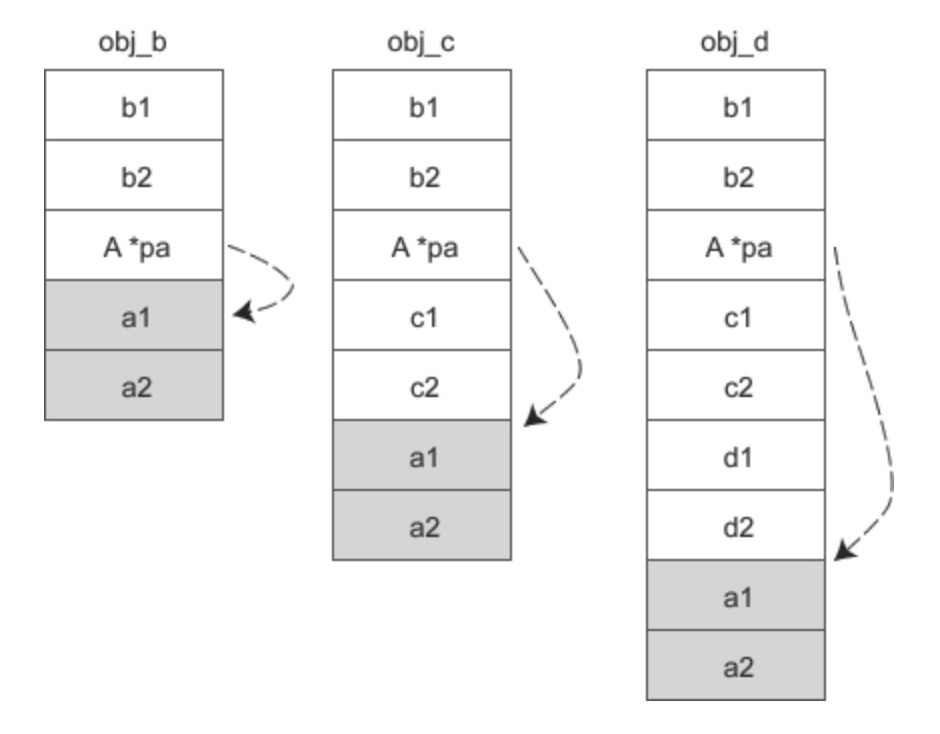 编译器会在直接派生类的对象 obj_b 中安插一个指针,指向虚基类 A 的起始位置,并且这个指针的偏移是固定的,不会随着继承层次的增加而改变。当要访问 a1、a2 时,要先通过对象指针找到 pa,再通过 pa 找到 a1、a2,这样一来就比没有虚继承时多了一层间接。
假设 p 是obj_d 的指针,现在要访问成员变量 a2:
编译器会在直接派生类的对象 obj_b 中安插一个指针,指向虚基类 A 的起始位置,并且这个指针的偏移是固定的,不会随着继承层次的增加而改变。当要访问 a1、a2 时,要先通过对象指针找到 pa,再通过 pa 找到 a1、a2,这样一来就比没有虚继承时多了一层间接。
