一、汇编语言简介
1.1 汇编语言简介
汇编语言 是除了机器语言外的最底层的编程语言了。学习这门语言,可以帮助我们更加深入地理解CPU、内存等硬件的工作原理、用机器的思维去操作计算机。汇编语言和机器语言是一一对应的,汇编语言被编译成机器语言,这样的程序执行效率更高。 汇编语言 是直接在硬件之上工作的编程语言,学习汇编语言之前最好先了解一下计算机硬件系统的结构和工作原理。学习汇编语言的重点是学习如何利用硬件系统的编程结构和指令集进而有效地灵活地控制系统执行工作。
机器语言 是机器指令的集合。这些机器指令本质上就是由一组0和1组成的命令,是CPU唯一能解释执行的命令。
1.2 汇编指令
汇编语言 的主体是 汇编指令,汇编指令和机器指令的差别在于指令的表示方法上,汇编指令是机器指令的助记符,汇编指令是更便于记忆的一种书写格式。它较为有效地解决了机器指令编写程序难度大的问题,汇编语言与人类语言更接近,便于阅读和记忆。使用编译器,可以把汇编程序转译成机器指令程序。
汇编语言由以下3类指令组成:
- 汇编指令(与机器指令一一对应,它是机器码的助记符)
- 伪指令(由编译器识别并执行)
- 其它符号(由编译器识别并执行)
汇编语言的核心是汇编指令,汇编指令决定了汇编程序的特性。
1.3 汇编分类
目前根据常见的指令集架构和代码风格,汇编分类如下:
- 按照指令集架构分类
- x86 架构汇编:主要用于 Intel x86 和兼容处理器的汇编语言。x86 汇编是最广泛使用的汇编语言之一,用于编写 PC、服务器和大多数个人计算机的底层代码。
- ARM 架构汇编:用于 ARM 架构处理器的汇编语言,广泛应用于移动设备、嵌入式系统和低功耗设备。
- MIPS 架构汇编:用于 MIPS 架构处理器的汇编语言,常见于嵌入式系统、网络设备和嵌入式控制器。
- 按照代码风格分类
- AT&T 语法:AT&T 语法是一种汇编语言代码风格,常用于 UNIX 系统、类UNIX系统 和 GNU 工具链,它以
movl、addl等指令表示操作符和操作数,并使用%前缀表示寄存器。 - Intel 语法:Intel 语法是另一种汇编语言代码风格,主要用于 Intel 架构和微处理器,它以
mov、add等指令表示操作符和操作数,并不使用前缀表示寄存器。
1.4 汇编语言版本
汇编语言与高级编程语言(C语言,C++,java等)都不同,不同的CPU架构对应不同的汇编版本,汇编版本主要分为3个CPU架构版本:
- X86架构的 Intel CPU:Intel X86 CPU 所采用的汇编,称为X86版本的汇编
X86架构的CPU,其实就是已经快要绝迹了的32位架构CPU,它采用的汇编指令也是X86版本的汇编。
- X86-64架构的 Intel CPU:Intel X86-64CPU 采用的汇编,称为X64版本的汇编,
X86-64架构的CPU,就是常见的64位架构CPU,它采用的汇编指令也是X86-64版本的汇编。
