一、C语言函数的概念
1.1 C语言函数简介
C语言提供了一个语法功能,允许编程人员将常用的代码(往往是独立地实现了某项功能)以固定的格式封装(包装)成一个独立的模块,这个模块具有特定的名称格式、输入参数格式 和 返回格式,只要知道这个模块的名字、输入参数格式 和 输出参数(可选)格式 就可以重复使用它,这个模块就叫做 函数(Function)。
函数(Function) 是一段可以重复使用的代码,用来独立地完成某个功能,它可以接收用户传递的数据,也可以不接收。接收用户数据的函数在定义时要指明参数,不接收用户数据的不需要指明,根据这一点可以将函数分为有参函数和无参函数。
一个函数总是占用一段连续的内存区域,函数名在表达式中有时也会被转换为该函数所在内存区域的首地址。
函数的本质是一段可以重复使用的代码,这段代码被提前编写好了,放到了指定的文件中,使用时直接调取即可。
将代码段封装成函数的过程叫做 函数定义。
函数定义时给出的参数(以看做是一个占位符)称为 形式参数,简称形参;函数调用时给出的参数(也就是传递的数据)称为实际参数,简称实参。函数调用时,将实参的值传递给形参,相当于一次赋值操作。
一个程序由多个函数组成,可以理解为「一个程序由多个小的功能叠加而成」。
C语言自带的函数称为 库函数(Library Function)。库(Library)是编程中的一个基本概念,可以简单地认为它是一系列函数的集合,在磁盘上往往是一个文件夹。C语言自带的库称为 标准库(Standard Library),其它公司或个人开发的库称为 第三方库(Third-Party Library)。
除了库函数,我们还可以编写自己的函数,拓展程序的功能。自己编写的函数称为 自定义函数。自定义函数 和 库函数在编写和使用方式上完全相同,只是由不同的机构来编写。
函数不能嵌套定义:
C语言不允许函数嵌套定义;也就是说,不能在一个函数中定义另外一个函数,必须在所有函数之外定义另外一个函数。main() 也是一个函数定义,也不能在 main() 函数内部定义新函数。
标准C语言(ANSI C)共定义了15 个头文件,称为 C标准库:
- 合格程序员:<stdio.h>、<ctype.h>、<stdlib.h>、<string.h>
- 熟练程序员:<assert.h>、<limits.h>、<stddef.h>、<time.h>
- 优秀程序员:<float.h>、<math.h>、<error.h>、<locale.h>、<setjmp.h>、<signal.h>、<stdarg.h>
1.2 函数的作用域
C语言中的函数根据能否被其它源文件调用分为 内部函数 和 外部函数。
只能被本文件中其它函数调用的函数称为内部函数,内部函数也称为静态函数,用关键字static来声明。例如:
|
|
声明了一个内部函数fun(int a),该函数只能在本文件中可见。通常把只能由本文件使用的函数和外部变量放在本文件的开头用static声明,可以防止其它文件误调用,提高程序可靠性。这在多人合作编写的大型程序中非常有用。