假设 p 是obj_d 的指针,现在要访问成员变量 a2:
|
|
那么编译器内部会进行类似下面的转换:
|
|
2、如果 A 是 B 的虚基类,同时 B 也是 C 的虚基类,那么各个对象的实际内存模型如下所示:
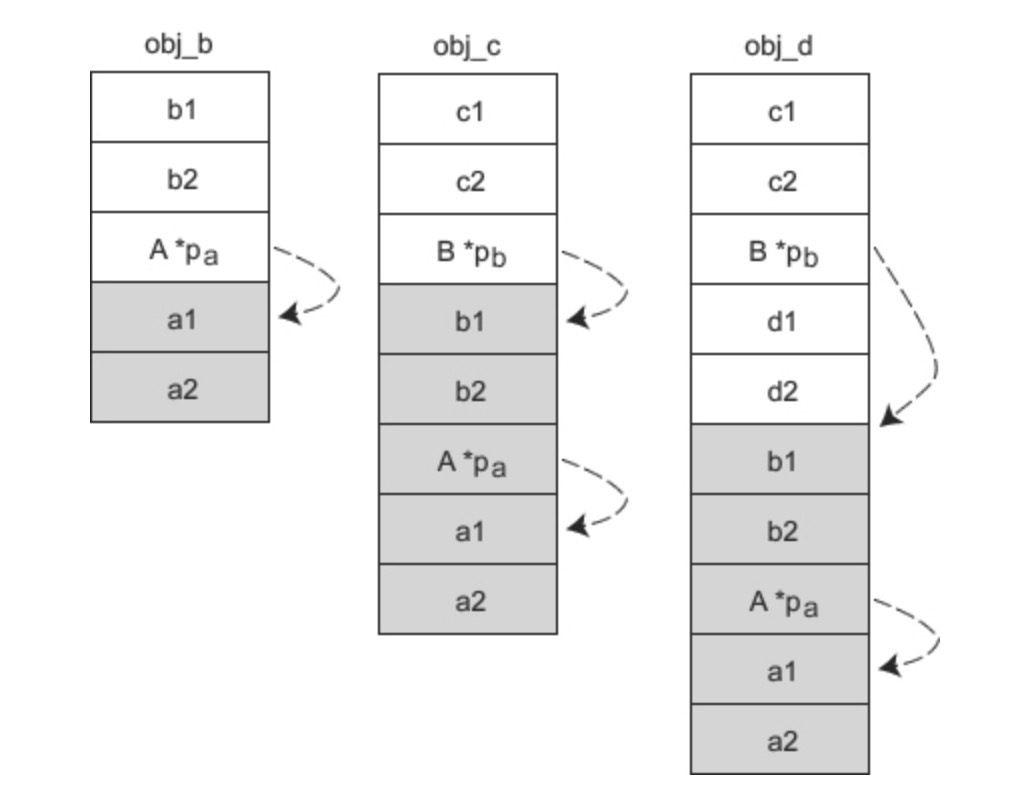 当要访问 a1、a2 时,要先通过对象指针找到 pb,再通过 pb 找到 pa,最后才能通过 pa 找到 a1、a2,这样一来就比没有虚继承时多了两层间接。
当要访问 a1、a2 时,要先通过对象指针找到 pb,再通过 pb 找到 pa,最后才能通过 pa 找到 a1、a2,这样一来就比没有虚继承时多了两层间接。
通过上面的分析可以发现,这种方案的一个缺点就是,随着虚继承层次的增加,访问顶层基类需要的间接转换会越来越多,效率越来越低。