- ARM架构的 CPU:ARM芯片主要存在于手机端和单片机上,且在手机端已经占据了绝对统治地位,如苹果的M1,M2就是采用的ARM架构。
汇编可以说是跟CPU深度绑定,不同版本的CPU,内存地址结构也大不相同,所以它们的汇编指令也会有差异,总体来说:X86与X86-64相似,ARM独自成一套体系。
二、x86-64汇编语法基础(GNU格式)
Tips: 参考博客
- x86汇编语法基础(gnu格式):https://zhuanlan.zhihu.com/p/602680768
- 快速入门汇编语言(x86-64): https://zhuanlan.zhihu.com/p/469950256
- X86/X64的内存地址编址与寻址原理剖析: https://blog.csdn.net/u014689845/article/details/102752718/
- 汇编语言–Linux 汇编语言开发指南:https://zhuanlan.zhihu.com/p/54853591
2.1 寄存器
2.1.1 通用寄存器
通用寄存器概述:https://blog.csdn.net/weixin_45410366/article/details/127928763#t4
一个 x86-64 的中央处理单元(CPU)包含一组16个存储64位值的 通用寄存器。
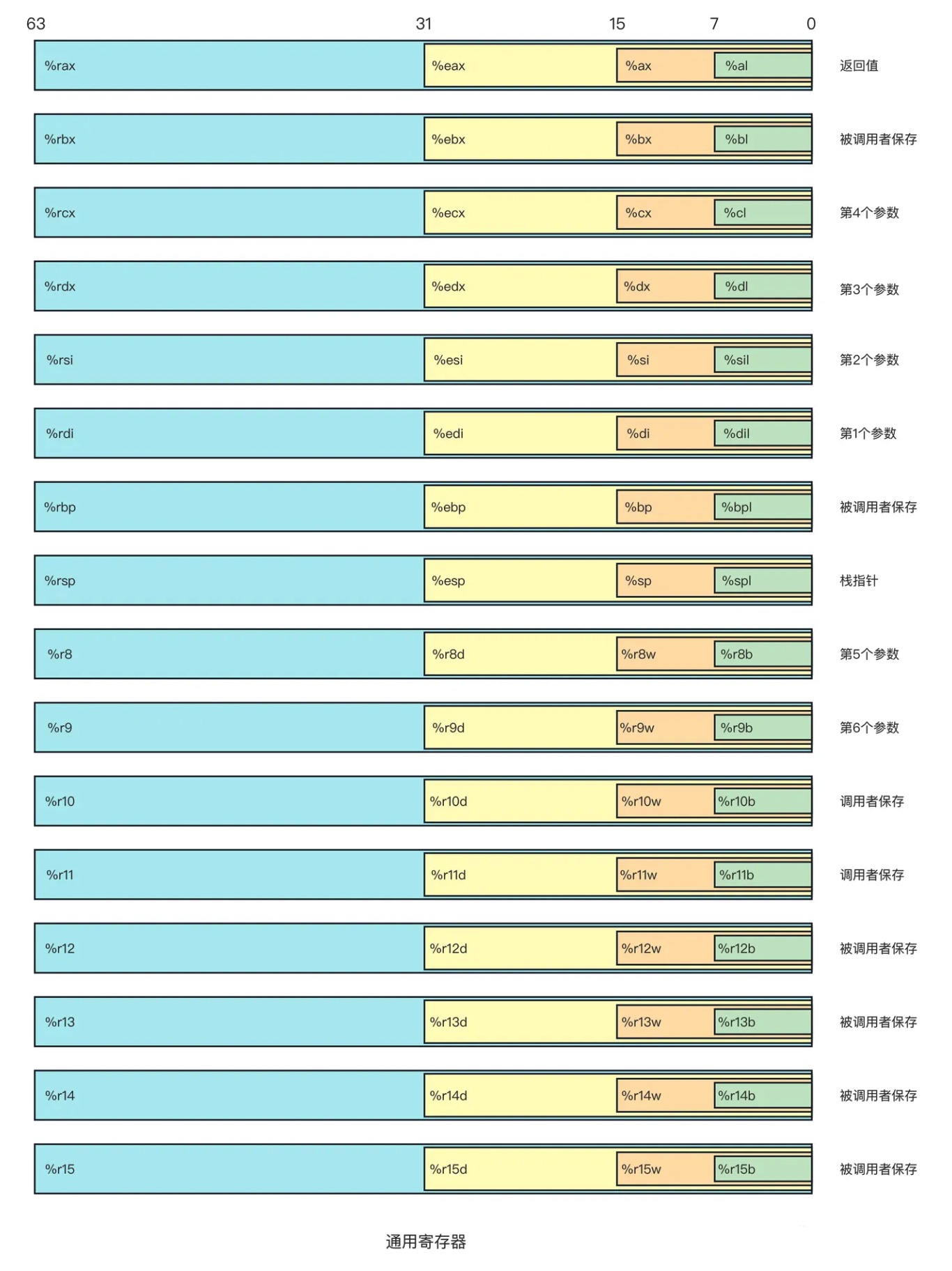 这些 通用寄存器 用来存储整数数据和指针。
这些 通用寄存器 用来存储整数数据和指针。
它们的名字都以 %r 开头,后面还跟着不同命名规则的名字,这是由于指令集历史演化造成的。
在最初的8086架构中有8个16位的寄存器,即上图中编号从 %ax 到 %bp。每个寄存器都有特殊的用途,它们的名字就反映了这些不同的用途。
扩展到IA32架构时,这些(8个)寄存器也扩展成32位寄存器,编号从 %eax 到 %ebp。
扩招到x86-64架构后,原来的8个寄存器扩展成64位,标号从%rax到%rbp。除此之外,还增加了8个新的寄存器,它们的标号是按照新的命名规则制定的:从 %r8 到 %r15。
如上图中嵌套的方框表明的,指令可以对这16个寄存器的低位字节中存放的不同大小的数据进行操作。 字节级操作 可以访问最低的字节,16位操作 可以访问最低的2个字节,32位操作 可以访问最低的4个字节,而 64位操作 可以访问整个寄存器。
Tips:当指令以寄存器作为目标时,对于生成小于8字节结果的指令,寄存器中剩下的字节如何处理,有两条规则:
- 生成1字节和2字节数字的指令会保持剩下的字节不变
- 生成4字节的指令会把高位4字节置为0。
后面这条规则是作为从IA32到x86-64的扩展的一部分而采用的。
2.1.2 标志寄存器(EFLAFS/RFLAGS)