可供其它文件调用的函数称为外部函数,用关键字extern(也可省略)来声明。例如
|
|
上述示例定义了一个外部函数。C语言中的函数默认为外部函数,因此函数定义时省略关键字extern则默认为外部函数。
Tips: 应注意的是,调用已经在其它文件中定义过的外部函数时,当前文件的开头需要加上被调用函数的 extern声明,旨在告诉编译器:该函数已经在其它文件中定义过了。例如:
|
|
文件 extern1.c 中 extern int sum(int x,int y); 语句声明 sum() 函数是已经在其它文件中定义过的函数,若没有该语句,编译器将报错:sum函数未定义就使用。
二、C语言函数调用底层实现原理分析
2.1 函数调用的实质
参考博文:
- C语言函数调用底层实现原理分析:https://www.jb51.net/article/276348.htm
- 浅谈函数调用【函数调用的底层实现逻辑】: https://blog.csdn.net/weixin_45410366/article/details/127928763
如果一个函数 A() 在定义或调用过程中出现了对另外一个函数 B() 的调用,那么我们就称 A() 为 主调函数 或主函数,称 B() 为 被调函数。
当主调函数遇到被调函数时,主调函数会暂停,CPU 转而执行被调函数的代码;被调函数执行完毕后再返回主调函数,主调函数根据刚才的状态继续往下执行。
函数是一个可以重复使用的代码块,CPU 会一条一条地顺着执行其中的代码,当遇到函数调用时,CPU 首先要记录下当前代码块中下一条代码的地址(假设地址为 0X1000),然后跳转到另外一个代码块(调用函数代码块)执行,执行完毕后再回来继续执行 0X1000 处的代码。
C语言程序执行实质上是函数的连续调用(函数 可以嵌套调用,也就是在一个函数的定义或调用过程中允许出现对另外一个函数的调用)。 运行程序时,系统通过程序入口调用main函数,在main函数中又不断调用其它函数。
栈(stack)是程序存放数据的内存区域之一,也是一种主流的数据结构,主要特征是后进先出LIFO(Last In First Out)。往栈中存入数据的过程是压入(PUSH),从栈中取出数据是弹出(POP)。栈在程序运行的过程中的主要作用是保存动态分配的自动变量,此外在函数调用时用于传递参数,以及用于保存返回地址和返回值。
程序的每个进程都包括一个 调用栈结构(Call Stack),调用栈的作用:
- 传递函数参数
- 保存返回地址
- 临时保存寄存器原有值(保存现场)
2.2 CPU寄存器分配 与 使用约定
2.1 寄存器分配
寄存器 指CPU中可以进行高速运算的缓冲区,用于存放程序执行中用到的数据和指令。
Intel 32位结构寄存器(IA32)包含8个通用寄存器,每个寄存器4个字节(32位)。 按照Intel语法,寄存器名直接按e开头(按照AT&T语法,通用寄存器名以 %e 开头)。