这种方案另外的一个缺点是:当有多个虚基类时,派生类要为每个虚基类都安插一个指针,会增加对象的体积。
例如,假设 A、B、C、D 类的继承关系为:
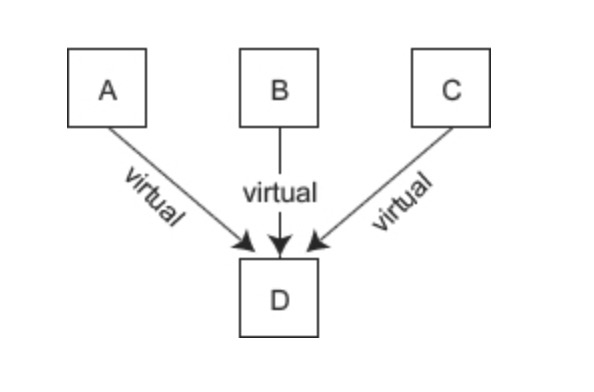 obj_d 的内存模型如下图所示:
obj_d 的内存模型如下图所示:
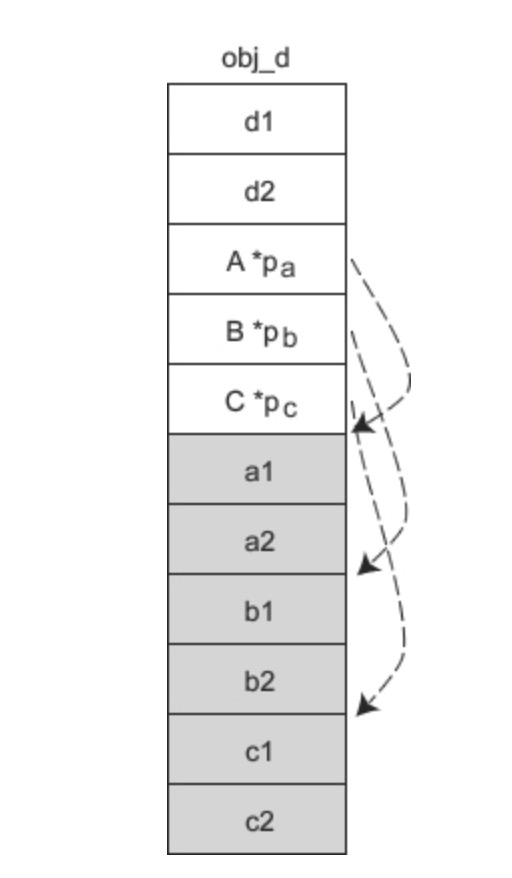 D 有三个虚基类,所以 obj_d 对象要额外背负三个指针 pa、pab、pc。
D 有三个虚基类,所以 obj_d 对象要额外背负三个指针 pa、pab、pc。
VC解决方案:
cfront 的后来者 VC 尝试对上面的方案进行了改进,一定程度上弥补了它的不足。