EFLAGS标志寄存器 包含有 状态标志位、控制标志位 、 系统标志位 以及 保留位,处理器在 初始化时 将EFLAGS标志寄存器设置(赋值)为 00000002H。
下图描绘了EFLAGS标志寄存器各位的功能,其中的第1、3、5、15 以及 22~31 位保留未使用。
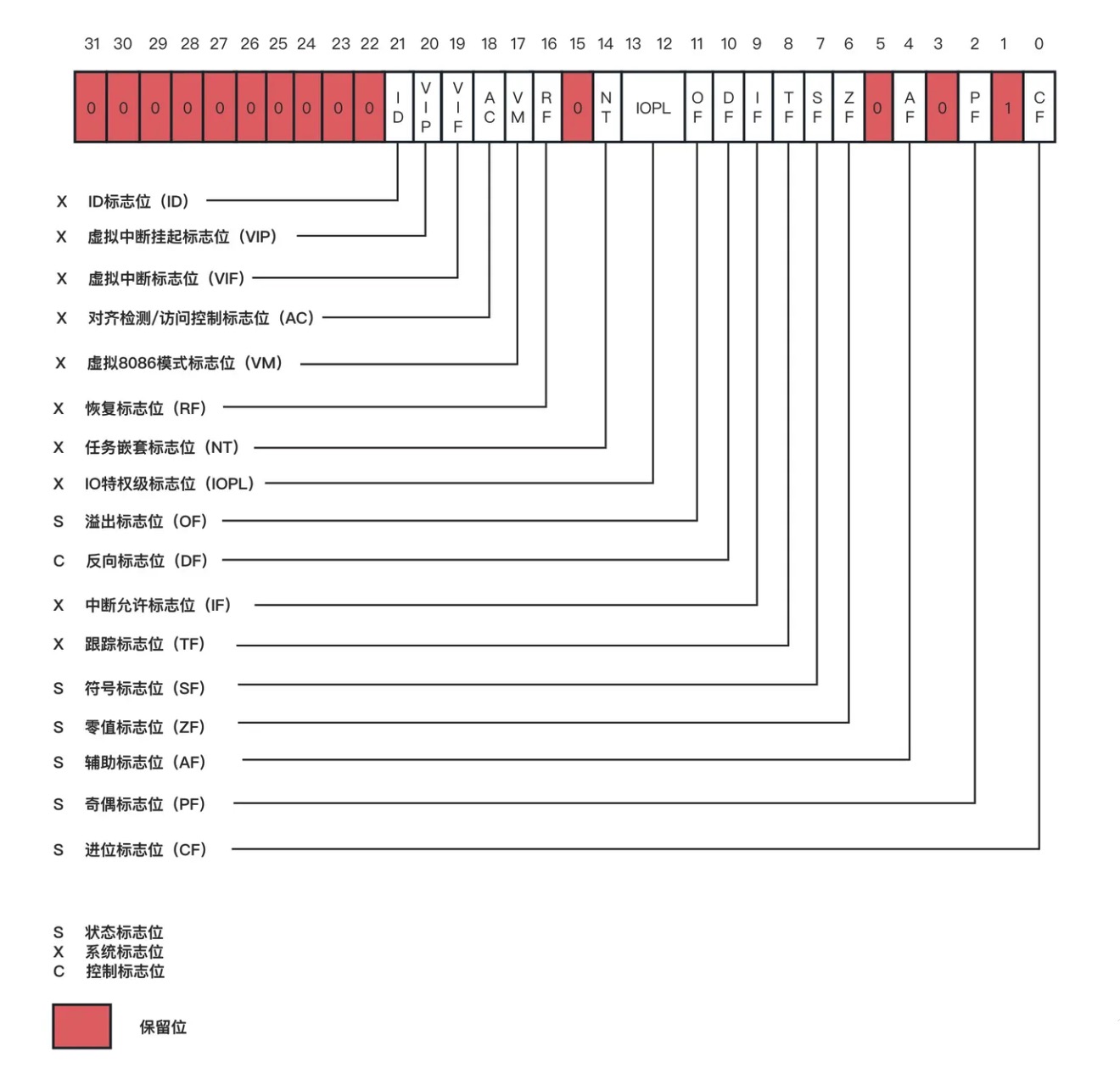
TIPs:
- 在64位模式中,EFLAGS标志寄存器已从32位扩展为64位,被称作 RFLAGS寄存器。其中高32位保留未使用,低32位与EFLAGS相同。
- 由于64位模式不再支持 VM(第17) 和 NT(第14) 标志位,所以 x86-64 处理器不应该再置位这两个标志位。
根据标志位功能将EFLAGS划分位 状态标志、方向标志、系统标志 和 IOPL区域 等几部分,各部分的标志位功能如下:
2.1.2.1 状态标志
EFLAGS标志寄存器的状态标志(位0、2、4、6、7 和 11)可以反映出汇编指令计算结果的状态,像add、sub、mul、div等汇编指令计算结果的奇偶性、溢出状态、正负值皆可从其中一个状态标志位反映出来。 状态标志的功能描述表:
| 缩写 | 全称 |
名称 | 位置 | 描述 |
|---|---|---|---|---|
| CF | Carry Flag | 进位标志 | 0 | 运算中,当数值的最高位产生了进位或者借位,CF位都会置1,否则为0。它可用于检测无符号整数运算结果是否溢出。也可用于多精度运算中。 |
| PF | Parity Flag | 奇偶标志 | 2 | 用于标记结果低8位中1的个数,如果为偶数, PF位为1,否则为0 。注意,是最低的那8位,不管操作数是16位,还是32位。奇偶校验经常用于数据传输开始时和结束后的对比,判断传输过程中是否出现错误。 |
| AF | Auxiliary Carry Flag | 辅助进位标志 | 4 | 辅助进位标志,用来记录运算结果低4位的进、借位情况,即若低半字节有进、借位,AF为1,否则为0。 |
| ZF | Zero Flag | 零值标志 | 6 | 若计算结果为0,此标志位置1,否则为0。 |
| SF | Sign Flag | 符号标志 | 7 | 若运算结果为负,则SF位为1,否则为0。 |
| OF | Overflow Flag | 溢出标志 | 11 | 用来标识计算的结果是否超过了数据类型可以表示的范围,若OF为1,表示有溢出,为0则未溢出。专门用于检测有符号整数运算结果是否溢出。 |
这些状态标志位可反映出三种数据类型的计算结果:无符号整数、有符号整数和BCD整数(Binary-coded decimal integers)。
- CF标志位可反映出无符号整数运算结果的溢出状态;
- OF标志位可反映出有符号整数(补码表示)运算结果的溢出状态;
- AF标志位表示BCD整数运算结果的溢出状态;
- SF标志位反应出有符号整数运算结果的正负值;