x86架构通用寄存器包括:
- 数据寄存器:EAX、EBX、ECX、EDX
- 变址寄存器:ESI、EDI
- 指针寄存器:EBP、ESP
X86架构中:
- EIP寄存器 指向下一条待执行的命令地址。
- ESP是栈指针寄存器,指向当前栈帧的栈顶。
- EBP是栈帧基址寄存器,指向当前栈帧的基地址。
不同架构的cpu寄存器名前缀不同。
- x86架构的寄存器用字母e作为前缀(extended),表明寄存器大小是32位。
- x86_64架构用字母r作为前缀,表明寄存器大小是64位。
ABI协议规定了寄存器、栈的使用规则以及参数传递规则。用于约束硬件与系统之间的通信协议。编译器必须按照ABI给出的寄存器功能定义,将C程序转为汇编程序。
2.2 寄存器使用约定
寄存器是唯一能被所有函数共享的资源。因此,在函数中调用其它函数时,需要考虑到数据的保存与覆盖问题(即防止被调函数直接修改寄存器导致主调函数的数据被覆盖)。
IA32采用了统一的寄存器使用约定,所有函数必须遵守:
- EAX、ECX、EDX为主调函数保存寄存器,即在调用被调函数之前,主调函数如果希望保存这三个寄存器的数据,需要将数据保存到栈中,然后调用被调函数。
- EBX、ESI、EDI是被调函数保存寄存器,被调函数如果想使用这三个寄存器,需要先将其中的数据保存到栈中,然后操作寄存器,最后将栈中的数据还原。
- EBP和ESP指向当前的栈,每个函数对应一个栈帧。被调函数在返回前,需将主调函数的栈帧还原。即恢复到调用前的状态。
2.3 栈帧结构
函数调用由栈进行处理,每个函数都单独在栈中占用一块连续的区域。这块区域叫做每个函数的栈帧。栈帧是栈的逻辑片段。 栈帧中保存 传入的参数 局部变量 和 用于返回上一栈帧的信息。 栈帧的边界由EBP和ESP决定。EBP指向栈帧的底部(高地址),ESP指向栈顶地址(低地址)。ESP可以看作是EBP的偏移量,始终指向栈帧的顶部。
- EBP为帧基指针
- ESP为栈顶指针。
三、函数调用和栈的关系
2.1 栈(stack)
栈(stack) 是程序存放数据的内存区域之一,也是一种主流的数据结构,主要特征是后进先出LIFO(Last In First Out)。往栈中存入数据的过程是压入(PUSH),从栈中取出数据是弹出(POP)。栈在程序运行的过程中的主要作用是保存动态分配的自动变量,此外在函数调用时用于传递参数,以及用于保存返回地址和返回值。
2.2 函数调用和栈的关系
下面将以 stack.c 为例,进一步了解函数调用和栈之间的关系,stack.c 的源码如下,这个示例程序中使用了递归的方法,将运行时传入的参数作为最大值,求0~n之间的整数累加值。当输入一个负数时,将count赋值为MAX,这个逻辑会导致栈溢出,报告段错误(Segmentation fault)。
|
|
函数调用前后栈的变化情况,下图中的 a 为函数调用之前的栈的状态,b 为调用 sum() 函数之后栈的状态,c 为再次调用 sum() 函数之后的栈的状态。