VC 引入了 虚基类表,如果某个派生类有一个或多个虚基类,编译器就会在派生类对象中安插一个指针,指向 虚基类表。虚基类表其实就是一个数组,数组中的元素存放的是各个虚基类的偏移。
假设 A 是 B 的虚基类,那么各对象的内存模型如下图所示:
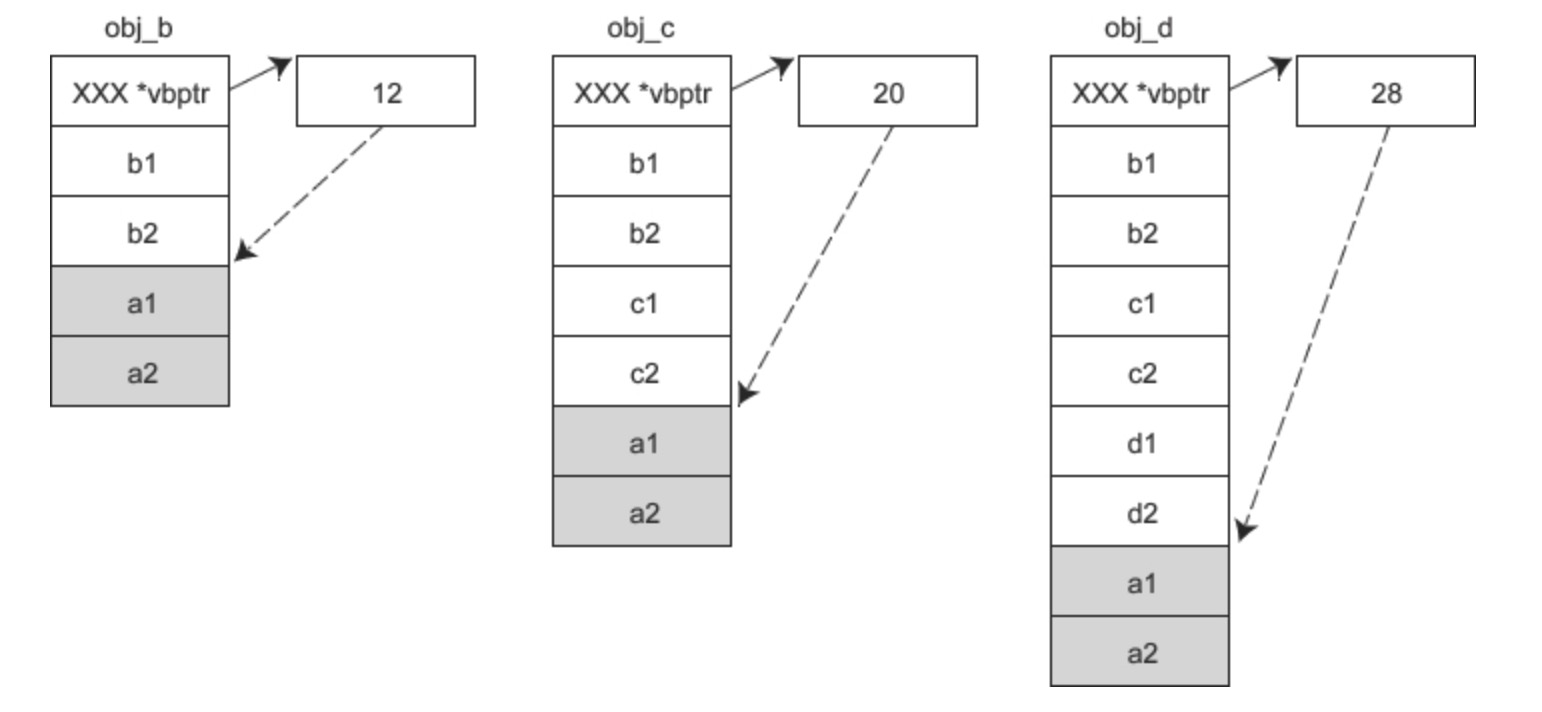 假设 A 是 B 的虚基类,同时 B 又是 C 的虚基类,那么各对象的内存模型如下图所示:
假设 A 是 B 的虚基类,同时 B 又是 C 的虚基类,那么各对象的内存模型如下图所示:
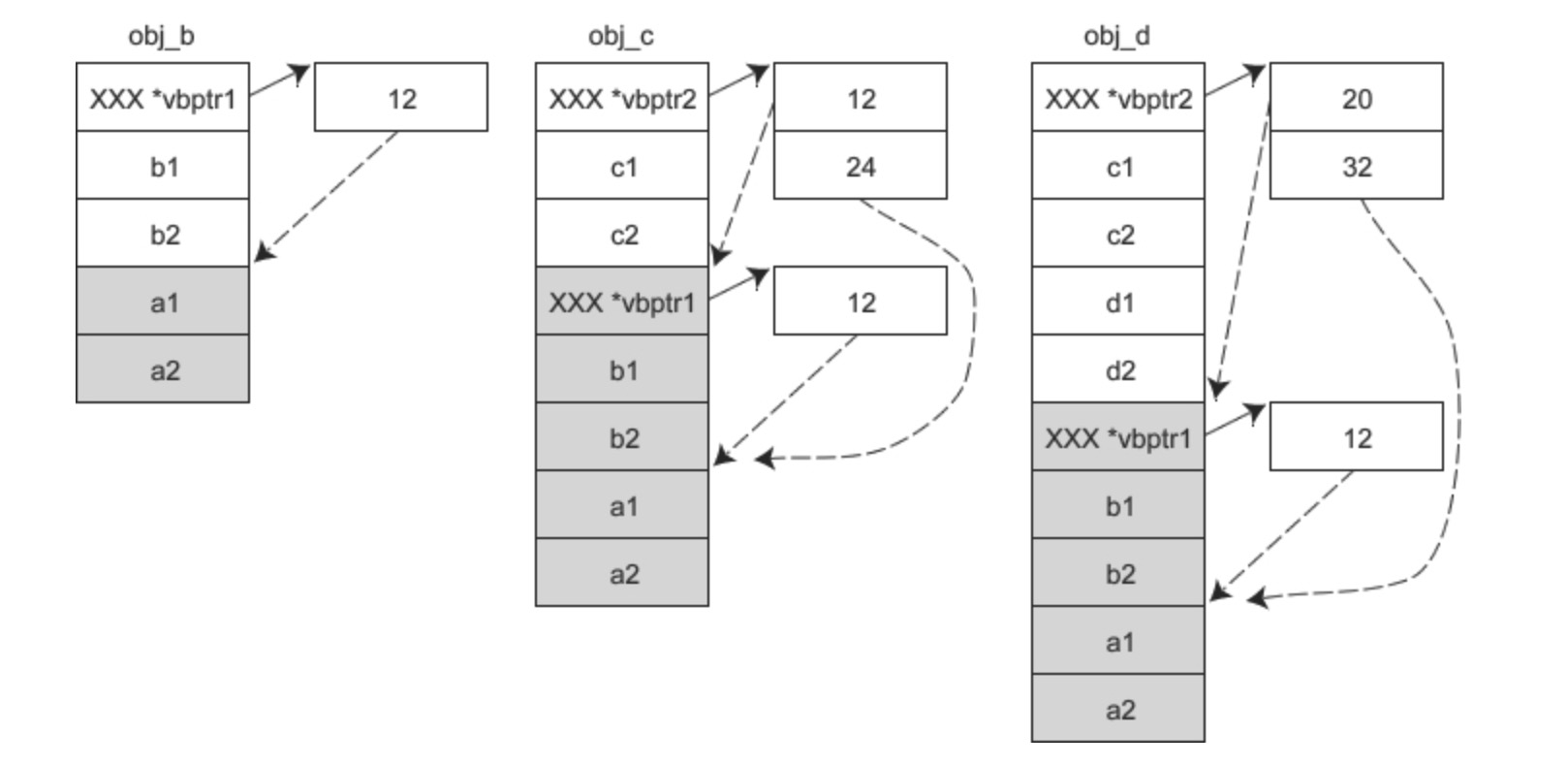 