- ZF标志位反映出有符号或无符号整数运算的结果是否为0。
以上这些状态标志位,只有 CF标志位 可通过 stc、clc 和 cmc(Complement Carry Flag,计算原CF位的补码)汇编指令更改位的值。也可借助位操作指令(bt、bts、btr 和 btc 指令)将指定位值复制到 CF标志位。而且,CF标志位还可在多倍精度整数计算时,结合 adc指令(含进位的加法计算)或 sbb指令(含借位的减减法)将进位计算或借位计算扩展到下次计算中。
至于状态跳转指令Jcc、状态字节置位指令SETcc、状态循环指令LOOPcc以及状态移动指令CMOVcc,它们可将一个或多个状态标志位作为判断条件,进程分支跳转、字节置位以及循环计数。
2.1.2.2 方向标志
DF方向标志位(Direction Flag) 位于EFLAGS标志寄存器的第 10 位,它控制着字符串指令(诸如 movs、cmps、scas、lods、stos 等)的操作方向。置位 DF标志位 可使字符串指令按从高到低的地址方向(自减)操作数据,复位 DF标志位可使字符串指令按从低到高的地址方向(自增)操作数据。汇编指令 std 和 cld 可用于 置位 和 复位 DF方向标志。
2.1.2.3 系统标志和IOPL区域
第 8 位为TF位,即Trap Flag,意为陷阱标志位。此位若为1,用于让CPU进入单步运行方式,若为0,则为连续工作的方式。平时我们用的debug程序,在单步调试时,原理上就是让TF位为1。
第 9 位为IF位,即Interrupt Flag,意为中断标志位。若IF位为1,表示中断开启,CPU可响应外部可屏蔽中断。若为0,表示中断关闭,CPU不再响应来自CPU外部的可屏蔽中断,但CPU内部的异常还是要响应的。
第 12~13 位为 IOPL区域,即 Input Output Privilege Level,这用在有特权级概念的CPU中。有4个任务特权级,即特权级0~3,故IOPL要占用2位来表示这4种特权级。
第 14 位为NT,即 Nest Task,意为任务嵌套标志位。8088支持多任务,一个任务就是一个进程。当一个任务中又嵌套调用了另一个任务时,此NT位为1,否则为0。
64位模式不再支持VM和NT标志位,所以处理器不应该再置位这两个标志位。
第 16 位为RF位,即 Resume Flag,意为恢复标志位。该标志位用于程序调试,指示是否接受调试故障,它需要与调试寄存器一起使用。当RF为1时忽略调试故障,为0时接受。
第 17 位为VM位,即 Virtual 8086 Model,意为虚拟8086模式。
64位模式不再支持VM和NT标志位,所以处理器不应该再置位这两个标志位。
第 18 位为AC位,即 Alignment Check / Access Control,意为对齐检查。若AC位为1时,则进行地址对齐检查,位0时不检查。