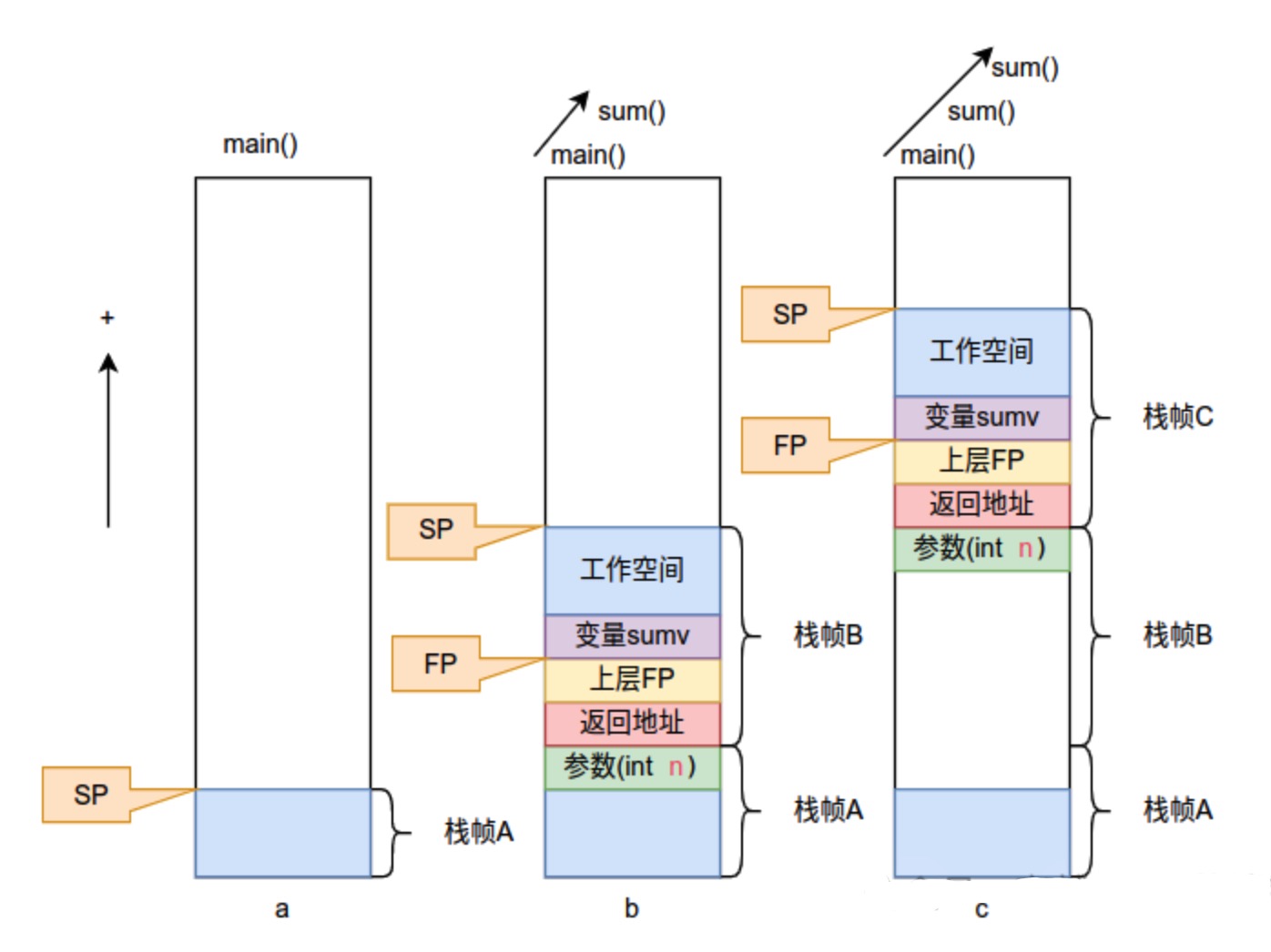
栈(stack) 上一次保存了传给函数的参数、调用者的返回地址、上层栈帧指针和函数内部使用过的自动变量。此外,处理有些函数时还会用栈来临时保存寄存器。每个函数都独自拥有这些信息,称为栈帧(stack frame)。此时需要适当地设置表示栈帧起始地址的栈指针(FP)。此外,栈指针(SP)永远指向栈顶。
在GDB 调试模式下, 使用 disassemble funtion_name 命令 可以查看相关函数汇编代码。
使用gdb也可查看栈信息,下面示例中,在sum()函数上添加了断点,传入参数运行后运行,当多次进入sum()函数时暂停执行程序,此时使用 backtrace 命令查看,看到和前面图:函数调用和栈的关系中的一致的栈信息。
|
|
使用gdb可以查看程序当前执行位置(程序计数器寄存器PC)和帧栈指针(FP),x86处理器中PC对应的寄存器是eip,FP对应的寄存器是ebp。如下示例可知,程序当前的执行位置在<sum+37>处,当前的栈桢是0xffffd3f8。
|
|
- 使用gdb操作栈桢:
使用gdb除了查看调用栈信息,也可以对栈帧进行操作。以此来增加更为丰富的调试技巧。接下来将进行栈帧操作相关命令的介绍。
首先我们将gdb停在第5个循环的sum函数中,查看调用栈信息如下所示:
|
|
通过上面示例查看不同帧下面的同一个变量sumv,他们在各自帧中的值不相同。gdb显示的是当前被选中帧上的sumv对应的值。
除了用 frame <序号> 切换当前帧,还可以使用 up 和 down 命令来上下切换帧。
使用 info 的组合命令,可以查看更加详细的栈帧信息,如下所示:
|
|
- 栈的大小
在示例程序中,定义了一个默认值MAX,这里设定了一个较大的无符号长整型(1UL « 20)。当运行程序时将负值作为参数,则会出现segmentation fault(段错误)。
此处的段错误其实是发生了栈溢出(stack overflow),接下来我们使用gdb对该错误情况进行调试,查看发生 segmentation fault 发生的时间点,通过查看程序计数器(PC)即可观察到程序的执行位置。
|
|
使用 info proc mapping 命令,可以观察到进程的内存映射信息。使用这种方式查看内存信息与Linux shell中cat /proc/
|
|
根据栈空间信息,可以得知栈空间的顶端是0xffffe000,然而,前面观察到的栈指针的值是0xff7fdff0,显然该地址超出了栈空间的范围,从而导致发生了栈溢出错误。
info proc mappings 命令实际上是gdb通过打开/proc/
示例代码中传入负值时,count被赋值为MAX,这也就意味着sum()函数会被递归调用超过一百万次以上。我们知道每次函数调用都会生成栈帧,这些栈帧都存放在栈空间中,而栈空间是有限的,在如上示例中由于栈空间的消耗超出了进程的限制范围,因而发生了栈溢出错误。