虚继承表中保存的是所有虚基类(包括直接继承和间接继承到的)相对于当前对象的偏移,这样通过派生类指针访问虚基类的成员变量时,不管继承层次都多深,只需要一次间接转换就可以。
虚继承表中保存的是所有虚基类(包括直接继承和间接继承到的)相对于当前对象的偏移,这样通过派生类指针访问虚基类的成员变量时,不管继承层次都多深,只需要一次间接转换就可以。
另外,这种方案还可以避免有多个虚基类时让派生类对象额外背负过多的指针。例如,假设 A、B、C、D 类的继承关系为:
那么 obj_d 的内存模型如下图所示:
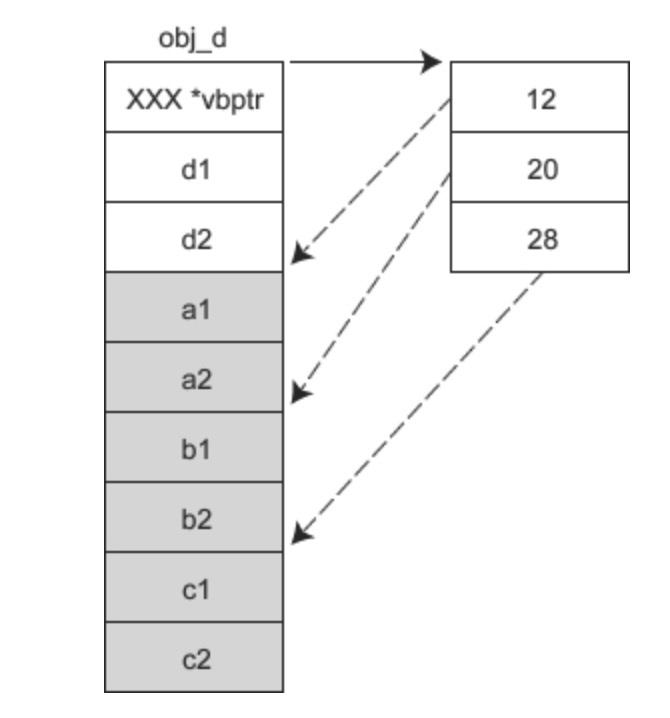 如此一来,D 类虽然有三个虚基类,但它的对象 obj_d 只需要额外背负一个指针。
如此一来,D 类虽然有三个虚基类,但它的对象 obj_d 只需要额外背负一个指针。