第 19 位为VIF位,即 Virtual Interrupt Flag,意为虚拟终端标志位,虚拟模式下的中断标志。
第 20 位为VIP位,即 Virtual Interrupt Pending Flag,意为虚拟中断挂起标志位。在多任务情况下,为操作系统提供的虚拟中断挂起信息,需要与 VIF 位配合。
第 21 位为ID位,即 Identification Flag,意为识别标志位。系统经常要判断CPU型号,若ID位为1,表示当前CPU支持CPUID指令,这样便能获取CPU的型号、厂商信息等;若ID位为0,则表示当前CPU不支持CPUID指令。
2.1.3 段寄存器
x86-64架构,拥有6个16位段寄存器(CS、DS、SS、ES、FS 和 GS),用于保存16位段选择子。段选择子 是一种特殊的指针,用于标识内存中的段。要访问内存中的特定段,该段的段选择子必须存在于相应的段寄存器中。
在平坦内存模型中,段选择子指向线性地址空间的地址0; 在分段内存模型中,每个分段寄存器通常加载有不同的段选择子,以便每个分段寄存器指向线性地址空间内的不同分段。
每一个段寄存器表示三种存储类型之一:代码、 数据 和 栈
-
CS寄存器 保存了 代码段(code segment) 选择子,代码段存储的是需要执行的指令,处理器使用 CS寄存器 内的代码段选择子 和 RIP/EIP寄存器 的内容生成的线性地址来从代码段查询指令。 RIP/EIP寄存器 存储的是下一条要执行的指令在代码段上的偏移。
-
DS、ES、FS 和 GS寄存器 指向了四个 数据段(data segment)。
-
SS寄存器包含栈段(stack segment)的段选择子,其中存储当前正在执行的程序、任务 或 处理程序的过程 栈(stack)。
2.1.4 控制寄存器
目前,Intel处理器共拥有6个控制寄存器(CR0、CR1、CR2、CR3、CR4、CR8),它们有若干个标志位组成,通过这些标志位可以控制处理器的运行模式、开启扩展特性以及记录异常状态等功能。
2.1.5 指令指针寄存器
RIP/EIP寄存器,即 指令指针寄存器,有时称为程序计数器。指令指针(RIP/EIP)寄存器 包含当前代码段中要执行的下一条指令的偏移量。
2.1.6 MSR寄存器组
MSR(Model-Specific Register)寄存器组 可提供性能监测、运行轨迹跟踪与调试以及其它处理器功能。在使用MSR寄存器组之前,我们应该通过CPUID.01h:EAX[5]来检测处理器是否支持MSR寄存器组。处理器可以使用RDMSR和WRMSR对MSR寄存器组进行访问,整个访问过程借助ECX寄存器索引寄存器地址,再由EDX:EAX组成的64位寄存器保持访问值。
tips: 在处理器支持64位模式下,RCX、RAX和RDX寄存器的高32位将会被忽略。
2.2 指令集
#TODO :大学时学的汇编是一锅未曾开火煮的生米饭,等什么时候开火重新煮…
2.3 汇编指令操作对象
在汇编语言中,指令的操作对象可以是以下几种类型:
- 寄存器(Registers):寄存器是位于CPU内部的高速存储器,用于存储和处理数据。不同的CPU架构有不同的寄存器集合,例如x86架构中的通用寄存器(如EAX、EBX等),浮点寄存器(如XMM0、XMM1等)等。指令可以直接对寄存器进行操作,如将数据加载到寄存器、在寄存器之间进行数据传输、对寄存器进行算术操作等。
- 内存(Memory):内存是计算机中用于存储数据和指令的主要存储器。在汇编语言中,可以使用内存地址来引用内存中的数据。指令可以通过内存地址来读取或写入数据。例如,可以将数据从内存加载到寄存器中进行操作,或将寄存器中的数据存储回内存。
- 立即数(Immediate Values):立即数是指令中直接给出的常数值。它可以用作指令的操作数,用于进行算术操作或与其它操作数进行比较。立即数通常以特定的格式表示,例如整数、浮点数、十六进制数等。
- 标志寄存器(Flags Register):标志寄存器是存储特定标志位的寄存器,用于记录先前指令的运算结果或系统状态。标志寄存器中的标志位可以影响指令的执行流程或条件跳转的判断。例如,ZF(零标志位)用于指示上一次运算结果是否为零,CF(进位标志位)用于指示上一次算术运算是否产生进位。
这些操作对象可以被汇编指令直接引用和操作,允许对数据进行加载、存储、移动、算术运算、逻辑运算、比较等操作。具体可操作的对象和指令的功能取决于具体的汇编语言和所使用的CPU架构。
三、Linux下常见的反汇编工具
3.1 nm 命令
nm(name list)是一个命令行工具,用于显示二进制文件中的符号表信息。它在Linux和其它类Unix操作系统上可用。nm工具的主要作用是列出目标文件或可执行文件中定义的符号和外部引用的符号。它可以显示函数、变量、常量以及其它符号的名称和相关信息。以下是nm工具的一些常见用途和功能:
- 列出符号表:nm工具可以用来查看目标文件或可执行文件的符号表。它会列出定义的符号以及它们的地址、类型和其它属性。这对于了解代码中使用的符号以及它们的定义和引用非常有用。
- 检查函数和变量的可见性:通过查看符号表,nm可以显示函数和变量的可见性。它可以告诉您哪些符号是全局可见的(global visibility),哪些是局部的(local visibility),以及哪些符号是未定义的(undefined)。
- 调试和故障排除:nm工具可以在调试和故障排除过程中提供有关符号的信息。它可以帮助您确定函数或变量是否已正确定义和链接,以及是否存在重复定义或未解析的符号等问题。
- 进行符号解析:在某些情况下,nm工具可以用于解析符号的名称。它可以帮助您找到特定符号在二进制文件中的位置,以便进行进一步的分析和调试。
nm工具的使用方式为:nm [options] <filename>,常见的选项包括 -a(显示所有符号,包括局部符号)、-g(只显示全局符号)、-u(只显示未定义的符号)等,参数选项可查看help。
通过使用nm工具,您可以深入了解目标文件或可执行文件中的符号信息,以及它们的定义、引用和可见性。这对于软件开发和调试非常有用。
3.2 readelf 命令
readelf 是一个强大的命令行工具,用于查看和分析ELF文件的内容。它提供了多个选项和功能,可以查看文件头、节表、符号表、动态链接信息等。以下是readelf的使用方法:
|
|
3.3 objdump 命令
objdump 是另一个功能强大的命令行工具,用于查看二进制文件的信息。它可以显示ELF文件的汇编代码、符号表、重定位表等。以下是一些常用的 objdump 命令示例:
|
|
3.4 xxd 命令
xxd 是一个强大的十六进制查看工具,它可以以十六进制和ASCII码的形式显示文件的内容。它还提供了反向操作,可以将十六进制数据转换回二进制文件。要使用 xxd,你可以在终端中运行以下命令:
|
|
这将以默认格式显示文件的十六进制内容,也可以使用不同的命令选项来定制输出格式。
3.5 hexdump 命令
hexdump 是另一个常用的命令行工具,用于以十六进制和ASCII码的形式显示文件的内容。它可以提供更多的格式选项,并且支持从标准输入或指定的文件中读取数据。以下是一个使用 hexdump的示例命令:
|
|
这将以类似于xxd的格式显示文件的内容。
四、反汇编
4.1 反汇编简介
汇编语言难以被理解,但可以通过反汇编,将其变得易理解一些,如上面 第三节 所述,可以通过多种工具和方法来查看程序的汇编代码。
此外在调试 core dump 或 Kernel dump 时,也可以使用 gdb 等调试工具查看反汇编之后的汇编代码。调试的最终目的还是需要再 c/c++语言 等源代码中找出问题所在。
汇编语言与CPU的寄存器以及机器语言有很大的关联,关于寄存器的内容可以参考:https://mp.weixin.qq.com/s/Okx4IipFMzWZvT6h6tNfvA
下面将通过 assemble.c 示例来演示这些工具的使用和学习汇编语言的一些技巧。
|
|
以上示例代码 assemble.c 中设定了一些容易解读的内容,包含了各类变量、if、while、for等语句和函数调用等功能。
4.2 反汇编代码
使用下面指令将 assemble.c 编译为 assemble程序,再使用 objdump 工具反汇编,为了让反编译的汇编代码更容易理解,编译时禁用了优化选项(-O0:横线、字母O、数字0),objdump 选项 --no-show-raw-insn:禁止显示原始指令的字节码,使反汇编结果中不输出机器语言。
|
|
对比 assemble.c 中 源码和 objdump 反汇编后的代码,可以很快定位上述c代码中常见的逻辑在汇编语言中的表示方式。为了方便理解,对部分汇编代码添加注释。通过阅读汇编代码,可以清晰的了解机器指令的执行过程。